
Dialog as a Service gRPC API
DLGaaS allows conversational AI applications to interact with Mix dialogs
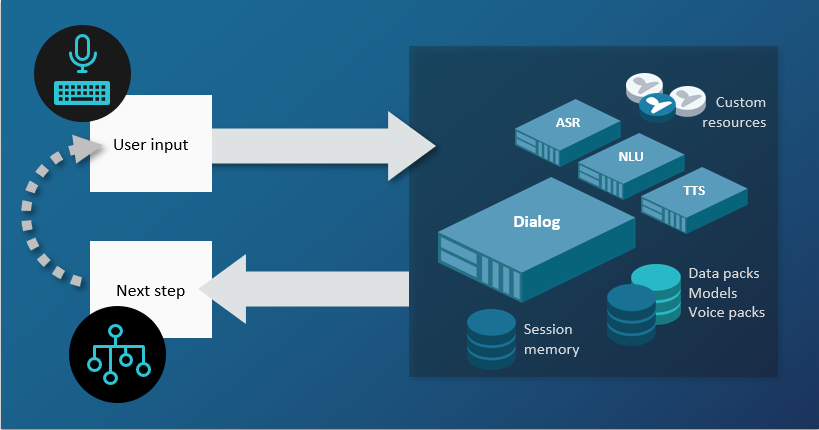
Dialog as a Service is Nuance's omni-channel conversation engine. The Dialog as a Service API allows client applications to interact with conversational agents created with the Mix.dialog web tool. These interactions are situated within a cohesive conversational session that keeps track of the ongoing context of the conversation, similar to what we do during the back and forth of a conversation with a person.
The gRPC protocol provided by Dialog as a Service allows a client application to interact with a dialog in all the programming languages supported by gRPC.
gRPC is an open source RPC (remote procedure call) software used to create services. It uses HTTP/2 for transport and protocol buffers to define the structure of the application. Dialog as a Service supports the gRPC proto3 version.
Version: v1
This release supports version v1 of the Dialog as a Service protocol. See gRPC setup to download the proto files and get started.
Dialog essentials
From an end-user's perspective, a dialog-enabled app is one that understands natural language, can respond in kind, and, where appropriate, can extend the conversation by following up the user's turn with appropriate questions and suggestions, all the while maintaining a memory of the context of what happened earlier in the conversation.
Dialogs are created using Mix.dialog; see Creating Mix.dialog Applications for more information. This document describes how to access a dialog at runtime from a client application using the DLGaaS gRPC API.
This section introduces concepts that you will need to understand to write your client application.
What is a conversation?
The flow of the DLGaaS API is based around the metaphor of a conversation between two parties. Specifically, with DLGaaS, this is a conversation between one human user—who enters text and speech inputs through some sort of client app UI—and a Dialog agent running on a server. Specifically, the API allows an interface between a client app and the Dialog agent. The model here is a conversation between a person and an agent from an organization or company that a person might want to contact.
Similar to a person dealing with a human agent, the human user is assumed to have some purpose in the conversation. They will come to the conversation with an intent, and the goal of the agent is to help understand that intent and help the person achieve it. The person might also introduce a new intent during the conversation.
To understand how the flow of the API works, it helps to reflect for a moment on what is a conversation. In its simplest form, a conversation is a series of more or less realtime exchanges between two people over a period of time. People take turns speaking, and communicate with each other in a back-and-forth pattern.
Structure of a conversation
Taken a little abstractly, a conversation between a user and a Dialog agent could look like this:
- Some formalities at the start to establish communications, agree to have a conversation, and establish resources to keep track of the conversation.
- Once the formalities are done, the user signals to the Dialog agent a desire to begin, and the agent replies to start off the conversation.
- They continue through a few rounds of back and forth where the user says something or provides some requested data, the Dialog agent processes this, and responds to carry on the dialog flow.
- This process continues until either the user or the Dialog agent ends the conversation.
What this looks like in the API
In the Dialog client runtime API, you use a Start request to establish a conversation. This creates a session on the Dialog side to hold the conversation and any resources it needs for a set timeframe.
The dialog proceeds in a series of steps, where at each step, the client app sends input from the user and possibly data, and the Dialog agent responds by sending informational messages, prompts for input, references to files for the client to use or play, or requests to the client for data. The way this works depends on the type of input:
- For text input, each step is is triggered by an Execute request from the client app.
- When there is audio input, each step is triggered by a series of ExecuteStream requests from the client app streaming the input audio.
- When the previous step Execute response included a request for the client app to look up and return data, the next cycle is triggered by an Execute request from the client app that includes the requested data.
- When the previous Execute response included messages and instructions to play to the user while a server-side data access is taking place, the client app has nothing to return, so the next cycle is triggered by an empty Execute request from the client app.
The flow of the API is structured around steps of user input, followed by the agent response. The agent's response at any step is a reply to the client input in the same step. But remember also that in conversations with some sort of agent, be it human or virtual, the agent also generally drives or steers the conversation. For example, opening the interaction with, "Welcome to our store. How may I help you?" In Mix.dialog, you create a dialog flow, and the conversation is driven by this flow.
By convention, an agent will generally start off the conversation and then continue to direct the flow of the conversation toward getting any additional information needed to fulfill the user's request. As well, when a user gives input, it is generally in response to something asked for in the previous step of the conversation by the agent. And when data is sent in a step, it is a response to a request for data in the previous step.
At the start of the conversation, the client app needs a way to "poke" the API to reply with the initial greeting prompts, but without sending any input. The API enables you do this by sending a first Execute request with an empty payload. This causes the Dialog agent to respond with its standard initial greeting prompts, and the conversation is underway.
See Client app development for a more detailed description of how to access and use the API to carry out a conversation.
Session
A session represents an ongoing conversation between a user and the Dialog service for the purpose of carrying out some task or tasks, where the context of the conversation is maintained for the duration. For example, consider the following scenario for a coffee app:
- Service: Hello and welcome to the coffee app! What can I do for you today?
- User: I want a cappuccino.
- Service: OK, in what size would you like that?
- User: Large.
- Service: Perfect, a large cappuccino coming up!
A session is started by the client, and ends when the natural flow of the conversation is complete or the session times out.
The length of a session is flexible, and can can handle different types of dialog, from a short burst of interaction to carry out one task for a user, or a series of interactions carrying out multiple tasks over an extended period of time.
Session ID
The interactions between the client application and the Dialog service for this scenario occur in the same session. A session is identified by a session ID. Each request and response exchanged between the client app and the Dialog service for that specific conversation must include that session ID referencing the conversation, and its context. If you do not provide a session ID, a new session is created and you are provided with a new session ID.
Session context
A session holds a context of the history of the conversation. This context is a memory of what the user said previously and what intents were identified previously. The context improves the performance of the dialog agent in subsequent interactions by giving additional hints to help with interpreting what the user is saying and wants to do. For example, if someone has just booked a flight to Boston, and then asks to book a hotel, it is quite likely the person wants to book a hotel in the Boston area, starting the same day as the flight arrives.
The session context is maintained throughout the lifetime of the session and added to as the conversation proceeds.
Session lifetime
A session's length in time is bounded by a session timeout limit, after which an idle session terminates if not already closed by the conclusion of the natural dialog flow.
Configure session lifetime
This limit is configurable up to a maximum of 259200 seconds or 72 hours (default of 900 seconds) and can be set at the start of the dialog using the Start method.
For more information on session IDs and session timeout values, see Step 3. Start conversation.
Check remaining session lifetime
Using the session ID, a client application can check whether the session is still active and get an estimate of how much time is left in the session using the Status method. For more information, see Step 5. Check session status.
Reset session time remaining
For asynchronous channels, you may want or need to keep the session going for longer than the upper limit. The client application can reset the time remaining in the session to the original limit by using either the Execute, ExecuteStream, or Update method.
If you simply want to reset the time remaining to keep the session alive without otherwise advancing the conversation, send an UpdateRequest specifying the session ID but with the payload left empty. For more information, see Step 6. Update session data.
Session data
Each session has memory designated to hold data related to the session. This includes contextual information about the user inputs during the session as well as session variables.
Session variables
Variables of different types can be used to hold data needed during a session. Dialog includes several useful predefined variables. You can also create new user-defined variables of various types in Mix.dialog.
For both predefined and user-defined variables, values can be assigned:
- In Mix.dialog when the dialog is defined
- Through data transfers from the client app or from external systems
Different variable types have their respective access methods defined, allowing you to retrieve variable values and components of those values in Mix.dialog. This allows you to define conditions, create dynamic messages content, and make assignments to other variables.
Assigning variables through data transfer
In some situations, you may want to send variables data from the client application to the Dialog service to be used during the session. For example, at the beginning of a session, you might want to send the geographical location of the user, the user name and phone number, and so on. You might also want to update the same values mid-session. As well, data transfers can be used during the session to provide wordsets specifying the relevant options for dynamic list entities.
Note: You can only assign values for variables that have already been defined in Mix.dialog, whether predefined or user-defined.
For more information, see Exchanging session data.
Session data lifetime
Values for variables stored in the session persist for the lifetime of the session or until the variable is updated or cleared during the session.
Playing messages and providing user input
The client application is responsible for playing messages to the user (for example, "What can I do for you today?") and for collecting and returning the user input to the Dialog service (for example, "I want a cappuccino").
Messages can be provided to the user in the form of:
- Text to be rendered using text-to-speech (TTS); this text can be generated directly through the DLGaaS API
- Text to be visually displayed, for example, in a chat
- Audio file to be played the the user
The client app can then send the user input to the Dialog service in a few ways:
- As audio to be recognized and interpreted by Nuance.
- As text to be interpreted by Nuance. In this case, the client application returns the input string to the dialog application.
- As interpretation results. This assumes that interpretation of the user input is performed by an external system. In this case, the client application is responsible for returning the results of the interpretation to the dialog application.
- As a selected item chosen by the user.
Orchestration with other Mix services
To support the Dialog service, different natural language and speech tasks will generally be required, depending on the channels your application is using and the types of input you are dealing with. You may need one or more of the following:
- Natural language understanding: For text inputs, taking in a text string and interpreting the intent of the sentence and any entities
- Speech recognition: For speech inputs, taking in speech audio and returning a text transcription
- Text to speech: For speech applications, taking in a text script and for the dialog response and returning this to the user as synthesized speech audio
The Dialog service does not itself perform these tasks but relies on other services to carry them out.
The Mix platform offers a set of Conversational AI services to handle these tasks:
- NLUaaS: For natural language understanding
- ASRaaS: For speech recognition
- TTSaaS: For generating text-to-speech
Your client application can handle these tasks either with the Mix services, or by using third party services.
Dialog service offers the possibility of special integration when using Mix services. Properly formatted requests sent to DLGaaS will automatically trigger calls to other Mix services. Rather than needing to separately call the other Mix services, Dialog can orchestrate with the other Mix services behind the scenes as follows. The Dialog service:
- Prepares and forwards a request to the specific Mix service
- Receives the response from the Mix service
- Prepares and forwards this response to the client application bundled as part of the standard DLGaaS response to the initial DLGaaS request
For orchestrated ASRaaS and TTSaaS requests, the DLGaaS service supports streaming of the audio input/output in both directions.
For more details about how to format inputs to trigger orchestration with Mix services, see Client app development.
Alternatively, if you prefer, you can directly handle the orchestration with the other Mix services or even third party tools rather than leaving it to Dialog.
Nodes and actions
Mix.dialog nodes that trigger a call to the DLGaaS API
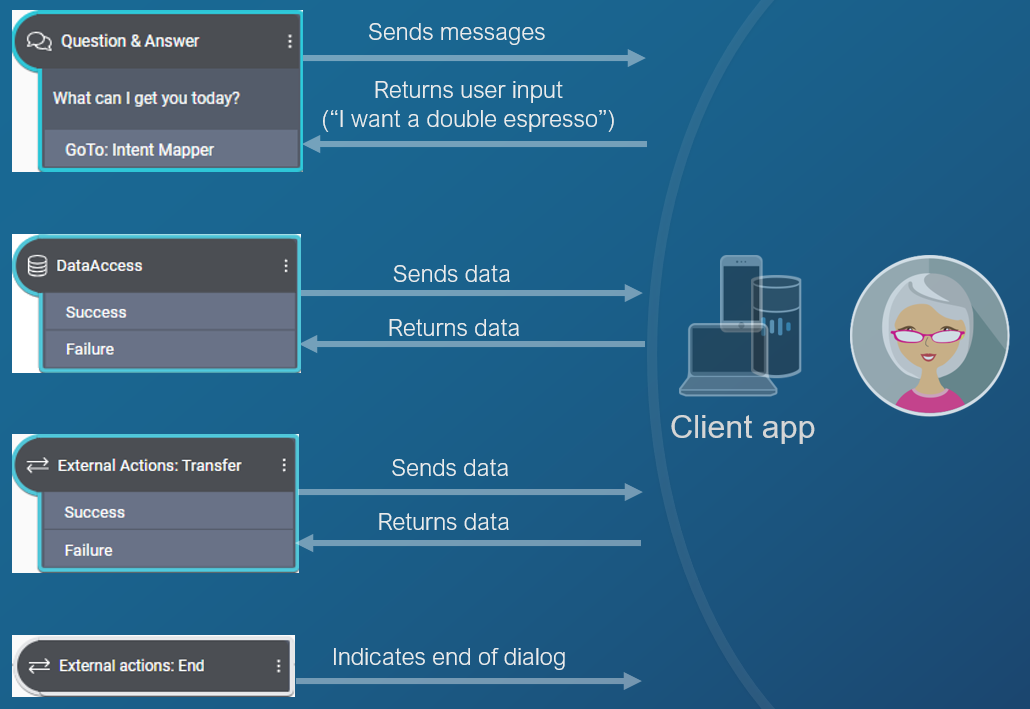
You create applications in Mix.dialog using nodes. Each node performs a specific task, such as asking a question, playing a message, and performing recognition. As you add nodes and connect them to one another, the dialog flow takes shape in the form of a graph.
At specific points in the dialog, when the Dialog service requires input from the client application, it sends an action to the client app. In the context of DLGaaS, the following Mix.dialog nodes trigger a call to the DLGaaS API and send a corresponding action:
Question and answer
The objective of the question and answer node is to collect user input. It sends a message to the client application and expects user input, which can be speech audio, a text utterance, or a natural language understanding interpretation. For example, in the coffee app, the dialog may tell the client app to ask the user "What type of coffee would you like today" and then to return the user's answer.
The message specified in a question and answer node is sent to the client application as a question and answer action. To continue the flow, the client application must then return the user input to the question and answer node.
See Question and answer actions for details.
Data access
A data access node expects data from a data source to continue the flow. The data source can either be a backend server or the client app, and this is configurable in Mix.dialog. For example, in a coffee app, the dialog may ask the client application to query the price of the order or to retrieve the name of the user.
When Mix.dialog is configured for client-side data access, information is sent to the client application in a data access action, identifying what data the Dialog service needs and providing any input data needed to retrieve that information. It also provides information to help the client application smooth over any delays while waiting for the data access. To continue the flow, the client application must return the requested data to DLGaaS.
See Data access actions for details.
When Mix.dialog is configured for server-side backend data access, DLGaaS sends the client application a continue action and awaits a response before proceeding with the data access. The continue action provides information to help the client application smooth over any delays waiting on the DLGaaS communicating with the server backend. To continue the flow, the client application must respond to DLGaaS.
See Continue actions for details.
External actions: Transfer and End
There are two types of external actions nodes:
- Transfer: This node triggers an escalation action to be sent to the client application; it can be used, for example, to escalate to an IVR agent. It sends data to the client application. To continue the flow, the client application must return a
returnCode, at a minimum. See Transfer actions for details. - End: This node triggers an end action to indicate the end of the dialog application. It does not expect a response from the client app. See End actions for details.
Message node
The message node plays a message. The message specified in a message node is sent to the client application as a message action.
See Message actions for details.
Selectors
Most dialog applications can support multiple channels and languages, so you need to select which channel and language to use for an interaction in your API. This is done through a selector.
Selectors can be sent as part of a:
- StartRequest
- ExecuteRequest, whether a standalone ExecuteRequest or as part of a StreamInput
A selector is the combination of:
- The channel through which messages are transmitted to users, such as an IVR system, a live chat, a chatbot, and so on. The channels are defined when creating a Mix project.
- The language to use for the interactions.
- The library to use for the interaction. (Advanced customization reserved for future use. Use the default value for now, which is
default.)
You do not need to send the selector at each interaction. If the selector is not included, the values of the previous interaction will be used.
Prerequisites from Mix
Before developing your gRPC application, you need a Mix project that provides a dialog application as well as authorization credentials.
- Create a Mix project:
- Create a Mix.dialog application, as described in Creating Mix.dialog Applications.
- Build your dialog application.
- Set up your application configuration.
- Deploy your application configuration.
- Generate a "secret" and client ID of your Mix project: see Authorize your client application. Later you will use these credentials to request an access token to run your application.
- Learn the URL to call the Dialog service: see Accessing a runtime service.
- For DLGaaS, this is:
dlg.api.nuance.co.uk:443
- For DLGaaS, this is:
gRPC setup
Install gRPC for programming language, e.g. Python
$ pip install --upgrade pip
$ pip install grpcio
$ pip install grpcio-tools
Unzipped proto files
├── Your client apps here
├── nuance_dialog_dialogservice_protos_v1.zip
└── nuance
├── dlg
│ └── v1
│ ├── common
│ │ └── dlg_common_messages.proto
│ ├── dlg_interface.proto
│ └── dlg_messages.proto
│
├── asr
│ └── v1
│ ├── recognizer.proto
│ ├── resource.proto
│ └── result.proto
│
├── tts
│ └── v1
│ └── nuance_tts_v1.proto
├── nlu
│ └── v1
│ ├── interpretation-common.proto
│ ├── multi-intent-interpretation.proto
│ ├── result.proto
│ ├── runtime.proto
│ └── single-intent-interpretation.proto
└──rpc
├── error_details.proto
├── status.proto
└── status_code.proto
For Python, use protoc to generate stubs
$ echo "Pulling support files"
$ mkdir -p google/api
$ curl https://raw.githubusercontent.com/googleapis/googleapis/master/google/api/annotations.proto > google/api/annotations.proto
$ curl https://raw.githubusercontent.com/googleapis/googleapis/master/google/api/http.proto > google/api/http.proto
$ echo "generate the stubs for support files"
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ google/api/http.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ google/api/annotations.proto
$ echo "generate the stubs for the DLGaaS gRPC files"
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ --grpc_python_out=./ nuance/dlg/v1/dlg_interface.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/dlg/v1/dlg_messages.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/dlg/v1/common/dlg_common_messages.proto
$ echo "generate the stubs for the ASRaaS gRPC files"
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ --grpc_python_out=. nuance/asr/v1/recognizer.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/asr/v1/resource.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/asr/v1/result.proto
$ echo "generate the stubs for the TTSaaS gRPC files"
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ --grpc_python_out=./ nuance/tts/v1/nuance_tts_v1.proto
$ echo "generate the stubs for the NLUaaS gRPC files"
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ --grpc_python_out=./ nuance/nlu/v1/runtime.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/nlu/v1/result.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/nlu/v1/interpretation-common.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/nlu/v1/single-intent-interpretation.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/nlu/v1/multi-intent-interpretation.proto
$ echo "generate the stubs for supporting files"
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/error_details.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/status.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/status_code.proto
Final structure of protos and stubs for DLGaaS files after unzip and protoc compilation
├── Your client apps here
├── nuance_dialog_dialogservice_protos_v1.zip
└── nuance
├── dlg
│ └── v1
│ ├── common
│ │ ├── dlg_common_messages.proto
│ │ └── dlg_common_messages_pb2.py
│ ├── dlg_interface.proto
│ ├── dlg_interface_pb2.py
│ ├── dlg_interface_pb2_grpc.py
│ ├── dlg_messages.proto
│ └── dlg_messages_pb2.py
│
├── asr
│ └── v1
│ ├── recognizer_pb2_grpc.py
│ ├── recognizer_pb2.py
│ ├── recognizer.proto
│ ├── resource_pb2.py
│ ├── resource.proto
│ ├── result_pb2.py
│ └── result.proto
│
├── tts
│ └── v1
│ ├── nuance_tts_v1.proto
│ ├── nuance_tts_v1_pb2.py
│ └── nuance_tts_v1_pb2_grpc.py
├── nlu
│ └── v1
│ ├── interpretation_common_pb2.py
│ ├── interpretation-common.proto
│ ├── multi_intent_interpretation_pb2.py
│ ├── multi-intent-interpretation.proto
│ ├── result.proto
│ ├── result_pb2.py
│ ├── runtime.proto
│ ├── runtime_pb2.py
│ ├── runtime_pb2_grpc.py
│ ├── single_intent_interpretation_pb2.py
│ └── single-intent-interpretation.proto
└──rpc
├── error_details.proto
├── error_details_pb2.py
├── status.proto
├── error_details_pb2.py
├── status_code.proto
└── status_code_pb2.py
The basic steps in using the Dialog as a Service gRPC protocol are:
- Install gRPC for the programming language of your choice, including C++, Java, Python, Go, Ruby, C#, Node.js, and others. See gRPC Documentation for a complete list and instructions on using gRPC with each language.
- Download the zip file containing the gRPC .proto files for the Dialog service. These files contain a generic version of the functions or classes that can interact with the dialog service.
See Note about packaged proto files below. - Unzip the file in a location that your applications can access, for example in the directory that contains or will contain your client apps.
- Generate client stub files in your programming language from the proto files. Depending on your programming language, the stubs may consist of one file or multiple files per proto file. These stub files contain the methods and fields from the proto files as implemented in your programming language. You will consult the stubs in conjunction with the proto files. See gRPC API.
- Write your client app, referencing the functions or classes in the client stub files. See Client app development for details and a scenario.
Note about packaged proto files
The DLGaaS API provides features that require that you install the ASR, TTS, and NLU proto files, as well as certain supporting files:
- The StreamInput request performs recognition on streamed audio using ASRaaS and requests speech synthesis using TTSaaS.
- The ExecuteRequest allows you to specify interpretation results in the NLUaaS format.
For your convenience, these files are packaged with the DLGaaS proto files available here, and this documentation provides instructions for generating the stub files.
As such, the following files are packaged with this documentation:
- For DLGaaS API
- nuance/dlg/v1/dlg_interface.proto
- nuance/dlg/v1/dlg_messages.proto
- nuance/dlg/v1/common/dlg_common_messages.proto
- For ASRaaS audio streaming
- nuance/asr/v1/recognizer.proto
- nuance/asr/v1/resource.proto
- nuance/asr/v1/result.proto
- For TTSaaS streaming
- nuance/tts/v1/nuance_tts_v1.proto
- For NLUaaS interpretation
- nuance/nlu/v1/runtime.proto
- nuance/nlu/v1/result.proto
- nuance/nlu/v1/interpretation-common.proto
- nuance/nlu/v1/single-intent-interpretation.proto
- nuance/nlu/v1/multi-intent-interpretation.proto
- Supporting files for other services
- nuance/rpc/error_details.proto
- nuance/rpc/status.proto
- nuance/rpc/status_code.proto
Client app development
This section describes the main steps in a typical client application that interacts with a Mix.dialog application. In particular, it provides an overview of the different methods and messages used in a sample order coffee application.
Sample dialog exchange
To illustrate how to use the API, this document uses the following simple dialog exchange between an end user and a dialog application:
- System: Hello! Welcome to the coffee app. What type of coffee would you like?
- User: I want an espresso.
- System: And in what size would like that?
- User: Double.
- System: Thanks, your order is coming right up!
Overview
The DialogService is the main entry point to the Nuance Dialog service.
A typical workflow for accessing a dialog application at runtime is as follows:
- The client application requests the access token from the Nuance authorization server.
- The client application opens a secure channel using the access token.
- The client application creates a new conversation sending a StartRequest to the DialogService. The service returns a session ID, which is used at each interaction to keep the same conversation. The client application also sends an ExecuteRequest message with the session ID and an empty payload to kick off the conversation.
- As the user interacts with the dialog, the client application sends one of the following messages, as often as necessary:
- The ExecuteRequest message for text input and data exchange.
An ExecuteResponse is returned to the client application when a question and answer node, a data access node, or an external actions node is encountered in the dialog flow. - The StreamInput message for audio input (ASR) and/or audio output (TTS).
A StreamOutput is returned to the client application.
- The ExecuteRequest message for text input and data exchange.
- Optionally, at any point during the conversation, the client application can check that the session is still active by sending a StatusRequest message.
- Optionally, at any point during the conversation, the client application can update session variables by sending an UpdateRequest message.
- The client application closes the conversation by sending a StopRequest message.
This workflow is shown in the following high-level sequence flow:
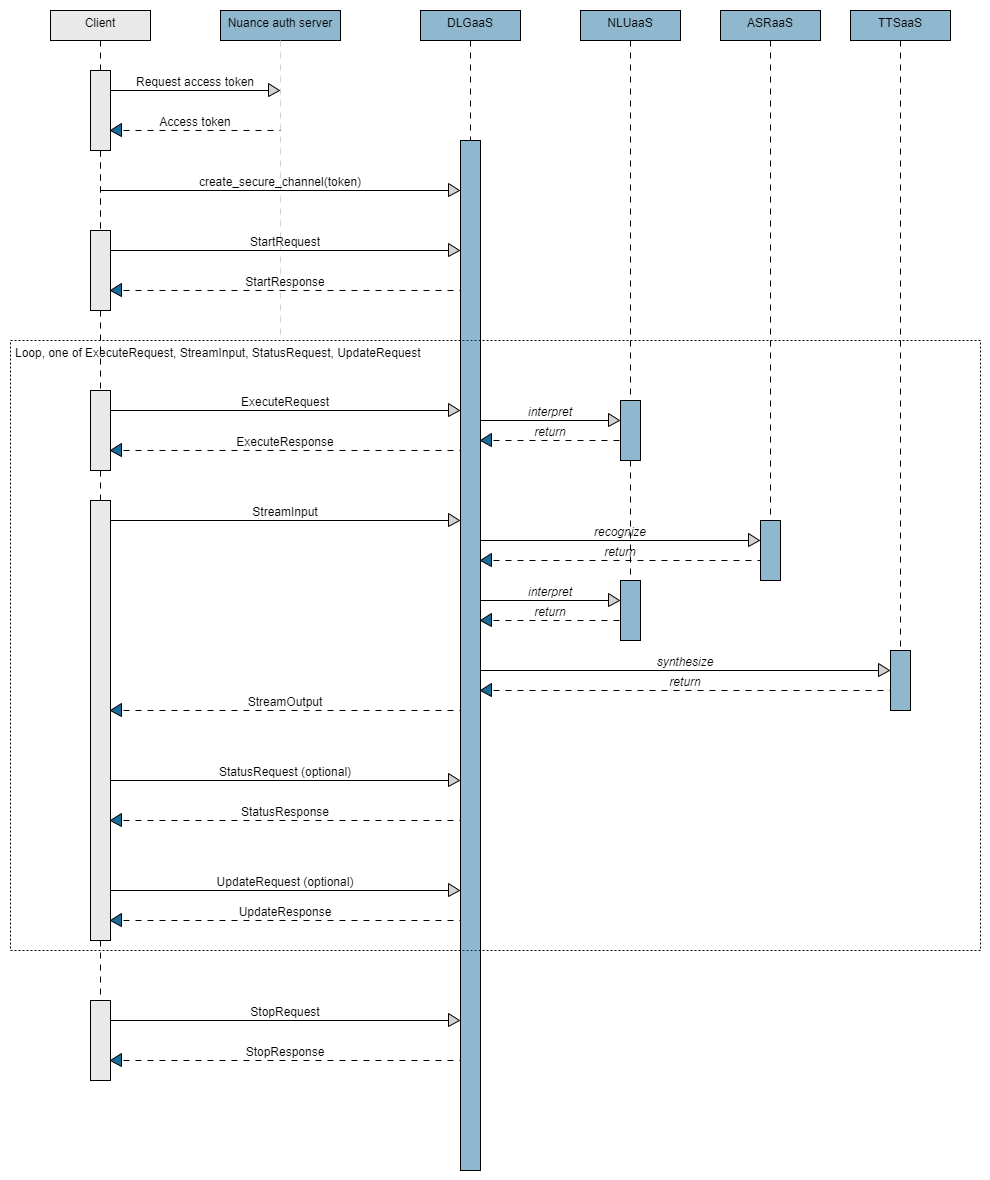
(Click the image for a close-up view)
For a detailed sequence flow diagram, see Detailed sequence flow.
Step 1. Generate token
Get token and run simple Mix client (run-simple-mix-client.sh)
#!/bin/bash
# Remember to change the colon (:) in your CLIENT_ID to code %3A
CLIENT_ID="appID%3ANMDPTRIAL_your_name_company_com_20201102T144327123022%3Ageo%3Aus%3AclientName%3Adefault"
SECRET="5JEAu0YSAjV97oV3BWy2PRofy6V8FGmywiUbc0UfkGE"
export MY_TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" "https://auth.crt.nuance.co.uk/oauth2/token" \
-d "grant_type=client_credentials" -d "scope=dlg" \
| python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`"
python dlg_client.py --serverUrl "dlg.api.nuance.co.uk:443" --token $MY_TOKEN --modelUrn "$1" --textInput "$2"
Nuance Mix uses the OAuth 2.0 protocol for authorization. To call the Dialog runtime service, your client application must request and then provide an access token. The token expires after a short period of time so must be regenerated frequently.
Your client application uses the client ID and secret from the Mix.dashboard (see Prerequisites from Mix) to generate an access token from the Nuance authorization server, available at the following URL:
https://auth.crt.nuance.co.uk/oauth2/token
The token may be generated in several ways, either as part of the client application or as a script file. This Python example uses a Linux script to generate a token and store it in an environment variable. The token is then passed to the application, where it is used to create a secure connection to the Dialog service.
The curl command in these scripts generates a JSON object including the access_token field that contains the token, then uses Python tools to extract the token from the JSON. The resulting environment variable contains only the token.
In this scenario, the colon (:) in the client ID must be changed to the code %3A so curl can parse the value correctly:
appID:NMDPTRIAL_alex_smith_nuance_com_20190919T190532:geo:qa:clientName:default
-->
appID%3ANMDPTRIAL_alex_smith_company_com_20190919T190532%3Ageo%3Aqa%3AclientName%3Adefault
Step 2. Authorize the service
def create_channel(args):
log.debug("Adding CallCredentials with token %s" % args.token)
call_credentials = grpc.access_token_call_credentials(args.token)
log.debug("Creating secure gRPC channel")
channel_credentials = grpc.ssl_channel_credentials()
channel_credentials = grpc.composite_channel_credentials(channel_credentials, call_credentials)
channel = grpc.secure_channel(args.serverUrl, credentials=channel_credentials)
return channel
You authorize the service by creating a secure gRPC channel, providing:
- The URL of the Dialog service
- The access token
Step 3. Start the conversation
def start_request(stub, model_ref_dict, session_id, selector_dict={}, timeout):
selector = Selector(channel=selector_dict.get('channel'),
library=selector_dict.get('library'),
language=selector_dict.get('language'))
start_payload = StartRequestPayload(model_ref=model_ref_dict)
start_req = StartRequest(session_id=session_id,
selector=selector,
payload=start_payload,
session_timeout_sec=timeout)
log.debug(f'Start Request: {start_req}')
start_response, call = stub.Start.with_call(start_req)
response = MessageToDict(start_response)
log.debug(f'Start Request Response: {response}')
return response, call
To start the conversation, you need to do two things:
- Start a new Dialog session
- Kick off the conversation
Start a new session
Before you can start the new conversation, the client app first needs to send a StartRequest message with the following information:
- An empty session ID, which tells the Dialog service to create a new ID for this conversation.
- The selector, which provides the channel, library, and language used for this conversation. This information was determined by the dialog designer in the Mix.dialog tool.
- The StartRequestPayload, which contains the reference to the model, provided as a ResourceReference. For a Mix application, this is the URN of the Dialog model to use for this interaction. The StartRequestPayload can also be used to set session data.
- An optional
user_id, which identifies a specific user within the application. See UserID for details. - An optional
client_data, used to inject data in call logs. This data will be added to the call logs but will not be masked. - An optional session timeout value,
session_timeout_sec(in seconds), after which the session is terminated. The default value is 900 (15 minutes) and the maximum is 259200 (72 hours).
A new unique session ID is generated and returned as a response; for example:
'payload': {'session_id': 'b8cba63a-f681-11e9-ace9-d481d7843dbd'}
The client app must then use the same session ID in all subsequent requests that apply to this conversation.
Additional notes on session IDs
- The session ID is often used for logging purposes, allowing you to easily locate the logs for a session.
- If the client app specifies a session ID in the StartRequest message, then the same ID is returned in the response.
- If passing in your own session ID in the StartRequest message, please follow these guidelines:
- The session Id should not begin or end with white space or tab
- The session Id should not begin or end with hyphens
Kick off the conversation
The client app needs to signal to Dialog to start the conversation.
Send an empty ExecuteRequest to Dialog to get started. Include the session ID but leave the user_text field of the payload user_input empty.
payload_dict = {
"user_input": {
"user_text": None
}
}
response, call = execute_request(stub,
session_id=session_id,
selector_dict=selector_dict,
payload_dict=payload_dict
)
Step 4. Step through the dialog
At each step, the client app sends input to advance the dialog to the next step. This can take one of four different forms depending on the place in the dialog.
- Send text input from user with Execute
- Send audio input from user with ExecuteStream
- Send requested data from client-side data fetch with Execute
- Signal to proceed with server-side data fetch with Execute
Step 4a. Interact with the user (text input)
def execute_request(stub, session_id, selector_dict={}, payload_dict={}):
selector = Selector(channel=selector_dict.get('channel'),
library=selector_dict.get('library'),
language=selector_dict.get('language'))
input = UserInput(user_text=payload_dict.get('user_input').get('userText'))
execute_payload = ExecuteRequestPayload(
user_input=input)
execute_request = ExecuteRequest(session_id=session_id,
selector=selector,
payload=execute_payload)
log.debug(f'Execute Request: {execute_payload}')
execute_response, call = stub.Execute.with_call(execute_request)
response = MessageToDict(execute_response)
log.debug(f'Execute Response: {response}')
return response, call
Interactions that use text input and do not require streaming are done through multiple ExecuteRequest calls, providing the following information:
- The session ID returned by the StartRequest.
- The selector, which provides the channel, library, and language used for this conversation. (This is optional; it is required only if the channel, library, or language values have changed since they were last sent.)
- The ExecuteRequestPayload, which can contain the following fields:
- user_input: Provides the input to the Dialog engine. For the initial ExecuteRequest, the payload is empty to get the initial message. For the subsequent requests, the input provided depends on how text interpretation is performed. See Interpreting text user input for more information.
- dialog_event: Can be used to pass in events that will drive the dialog flow. If no event is passed, the operation is assumed to be successful.
- requested_data: Contains data that was previously requested by the Dialog.
- An optional
user_id, which identifies a specific user within the application. See UserID for details.
ExecuteResponse for output
The dialog runtime app returns the Execute response payload when a question and answer node, a data access node, or an external actions node is encountered in the dialog flow. This payload provides the actions to be performed by the client application.
There are many types of actions that can be requested by the dialog application:
- Messages action—Indicates that a message should be played to the user. See Message actions.
- Data access action—Indicates that the dialog needs data from the client to continue the flow. The dialog application obtains the data it needs from the client using the data access gRPC API. The client application is responsible for obtaining the data from a data source. See Data access actions
- Question and answer action—Tells the client app to play a message and to return the user input to the dialog. See Question and answer actions.
- End action—Indicates the end of the dialog. See End actions.
- Escalation action—Provides data that can be used, for example, to escalate to an IVR agent.
- Continue action—Prompts the client application to respond to initiate a backend data exchange on the server side. Provides a message to play to the user to smooth over any latency while waiting for the data exchange.
For example, the following question and answer action indicates that the message "Hello! How can I help you today?" must be displayed to the user:
Note: Examples in this section are shown in JSON format for readability. However, in an actual client application, content is sent and received as protobuf objects.
"payload": {
"messages": [],
"qa_action": {
"message": {
"nlg": [],
"visual": [{
"text": "Hello! How can I help you today?"
}
],
"audio": []
}
}
}
A question and answer node expects input from the user to continue the flow. This can be provided as text (either to be interpreted by Nuance or as already interpreted input) in the next ExecuteRequest call. To provide the user input as audio, use the StreamInput request, as described in Step 4b.
Step 4b. Interact with the user (using audio)
def execute_stream_request(args, stub, session_id, selector_dict={}):
# Receive stream outputs from Dialog
stream_outputs = stub.ExecuteStream(build_stream_input(args, session_id, selector_dict))
log.debug(f'execute_responses: {stream_outputs}')
responses = []
audio = bytearray(b'')
for stream_output in stream_outputs:
if stream_output:
# Extract execute response from the stream output
response = MessageToDict(stream_output.response)
if response:
responses.append(response)
audio += stream_output.audio.audio
return responses, audio
def build_stream_input(args, session_id, selector_dict):
selector = Selector(channel=selector_dict.get('channel'),
library=selector_dict.get('library'),
language=selector_dict.get('language'))
try:
with open(args.audioFile, mode='rb') as file:
audio_buffer = file.read()
# Hard code packet_size_byte for simplicity sake (approximately 100ms of 16KHz mono audio)
packet_size_byte = 3217
audio_size = sys.getsizeof(audio_buffer)
audio_packets = [ audio_buffer[x:x + packet_size_byte] for x in range(0, audio_size, packet_size_byte) ]
# For simplicity sake, let's assume the audio file is PCM 16KHz
user_input = None
asr_control_v1 = {'audio_format': {'pcm': {'sample_rate_hz': 16000}}}
except:
# Text interpretation as normal
asr_control_v1 = None
audio_packets = [b'']
user_input = UserInput(user_text=args.textInput)
# Build execute request object
execute_payload = ExecuteRequestPayload(user_input=user_input)
execute_request = ExecuteRequest(session_id=session_id,
selector=selector,
payload=execute_payload)
# For simplicity sake, let's assume the audio file is PCM 16KHz
tts_control_v1 = {'audio_params': {'audio_format': {'pcm': {'sample_rate_hz': 16000}}}}
first_packet = True
for audio_packet in audio_packets:
if first_packet:
first_packet = False
# Only first packet should include the request header
stream_input = StreamInput(
request=execute_request,
asr_control_v1=asr_control_v1,
tts_control_v1=tts_control_v1,
audio=audio_packet
)
log.debug(f'Stream input initial: {stream_input}')
else:
stream_input = StreamInput(audio=audio_packet)
yield stream_input
Interactions with the user that require audio streaming are done through multiple ExecuteStream calls. ExecuteStream takes in a StreamInput message and returns a StreamOutput message. This provides a streaming audio option to handle audio input and audio output in a smooth way.
Streaminput for input
The StreamInput message can be used to:
- Provide the user input requested by a question and answer action as audio input. In this scenario, audio is streamed to ASRaaS, which performs recognition on the audio. The recognition results are sent to NLUaaS, which provides the interpretation. This is then returned to DLGaaS, which continues the dialog flow.
- Configure, and initiate synthesis of an output message into audio output using text-to-speech (TTS). In this scenario, if a TTS message has been defined in Mix.dialog for this interaction, TTSaaS synthesizes the message and streams the audio back to the client application in a series of StreamOutput calls.
The StreamInput method has the following fields:
- request: Provides the ExecuteRequest with the session ID, selector, and request payload.
- asr_control_v1: Provides the parameters to be forwarded to the ASR service, such as the audio format, recognition flags, recognition resources to use (such as DLMs, wordsets, and speaker profiles), whether results are returned, and so on. Setting
asr_control_v1enables streaming of input audio. audio: Audio to stream for speech recognition.- tts_control_v1: Provides the parameters to be forwarded to the TTS service, such as the audio encoding and voice to use for speech synthesis. Setting
tts_control_v1enables streaming of audio output. - control_message: (Optional) Message to start the recognition no-input timer if it was disabled with a stall_timers recognition flag in asr_control_v1.
Streamoutput for output
ExecuteStream returns a StreamOutput, which has the following fields:
- response, which provides the ExecuteResponse
audio, which is the audio returned by TTS (if TTS was requested)asr_result, which contains the transcription resultasr_status, which indicates the status of the transcriptionasr_start_of_speech, which contains the start-of-speech message
Note that speech responses do not necessarily need to use synthesized speech from TTS. Another option is to use recorded speech audio files. For more information, see Providing speech response using recorded speech audio.
Additional details on handling speech input and output in your application are available under Reference topics.
Step 4c. Send requested data
If the last ExecuteResponse included a data acess action requesting client-side fetch of specified data, the client app needs to fetch the data and returns it as part of the payload of an ExecuteRequest under requested_data. The payload will otherwise be empty, not containing user input. This happens when the dialog gets to a data access node that is configured for client-side data access. For more information about this, see Data access actions.
payload_dict = {
"requested_data": {
"id": "get_coffee_price",
"data": {
"coffee_price": "4.25",
"returnCode": "0"
}
}
}
response, call = execute_request(stub,
session_id=session_id,
selector_dict=selector_dict,
payload_dict=payload_dict
)
Step 4d. Proceed with server-side data fetch
If Dialog is carrying out a data fetch on the server-side that will take some time, and a latency message has been configured in Mix.dialog, Dialog can send messages to play to fill up the time and make the user experience waiting more pleasant as part of a Continue action.
To move on, the client app has to signal that it is ready for Dialog to carry on when it is ready. As you would when you first kick off a conversation, send an ExecuteRequest that includes the session ID but leave the user_text field of the payload user_input empty.
payload_dict = {
"user_input": {
"user_text": None
}
}
response, call = execute_request(stub,
session_id=session_id,
selector_dict=selector_dict,
payload_dict=payload_dict
)
Step 5. Check session status
def status_request(stub, session_id):
status_request = StatusRequest(session_id=session_id)
log.debug(f'Status Request: {status_request}')
status_response, call = stub.Status.with_call(status_request)
response = MessageToDict(status_response)
log.debug(f'Status Response: {response}')
return response, call
In a client application using asynchronous communication modalities such as text messaging, the client will not always necessarily know whether a session is still active, or whether it has expired. To check whether the session is still active, and if so, how much time is left in the ongoing session, the client app sends a StatusRequest message. This message has one field:
- The session ID returned by the StartResponse.
Some notes:
- This request can be sent at any time once a session is created. No user input is required, and this request does not trigger an event in the dialog and does not change the dialog state.
- This request can be called before an Execute, ExecuteStream, or Update call to check that the session is still active before sending the request.
A StatusResponse message is returned giving the approximate time left in the session. The status code can be one of the following:
- OK: The specified session was found.
- NOT_FOUND: The session specified could not be found.
Step 6. Update session data
def update_request(stub, session_id, update_data, client_data, user_id):
update_payload = UpdateRequestPayload(
data=update_data)
update_request = UpdateRequest(session_id=session_id,
payload=update_payload,
client_data=client_data,
user_id=user_id)
log.debug(f'Update Request: {update_request}')
update_response, call = stub.Update.with_call(update_request)
response = MessageToDict(update_response)
log.debug(f'Update Response: {response}')
return response, call
To update session data, the client app sends the UpdateRequest message; this message has the following fields:
- The session ID returned by the StartResponse.
- The UpdateRequestPayload, which contains the key-value pairs of variables to update. See Exchanging session data for details. The variables sent will be logged in the call logs, unless
suppressLogUserDatais set tofalsein the StartRequest. If one of the variables updated is identified as sensitive, its value will be masked in the log events. - An optional
client_data, used to inject data in call logs. This data will be added to the call logs but will not be masked. - An optional
user_id, which identifies a specific user within the application. See UserID for details.
Some notes:
- This request can be sent at any time once a session is created. No user input is required, and this request does not trigger an event in the dialog and does not change the dialog state.
- Session variables sent though the UpdateRequest payload should be defined in the Mix.dialog project. If they are not, the response will still be successful but no variables will be updated.
- This request resets the session timeout if the payload is empty.
- This request is usually called before an ExecuteRequest.
An empty UpdateResponse is returned. The status code can be one of the following:
- OK: The UpdateRequest was successful.
- NOT_FOUND: The session specified could not be found.
Step 7. Stop the conversation
def stop_request(stub, session_id=None):
stop_req = StopRequest(session_id=session_id)
log.debug(f'Stop Request: {stop_req}')
stop_response, call = stub.Stop.with_call(stop_req)
response = MessageToDict(stop_response)
log.debug(f'Stop Response: {response}')
return response, call
To stop the conversation, the client app sends the StopRequest message; this message has the following fields:
- The session ID returned by the StartRequest.
- An optional
user_id, which identifies a specific user within the application. See UserID for details.
The StopRequest message removes the session state, so the session ID for this conversation should not be used in the short term for any new interactions, to prevent any confusion when analyzing logs.
Note: If the dialog application concludes with an External Actions node of type End, your client application does not need to send the StopRequest message, since the End node closes the session. If both the StopRequest message is sent and the dialog application includes an End node, the StatusCode.NOT_FOUND error code is returned, since the session is closed and could not be found.
Detailed sequence flow
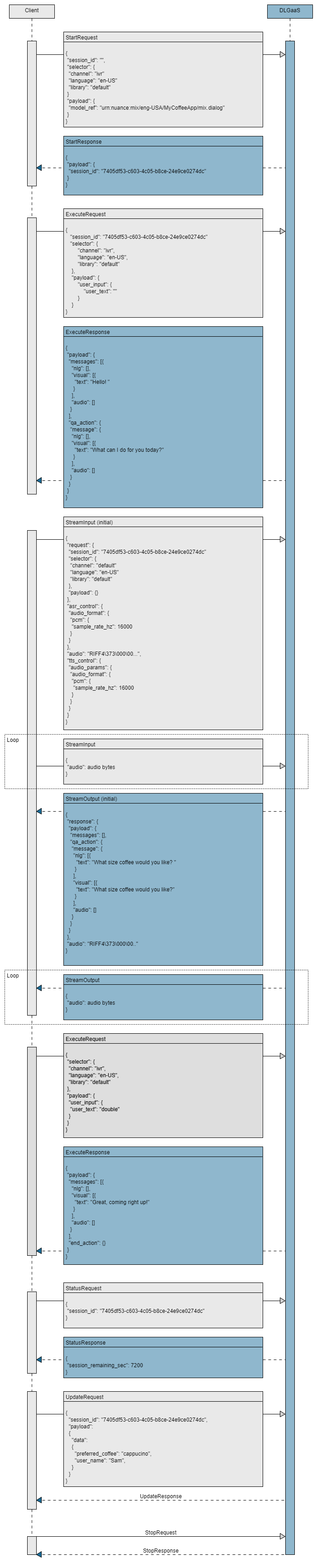
Sample Python app
dlg_client.py sample app
import argparse
import logging
import uuid
from google.protobuf.json_format import MessageToJson, MessageToDict
from grpc import StatusCode
from nuance.dlg.v1.common.dlg_common_messages_pb2 import *
from nuance.dlg.v1.dlg_messages_pb2 import *
from nuance.dlg.v1.dlg_interface_pb2 import *
from nuance.dlg.v1.dlg_interface_pb2_grpc import *
log = logging.getLogger(__name__)
def parse_args():
parser = argparse.ArgumentParser(
prog="dlg_client.py",
usage="%(prog)s [-options]",
add_help=False,
formatter_class=lambda prog: argparse.HelpFormatter(
prog, max_help_position=45, width=100)
)
options = parser.add_argument_group("options")
options.add_argument("-h", "--help", action="help",
help="Show this help message and exit")
options.add_argument("--token", nargs="?", help=argparse.SUPPRESS)
options.add_argument("-s", "--serverUrl", metavar="url", nargs="?",
help="Dialog server URL, default=localhost:8080", default='localhost:8080')
options.add_argument('--modelUrn', nargs="?",
help="Dialog App URN, e.g. urn:nuance-mix:tag:model/A2_C16/mix.dialog")
options.add_argument("--textInput", metavar="file", nargs="?",
help="Text to preform interpretation on")
return parser.parse_args()
def create_channel(args):
log.debug("Adding CallCredentials with token %s" % args.token)
call_credentials = grpc.access_token_call_credentials(args.token)
log.debug("Creating secure gRPC channel")
channel_credentials = grpc.ssl_channel_credentials()
channel_credentials = grpc.composite_channel_credentials(channel_credentials, call_credentials)
channel = grpc.secure_channel(args.serverUrl, credentials=channel_credentials)
return channel
def read_session_id_from_response(response_obj):
try:
session_id = response_obj.get('payload').get('sessionId', None)
except Exception as e:
raise Exception("Invalid JSON Object or response object")
if session_id:
return session_id
else:
raise Exception("Session ID is not present or some error occurred")
def start_request(stub, model_ref_dict, session_id, selector_dict={}):
selector = Selector(channel=selector_dict.get('channel'),
library=selector_dict.get('library'),
language=selector_dict.get('language'))
start_payload = StartRequestPayload(model_ref=model_ref_dict)
start_req = StartRequest(session_id=session_id,
selector=selector,
payload=start_payload)
log.debug(f'Start Request: {start_req}')
start_response, call = stub.Start.with_call(start_req)
response = MessageToDict(start_response)
log.debug(f'Start Request Response: {response}')
return response, call
def execute_request(stub, session_id, selector_dict={}, payload_dict={}):
selector = Selector(channel=selector_dict.get('channel'),
library=selector_dict.get('library'),
language=selector_dict.get('language'))
input = UserInput(user_text=payload_dict.get('user_input').get('userText'))
execute_payload = ExecuteRequestPayload(
user_input=input)
execute_request = ExecuteRequest(session_id=session_id,
selector=selector,
payload=execute_payload)
log.debug(f'Execute Request: {execute_payload}')
execute_response, call = stub.Execute.with_call(execute_request)
response = MessageToDict(execute_response)
log.debug(f'Execute Response: {response}')
return response, call
def execute_stream_request(args, stub, session_id, selector_dict={}):
# Receive stream outputs from Dialog
stream_outputs = stub.ExecuteStream(build_stream_input(args, session_id, selector_dict))
log.debug(f'execute_responses: {stream_outputs}')
responses = []
audio = bytearray(b'')
for stream_output in stream_outputs:
if stream_output:
# Extract execute response from the stream output
response = MessageToDict(stream_output.response)
if response:
responses.append(response)
audio += stream_output.audio.audio
return responses, audio
def build_stream_input(args, session_id, selector_dict):
selector = Selector(channel=selector_dict.get('channel'),
library=selector_dict.get('library'),
language=selector_dict.get('language'))
try:
with open(args.audioFile, mode='rb') as file:
audio_buffer = file.read()
# Hard code packet_size_byte for simplicity sake (approximately 100ms of 16KHz mono audio)
packet_size_byte = 3217
audio_size = sys.getsizeof(audio_buffer)
audio_packets = [ audio_buffer[x:x + packet_size_byte] for x in range(0, audio_size, packet_size_byte) ]
# For simplicity sake, let's assume the audio file is PCM 16KHz
user_input = None
asr_control_v1 = {'audio_format': {'pcm': {'sample_rate_hz': 16000}}}
except:
# Text interpretation as normal
asr_control_v1 = None
audio_packets = [b'']
user_input = UserInput(user_text=args.textInput)
# Build execute request object
execute_payload = ExecuteRequestPayload(user_input=user_input)
execute_request = ExecuteRequest(session_id=session_id,
selector=selector,
payload=execute_payload)
# For simplicity sake, let's assume the audio file is PCM 16KHz
tts_control_v1 = {'audio_params': {'audio_format': {'pcm': {'sample_rate_hz': 16000}}}}
first_packet = True
for audio_packet in audio_packets:
if first_packet:
first_packet = False
# Only first packet should include the request header
stream_input = StreamInput(
request=execute_request,
asr_control_v1=asr_control_v1,
tts_control_v1=tts_control_v1,
audio=audio_packet
)
log.debug(f'Stream input initial: {stream_input}')
else:
stream_input = StreamInput(audio=audio_packet)
yield stream_input
def stop_request(stub, session_id=None):
stop_req = StopRequest(session_id=session_id)
log.debug(f'Stop Request: {stop_req}')
stop_response, call = stub.Stop.with_call(stop_req)
response = MessageToDict(stop_response)
log.debug(f'Stop Response: {response}')
return response, call
def main():
args = parse_args()
log_level = logging.DEBUG
logging.basicConfig(
format='%(asctime)s %(levelname)-5s: %(message)s', level=log_level)
with create_channel(args) as channel:
stub = DialogServiceStub(channel)
model_ref_dict = {
"uri": args.modelUrn,
"type": 0
}
selector_dict = {
"channel": "default",
"language": "en-US",
"library": "default"
}
response, call = start_request(stub,
model_ref_dict=model_ref_dict,
session_id=None,
selector_dict=selector_dict
)
session_id = read_session_id_from_response(response)
log.debug(f'Session: {session_id}')
assert call.code() == StatusCode.OK
log.debug(f'Initial request, no input from the user to get initial prompt')
payload_dict = {
"user_input": {
"userText": None
}
}
response, call = execute_request(stub,
session_id=session_id,
selector_dict=selector_dict,
payload_dict=payload_dict
)
assert call.code() == StatusCode.OK
log.debug(f'Second request, passing in user input')
payload_dict = {
"user_input": {
"userText": args.textInput
}
}
response, call = execute_request(stub,
session_id=session_id,
selector_dict=selector_dict,
payload_dict=payload_dict
)
assert call.code() == StatusCode.OK
response, call = stop_request(stub,
session_id=session_id
)
assert call.code() == StatusCode.OK
if __name__ == '__main__':
main()
The sample Python application consists of these files:
- dlg_client.py: The main client application file.
- run-mix-client.sh: A script file that generates the access token and runs the application.
Requirements
To run this sample app, you need:
- Python 3.6 or later. Use
python3 --versionto check which version you have. - Credentials from Mix (a client ID and secret) to generate the access token. See Prerequisites from Mix.
Procedure
To run this sample application:
Step 1. Download the sample app here and unzip it in a working directory (for example, /home/userA/dialog-sample-python-app).
Step 2. Download the gRPC .proto files here and unzip the files in the sample app working directory.
Step 3. Navigate to the sample app working directory and install the required dependencies. The details will depend on the platform and command shell you are using.
For a POSIX OS using bash:
python3 -m venv env
source env/bin/activate
pip install --upgrade pip
pip install grpcio
pip install grpcio-tools
pip install uuid
For Windows using cmd.exe:
python -m venv env
env/Scripts/activate
python -m pip install --upgrade pip
pip install grpcio
pip install grpcio-tools
pip install uuid
For Windows using Git Bash command shell, the details are almost the same, but substitute source env/Scripts/activate for env/Scripts/activate.
Step 4. Generate the stubs:
echo "Pulling support files"
mkdir -p google/api
curl https://raw.githubusercontent.com/googleapis/googleapis/master/google/api/annotations.proto > google/api/annotations.proto
curl https://raw.githubusercontent.com/googleapis/googleapis/master/google/api/http.proto > google/api/http.proto
echo "generate the stubs for support files"
python -m grpc_tools.protoc --proto_path=./ --python_out=./ google/api/http.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=./ google/api/annotations.proto
echo "generate the stubs for the DLGaaS gRPC files"
python -m grpc_tools.protoc --proto_path=./ --python_out=. --grpc_python_out=. nuance/dlg/v1/dlg_interface.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=. nuance/dlg/v1/dlg_messages.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=. nuance/dlg/v1/common/dlg_common_messages.proto
echo "generate the stubs for the ASRaaS gRPC files"
python -m grpc_tools.protoc --proto_path=./ --python_out=. --grpc_python_out=. nuance/asr/v1/recognizer.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=. nuance/asr/v1/resource.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=. nuance/asr/v1/result.proto
echo "generate the stubs for the TTSaaS gRPC files"
python -m grpc_tools.protoc --proto_path=./ --python_out=. --grpc_python_out=. nuance/tts/v1/nuance_tts_v1.proto
echo "generate the stubs for the NLUaaS gRPC files"
python -m grpc_tools.protoc --proto_path=./ --python_out=. --grpc_python_out=. nuance/nlu/v1/runtime.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=. nuance/nlu/v1/result.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=. nuance/nlu/v1/interpretation-common.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=. nuance/nlu/v1/single-intent-interpretation.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=. nuance/nlu/v1/multi-intent-interpretation.proto
echo "generate the stubs for supporting files"
python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/error_details.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/status.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/status_code.proto
Step 5. Edit the run script, run-mix-client.sh, to add your CLIENT_ID and SECRET. These are your Mix credentials as described in Generate token.
CLIENT_ID="appID%3A...ENTER MIX CLIENT_ID..."
SECRET="...ENTER MIX SECRET..."
export MY_TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" \
"https://auth.crt.nuance.co.uk/oauth2/token" \
-d "grant_type=client_credentials" -d "scope=dlg" \
| python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'"
python dlg_client.py --serverUrl "dlg.api.nuance.co.uk:443" --token $MY_TOKEN --modelUrn "$1" --textInput "$2"
Step 6. Run the application using the script file, passing it the URN and a text to interpret:
./run-mix-client.sh modelUrn textInput
Where:
- modelUrn: Is the URN of the application configuration for the Coffee App created in the Quick Start
- textInput: Is the text to interpret
For example:
$ ./run-mix-client.sh "urn:nuance-mix:tag:model/TestMixClient/mix.dialog" "I want a double espresso"
An output similar to the following is provided:
2020-12-07 17:04:05,414 DEBUG: Creating secure gRPC channel
2020-12-07 17:04:05,420 DEBUG: Start Request: selector {
channel: "default"
language: "en-US"
library: "default"
}
payload {
model_ref {
uri: "urn:nuance-mix:tag:model/TestMixClient/mix.dialog"
}
}
2020-12-07 17:04:05,945 DEBUG: Start Request Response: {'payload': {'sessionId': '92705444-cd59-4a04-b79c-e67203f04f0d'}}
2020-12-07 17:04:05,948 DEBUG: Session: 92705444-cd59-4a04-b79c-e67203f04f0d
2020-12-07 17:04:05,949 DEBUG: Initial request, no input from the user to get initial prompt
2020-12-07 17:04:05,952 DEBUG: Execute Request: user_input {
}
2020-12-07 17:04:06,193 DEBUG: Execute Response: {'payload': {'messages':
[{'visual': [{'text': 'Hello and welcome to the coffee app.'}], 'view': {}}],
'qaAction': {'message': {'visual': [{'text': 'What can I get you today?'}]},
'data': {}, 'view': {}}}}
2020-12-07 17:04:06,198 DEBUG: Second request, passing in user input
2020-12-07 17:04:06,199 DEBUG: Execute Request: user_input {
user_text: "I want a double espresso"
}
2020-12-07 17:04:06,791 DEBUG: Execute Response: {'payload': {'messages':
[{'visual': [{'text': 'Perfect, a double espresso coming right up!'}], 'view':
{}}], 'endAction': {'data': {}, 'id': 'End dialog'}}}
Reference topics
This section provides more detailed information about objects used in the gRPC API.
Note: Examples in this section are shown in JSON format for readability. However, in an actual client application, content is sent and received as protobuf objects.
Status messages and codes
gRPC error codes
In addition to the standard gRPC error codes, DLGaaS uses the following codes:
| gRPC code | Message | Indicates |
|---|---|---|
| 0 | OK | Normal operation |
| 5 | NOT FOUND | The resource specified could not be found; for example:
Troubleshooting: Make sure that the resource provided exists or that you have specified it correctly. See URN for details on the URN syntax. |
| 9 | FAILED_PRECONDITION | ASRaaS and/or NLUaaS returned 400 range status codes |
| 11 | OUT_OF_RANGE | The provided session timeout is not in the expected range. Troubleshooting: Specify a value between 0 and 90000 seconds (default is 900 seconds) and try again. |
| 12 | UNIMPLEMENTED | The API version was not found or is not available on the URL specified. For example, a client using DLGaaS v1 is trying to access the dlgaas.beta.nuance.co.uk URL. Troubleshooting: See URLs to runtime services for the supported URLs. |
| 13 | INTERNAL | There was an issue on the server side or interactions between sub systems have failed. Troubleshooting: Contact Nuance. |
| 16 | UNAUTHENTICATED | The credentials specified are incorrect or expired. Troubleshooting: Make sure that you have generated the access token and that you are providing the credentials as described in Authorize your client application. Note that the token needs to be regenerated regularly. See Access token lifetime for details. |
HTTP return codes
In addition to the standard HTTP error codes, DLGaaS uses the following codes:
| HTTP code | Message | Indicates |
|---|---|---|
| 200 | OK | Normal operation |
| 400 | BAD_REQUEST | Server cannot process the request due to client error such as a malformed request |
| 401 | UNAUTHORIZED | The credentials specified are incorrect or expired. Troubleshooting: Make sure that you have generated the access token and that you are providing the credentials as described in Authorize your client application. Note that the token needs to be regenerated regularly. See Access token lifetime for details. |
| 404 | NOT_FOUND | The resource specified could not be found; for example:
Troubleshooting: Make sure that the resource provided exists or that you have specified it correctly. See URN for details on the URN syntax. |
| 500 | INTERNAL_SERVER_ERROR | There was an issue on the server side. Troubleshooting: Contact Nuance. |
Values in the 400 range indicate an error in the request that your client app sent. Values in the 500 range indicate an internal error within DLGaaS or another Mix service.
Examples
Incorrect URN
"grpc_message":"model [urn:nuance:mix/eng-USA/coffee_app_typo/mix.dialog] could not be found","grpc_status":5
Incorrect channel
"grpc_message":"channel is invalid, supported values are [Omni Channel VA, default] (error code: 5)","grpc_status":5}"
Session not found
"grpc_message":"Could not find session for [12345]","grpc_status":5}"
Incorrect credentials
"{"error":{"code":401,"status":"Unauthorized","reason":"Token is expired","message":"Access credentials are invalid"}\n","grpc_status":16}"
Message actions
Example message action as part of QA Action
{
"payload": {
"messages": [],
"qa_action": {
"message": {
"nlg": [{
"text": "What type of coffee would you like?"
}
],
"visual": [{
"text": "What <b>type</b> of coffee would you like? For the list of options, see the <a href=\"www.myserver.com/menu.html\">menu</a>."
}
],
"audio": [{
"text": "What type of coffee would you like? ",
"uri": "en-US/prompts/default/default/Message_ini_01.wav?version=1.0_1602096507331"
}
]
}
}
}
}
A message action indicates that a message should be played to the user. A message can be provided as:
- Text to be rendered using Text-to-speech: The
nlgfield provides backup text as a fallback for speech outputs sythesized using TTSaaS. For more information about how to generate TTSaaS speech audio, see Step 4b. Interact with the user (using audio). - Text to be visually displayed to the user: The
visualfield provides text that can be displayed, for example, in a chat or in a web application. This field supports rich text format, so you can include HTML markups, URLs, etc. - Audio file to play to the user: The
audiofield provides a link to a recorded audio file that can be played to the end user. Theurifield provides the link to the file, while thetextfield provides text that can be used as backup TTS if the audio file is missing or cannot be played.
Message actions can be configured in the following Mix.dialog nodes:
- Message node: In this case they are returned in the
messagesfield of the ExecuteRequestPayload. Messages specified in a message node are returned only when a question and answer, data access, or external actions node occurs in the dialog flow. See Message nodes for details. - Question and answer node: In this case they are returned in the message field of the ExecuteRequestPayload qa_action
- Data access node: A latency message can be defined to be played while the user is waiting for a data transfer to take place, whether client-side or server-side.
Message nodes
A message node is used to play or display a message. The message specified in a message node is sent to the client application as a message action. A message node also performs non-recognition actions, such as playing a message, assigning a variable, or defining the next node in the dialog flow.
Messages configured in a message node are cumulative and sent only when a question and answer node, a data access node, or an external actions node occurs in the dialog flow. For example, consider the following dialog flow:
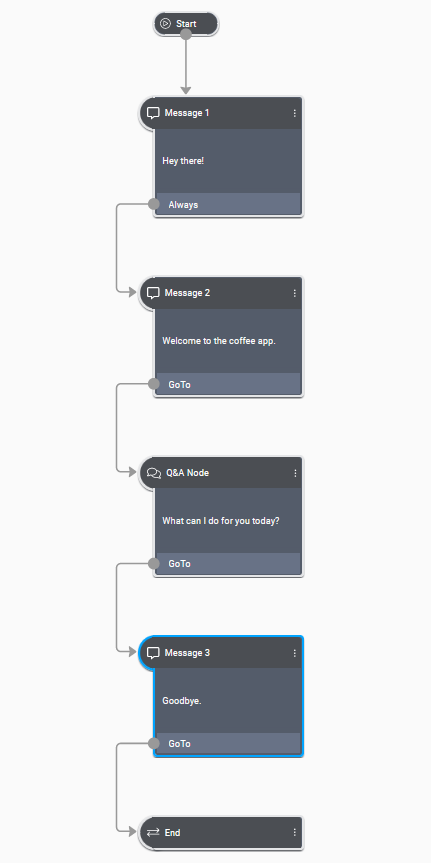
This would be handled as follows:
- The Dialog service sends an ExecuteResponse when encountering the question and answer node, with the following messages:
# First ExecuteResponse { "payload": { "messages": [{ "nlg": [], "visual": [{ "text": "Hey there!" } ], "audio": [] }, { "nlg": [], "visual": [{ "text": "Welcome to the coffee app." } ], "audio": [] } ], "qa_action": { "message": { "nlg": [], "visual": [{ "text": "What can I do for you today?" } ], "audio": [] } } } }
- The client application sends an ExecuteRequest with the user input.
- The Dialog service sends an ExecuteResponse when encountering the end node, with the following message action:
# Second ExecuteResponse { "payload": { "messages": [{ "nlg": [], "visual": [{ "text": "Goodbye." } ], "audio": [] } ], "end_action": {} } }
Using variables in messages
Messages can include variables. For example, in a coffee application, you might want to personalize the greeting message:
"Hello Miranda ! What can I do for you today?"
Variables are configured in Mix.dialog. They are resolved by the Dialog engine and then returned to the client application. For example:
{
"payload": {
"messages": [],
"qa_action": {
"message": {
"nlg": [],
"visual": [
{
"text": "Hello Miranda ! What can I do for you today?"
}
],
"audio": []
}
}
}
}
Question and answer actions
A question and answer action is returned by a question and answer node. A question and answer node is the basic node type in dialog applications. It first plays a message and then recognizes user input.
The message specified in a question and answer node is sent to the client application as a message action.
The client application must then return the user input to the question and answer node. This can be provided in four ways:
- As audio to be recognized and interpreted by Nuance. This is implemented in the client app through the StreamInput method. See Step 4b. Interact with the user (using audio) for details.
- As text to be interpreted by Nuance. In this case, the client application returns the input string to the dialog application. See Interpreting text user input for details.
- As interpretation results. This assumes that interpretation of the user input is performed by an external system. In this case, the client application is responsible for returning the results of the interpretation to the dialog application. See Interpreting text user input for details.
- As a selected option from an interactive element.
In a question and answer node, the dialog flow is stopped until the client application has returned the user input.
Sending data
A question and answer node can specify data to send to the client application. This data is configured in Mix.dialog, in the Send Data tab of the question and answer node. For the procedure, see Send data to the client application in the Mix.dialog documentation.
For example, in the coffee application, you might want to send entities that you have collected in a previous node (COFFEE_TYPE and COFFEE_SIZE) as well as data that you have retrieved from an external system (the user's rewards card number):
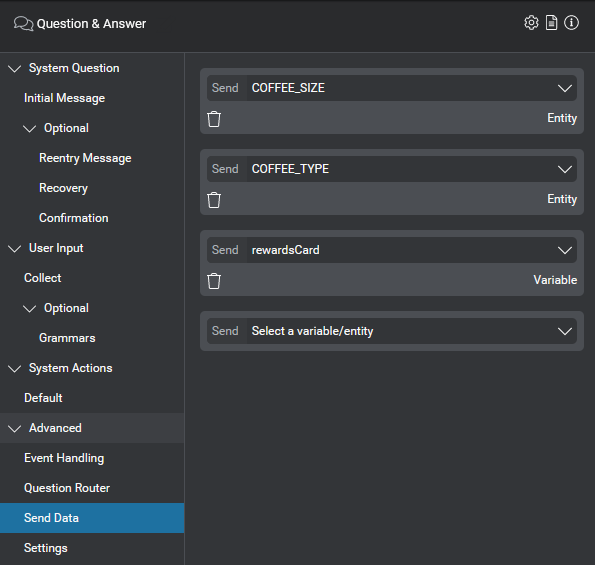
This data is sent to the client application in the data field of the qa_action; for example:
{
"payload": {
"messages": [],
"qa_action": {
"message": {
"nlg": [],
"visual": [
{
"text": "Your order was processed. Would you like anything else today?"
}
],
"audio": [],
"view": {
"id": "",
"name": ""
}
},
"data": {
"rewardsCard": "5367871902680912",
"COFFEE_TYPE": "espresso",
"COFFEE_SIZE": "lg"
}
}
}
}
Interactive elements
Question and answer actions can include interactive elements to be displayed by the client app, such as clickable buttons or links.
For example, in a web version of the coffee application, you may want to display Yes/No buttons so that users can confirm their selection for an entity named answer which takes values of Yes or No:
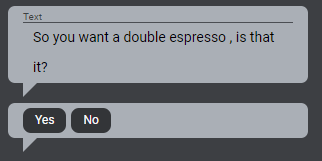
Interactive elements are configured in Mix.dialog in question and answer nodes. For the procedure, see Define interactive elements in the Mix.dialog documentation.
For example, for the Yes/No buttons scenario above, you could configure two elements, one for each button, as follows:
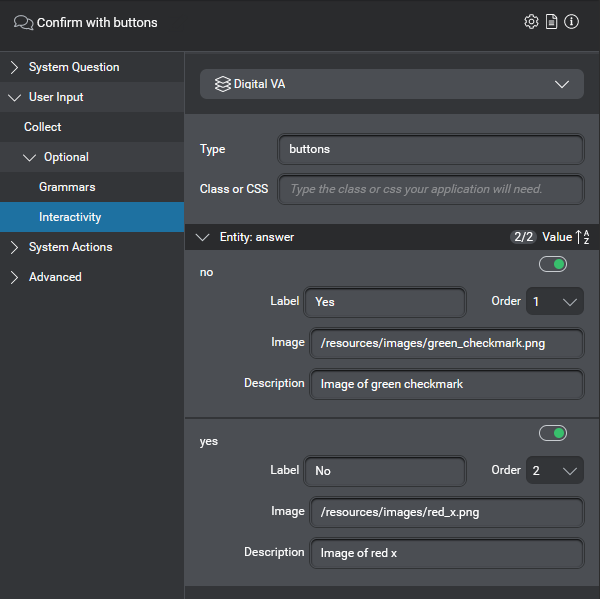
This information is sent to the client app in the selectable field of the qa_action. For example:
{
"payload": {
"messages": [],
"qa_action": {
"message": {
"nlg": [],
"visual": [{
"text": "So you want a double espresso , is that it?"
}
],
"audio": []
},
"selectable": {
"selectable_items": [{
"value": {
"id": "answer",
"value": "yes"
},
"description": "Image of green checkmark",
"display_text": "Yes",
"display_image_uri": "/resources/images/green_checkmark.png"
}, {
"value": {
"id": "answer",
"value": "no"
},
"description": "Image of Red X",
"display_text": "No",
"display_image_uri": "/resources/images/red_x.png"
}
]
}
}
}
}
The application is then responsible for displaying the elements (in this case, the two buttons) and for returning the choice made by the user in the selected_item field of the Execute Request payload. For example:
"payload": {
"user_input": {
"selected_item": {
"id": "answer",
"value": "no"
}
}
}
In both cases the field "id" corresponds to the name of the entity as defined in Mix.dialog or Mix.nlu.
Data access actions
A data access action tells the client app that the dialog needs data from the client to continue the flow. For example, consider the following use cases:
- In a coffee application, after asking the user for the type and size of coffee to order, the dialog must provide the price of the order before completing the transaction. In this use case, the dialog sends a data access action to the client application, providing the type and size of coffee and requesting the price.
- In a banking application, after having collected all the information necessary to make a payment (that is, the user's account, the payee, and the payment amount), the dialog is ready to complete the payment. In this use case, the dialog sends a data access action to the client application, providing all the transaction details so that the client application can process the payment and provide a return code back to the dialog.
Data access actions are configured in Mix.dialog in data access nodes. The configurations in these nodes specify:
- Variables or entities sent by the Dialog service to the client application
- Variables the Dialog service expects to be sent back by the client application
- A message to play to the user while waiting for the data to be retrieved and transferred
- Settings for playing the message
Data access actions are sent only when the data access node has enabled client-side fetching.
Data access nodes can also be configured in Mix.dialog for server-side fetching directly from a backend server without going through the DLGaaS API. In that case a Continue action is sent instead.
See Exchange data with an external system for additional details.
Using the data access API in the client app
When a data access node is configured for client-side fetching, data access information is sent and received as follows:
- The dialog sends data in the
da_actionfield of the ExecuteResponsePayload - The client app sends data in the
requested_datafield of the ExecuteRequestPayload
For example, in the coffee app use case, if a user says "I want a double espresso," the dialog will send data access action information to the client application in the ExecuteResponsePayload:
{
"payload": {
"messages": [
{
"nlg": [],
"visual": [
{
"text": "Great! A large espresso coming right up.",
"mask": false,
"barge_in_disabled": false
}
],
"audio": [],
"view": {
"id": "",
"name": ""
}
}
],
"da_action": {
"id": "get_coffee_price",
"message": {
"nlg": [],
"visual": [
{
"text": "Hold on a moment while we ring that up.",
"mask": false,
"barge_in_disabled": false
}
],
"audio": []
},
"view": {
"id": "sample class",
"name": "sample type"
},
"data": {
"COFFEE_TYPE": "espresso",
"COFFEE_SIZE": "lg"
},
"message_settings": {
"delay": "500ms",
"minimum": "0ms"
}
}
}
}
Where:
idinda_actionuniquely identifies the data access action node. This lets the client application know what process is required. For example, when the client app parses the ExecuteResponse and sees a data access action id ofget_coffee_price, it can call a function that retrieves the coffee price.dataprovides the values of the sent data that were configured in the Data Access node. In this case, it is entity values that were collected in Dialog, and which tell the client app which coffee price it needs to look up.messageprovides details for a message the client can play to the user while waiting on the data exchange.message_settingsprovides settings to be used along with the message played to the user
The client application uses that information to perform the action required by the dialog, in this case fetching the price of the coffee based on the user's choice. While retrieving the data it plays the message to the user using the specified message settings.
When the client gets the coffee price from the data source, it then returns the value in the coffee_price variable as part of the ExecuteRequestPayload data field. Note that data also includes a returnCode.
{
"selector": {
"channel": "ivr",
"language": "en-US",
"library": "default"
},
"payload": {
"requested_data": {
"id": "get_coffee_price",
"data": {
"coffee_price": "4.25",
"returnCode": "0"
}
}
}
}
The returnCode is required, otherwise the Execute request will fail. A returnCode of "0" indicates a successful interaction.
Data access action sequence flow
This sequence diagram here shows a data access action exchange. For simplicity, only the payload of the requests and responses related to the data access feature are shown.
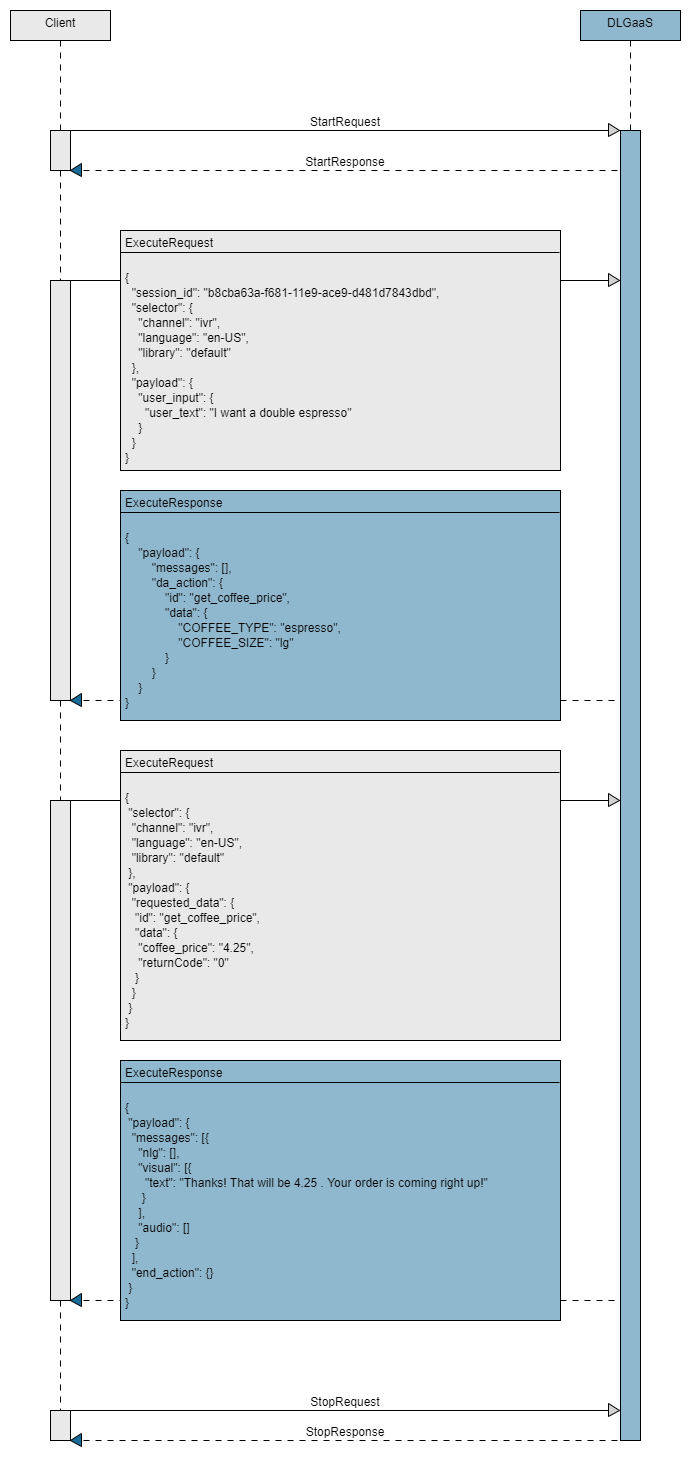
Continue actions
Self-hosted environments: Latency messages require version 1.1 (or later) of the Dialog service. IVR applications using Nuance Speech Suite with VoiceXML Connector 1.0 or earlier do not support the fetching properties, or the continue action interaction for server-side fetching.
A continue action is used in the case of a Data access node using a backend server connection to access the required data.
In this case, DLGaaS pauses before continuing on with the data access step, and sends an ExecuteResponse containing a continue action to the client app.
The continue action provides the client app with information useful for smoothing over any latency or delays while DLGaaS tries to access the data from the backend server. This includes:
- A message to play to the user while waiting for a response
- Guidance on how long to wait before playing the message and how long to play the message
- The timeout settings for connecting to the server backend and for fetching data from the backend
For example, in the coffee app use case, if a user says "I want a double espresso," the dialog will send continue action information to the client application in the ExecuteResponsePayload:
{
"payload": {
"messages": [
{
"nlg": [],
"visual": [
{
"text": "Great! A large espresso coming right up!",
"mask": false,
"bargeInDisabled": false
}
],
"audio": [],
"view": {
"id": "",
"name": ""
}
}
],
"continueAction": {
"message": {
"nlg": [],
"visual": [
{
"text": "Hold on a moment while we ring that up.",
"mask": false,
"bargeInDisabled": false
}
],
"audio": []
},
"view": {
"id": "sample class",
"name": "sample type"
},
"id": "DataAccess",
"messageSettings": {
"delay": "500ms",
"minimum": "0ms"
},
"backendConnectionSettings": {
"fetchTimeout": "30s",
"connectTimeout": ""
}
}
}
}
To continue the flow, the client app must send an ExecuteRequest to DLGaaS containing only the current session_id.
DLGaaS proceeds to attempt to retrieve the data from the backend server, and in the meantime, the client app can play the provided message to keep the user informed and engaged while waiting for the response from DLGaaS.
DLGaaS will then continue with the flow as configured in the dialog.
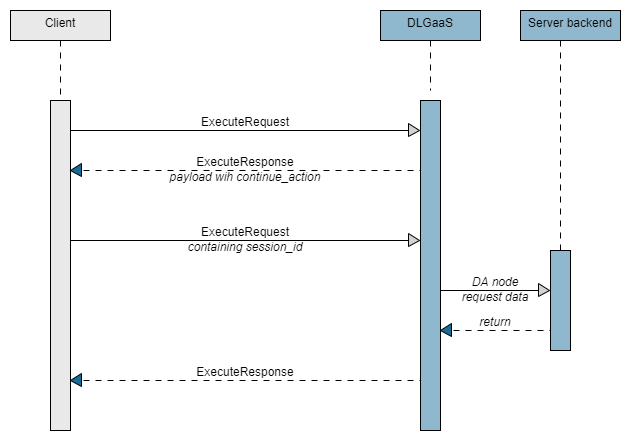
Continue action settings are configured in Mix.dialog in the data access node settings, under Latency message and Backend connection overrides. See Set up a data access node in the Mix.dialog documentation for more details.
Transfer actions
An external actions node of type "Transfer" in Mix.dialog sends an Escalation action in the DGLaaS API. This action can be used, for example, to escalate to an IVR agent. Any data set in the Transfer node is sent as part of the Escalation action data field.
To continue the flow, the client application must return data in the requested_data field of the ExecuteRequestPayload. At a minimum, this data must include a returnCode. It can also include data requested by the dialog, if any. The returnCode is required, otherwise the Execute request will fail. A returnCode of "0" indicates a successful interaction.
For example, consider a scenario where the Transfer action is used to escalate to an agent to confirm a customer's data, as shown in the following Mix.dialog node:
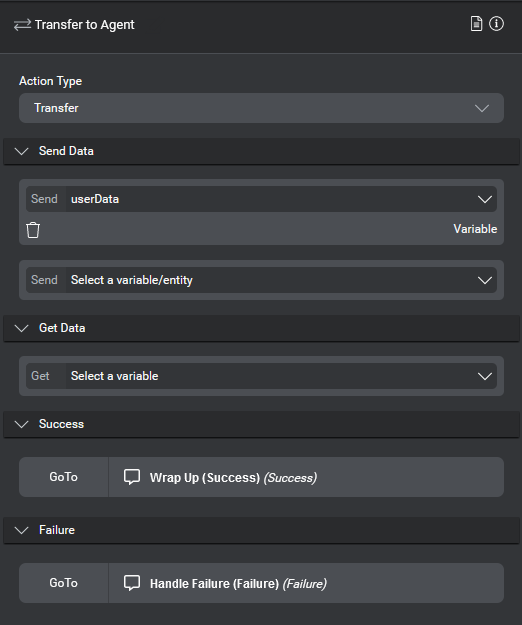
This transfer action sends the userName and userID variables to the client application in an escalation_action, as follows:
{
"payload": {
"messages": [],
"escalation_action": {
"data": {
"userName": "Miranda Smith",
"userID": "MIRS82734"
},
"id": "TransferToAgent"
}
}
}
The client application transfers the call and then returns a returnCode to the dialog to provide the status of the transaction. If the transfer was successful, a returnCode of "0" returned. For example:
{
"selector": {
"channel": "default",
"language": "en-US",
"library": "default"
},
"payload": {
"requested_data": {
"id": "TransferToAgent",
"data": {
"returnCode": "0"
}
}
}
}
End actions
An external actions node of type "End" returns an End action, which indicates the end of the dialog. It includes the ID that identifies the node in the Mix.dialog application as well as any data that you set for this node. For example:
{
"payload": {
"messages": [{
"nlg": [],
"visual": [{
"text": "Perfect, a double espresso coming right up!"
}
],
"audio": []
}
],
"end_action": {
"data": {
"returnCode": "0"
},
"id": "CoffeeApp End node"
}
}
}
Interpreting text user input
Interpretation of user input provided as text can be performed either by the Nuance Mix Platform (using NLUaaS) or by an external system.
Nuance Mix Platform performs interpretation
Example: Interpretation is performed by Nuance
"payload": {
"user_input": {
"user_text": "I want a large coffee"
}
}
When the Nuance Mix Platform is responsible for interpreting user input, the client application sends the text collected from the end user in the user_text field of the Execute request input message. The user text is sent to NLUaaS, which performs interpretation and returns the results to DLGaaS.
External system performs interpretation
Example: Interpretation is performed by an external system (simple format)
"payload": {
"user_input": {
"interpretation": {
"confidence": 1.0,
"utterance": "I want a large americano",
"data": {
"INTENT": "ORDER_COFFEE",
"COFFEE_SIZE": "LG",
"COFFEE_TYPE": "americano"
},
"slot_literals": {
"COFFEE_SIZE": "large",
"COFFEE_TYPE": "americano"
}
}
}
}
Example: Interpretation is performed by an external system (NLUaaS format)
"payload": {
"user_input": {
"nluaas_interpretation": {
"literal": "i want a double espresso",
"interpretations": [{
"single_intent_interpretation": {
"intent": "ORDER_COFFEE",
"confidence": 1,
"origin": "GRAMMAR",
"entities": {
"COFFEE_SIZE": {
"entities": [{
"text_range": {
"start_index": 9,
"end_index": 15
},
"confidence": 1,
"origin": "GRAMMAR",
"string_value": "lg"
}
]
},
"COFFEE_TYPE": {
"entities": [{
"text_range": {
"start_index": 16,
"end_index": 24
},
"confidence": 1,
"origin": "GRAMMAR",
"string_value": "espresso"
}
]
}
}
}
}
]
}
}
}
When an external system is responsible for interpreting user input, the client application sends the results of this interpretation in one of the following fields:
- For simple interpretations that include entities with string values only, use the interpretation field of the Execute request user_input message, including the intent and entities to use for this interaction.
- For interpretations that include complex entities, use the nluaas_interpretation field of the Execute request user_input message. This field expects the interpretation in the format used by the NLUaaS engine. See the NLUaaS InterpretResult documentation for details. Note that DLGaaS supports single intent interpretations only.
Performing speech recognition on audio input
The workflow to perform speech recognition on audio input is as follows:
- The Dialog service sends an ExecuteResponse with a question and answer action, indicating that it requires user input.
- The client application sends a first StreamInput method with the asr_control_v1, request, and control_message parameters to DLGaaS; this lets DLGaaS know to expect audio and provides parameters and resources to facilitate and tune the transcription.
- The client application sends additional StreamInputs to stream the audio.
- The client application sends an empty StreamInput to indicate end of audio.
The audio is recognized, interpreted, and returned to the dialog application, which continues its flow. - The Dialog service returns the corresponding ExecuteResponse in a single StreamOutput.
This can be seen in the detailed sequence flow. For example, assuming that the user says "I want an espresso", the client application will send a series of StreamInput methods with the following content:
# First StreamInput
{
"request": {
"session_id": "1c2c9822-45d5-460d-8696-d3fa9d8af8c2",
"selector": {
"channel": "default"
"language": "en-US"
"library": "default"
},
"payload": {}
},
"asr_control_v1": {
"audio_format": {
"pcm": {
"sample_rate_hz": 16000
}
}
},
"audio": "RIFF4\373\000\00..."
}
# Additional StreamInputs with audio bytes
{
"audio": "...audio_bytes..."
}
# Final empty StreamInput to indicate end of audio
{
}
Once audio has been recognized, interpreted, and handled by DLGaaS, the following StreamOutput is returned:
.
# StreamOutput
{
"response": {
"payload": {
"messages": [],
"qa_action": {
"message": {
"nlg": [{
"text": "What size coffee would you like? "
}
],
"visual": [{
"text": "What size coffee would you like?"
}
],
"audio": [] // This is a reference to an audio file.
}
}
}
}
}
Handling unusable ASR audio
DLGaaS handles unusable ASR audio as follows:
- If ASRaaS returns a status code of 204 or 404 (that is, no audio was provided or recognition could not provide a result), the Dialog engine treats this as NO_INPUT. For a description of the ASR status codes, please see Status messages and codes in the ASRaaS documentation.
- If audio was provided but was not recognized, ASRaaS sends a status code of 200 (Success), with a
rejectedhypothesis. This is treated as a NO_MATCH by the NLU and dialog engines.
By default, if ASRaaS does not return a valid hypothesis, the dialog flow is determined by the dialog application, according to the processing defined for the NO_INPUT and NO_MATCH events in Mix.dialog.
In some cases, you may want the client application to handle the dialog flow if a valid hypothesis is not returned. This is done by setting the end_stream_no_valid_hypotheses parameter of the StreamInput asr_control_v1 message to true. When this is enabled, the stream is closed and the last StreamOutput message contains the ASR result in the asr_result field. The client application is then responsible for determining the next step in the dialog flow.
Handling DTMF input in IVR applications
For Interactive Voice Response (IVR) applications, you may also want to use Dual-tone multi-frequency (DTMF) inputs, for example from a telephone keypad.
This could include single key inputs that correspond to one of a set of options, for example, for a menu, as defined by a DTMF mapping in Mix.dialog. It could also include a sequence of key inputs, for example to key in an account or identification number, to be interpreted by an external DTMF grammar referenced in Mix.dialog.
DTMF inputs can be handled by an integration between Mix.dialog and Nuance Speech Suite using Nuance VoiceXML Connector. Speech Suite uses DTMF mappings or DTMF grammars from Dialog to interpret DTMF input in terms of Dialog entities. It then returns the interpretation of the input to the Dialog service to advance the dialog.
For more details on such integrations and on configuring Mix.dialog to handle DTMF inputs, see Mix tips for IVR developers.
Generating synthesized speech output
Generation of synthesized speech output can be performed either by the Nuance Mix Platform (TTSaaS) or by an third party text to speech system. Speech synthesis carried out by Nuance TTSaaS can either be orchestrated by Dialog or by the client application.
Synthesizing an audio output message using TTS with Dialog orchestration
- The client application sends a StreamInput message with the tts_control_v1 and request parameters to DLGaaS.
The dialog application continues the dialog according to the ExecuteRequest provided in the request parameter. - If the dialog is configured to support the TTS modality, speech audio for the text is synthesized and the audio is streamed back to the application in a series of StreamOutput messages.
Note: When DLGaaS calls TTSaaS through the StreamInput request, it specifies the ssml input type, which lets you use SSML tags to tune the synthesized TTS output. For more information about SSML tags, see the TTSaaS documentation.
For example, assuming that the user typed "I want an espresso", the client application will send a single StreamInput method with the following content:
# StreamInput
{
"request": {
"session_id": "1c2c9822-45d5-460d-8696-d3fa9d8af8c2",
"selector": {
"channel": "default"
"language": "en-US"
"library": "default"
},
"payload": {
"user_input": {
"user_text": "I want an espresso"
}
},
},
"tts_control_v1": {
"audio_params": {
"audio_format": {
"pcm": {
"sample_rate_hz": 16000
}
}
}
}
}
Once user text has been interpreted and handled by DLGaaS, the following series of StreamOutput is returned:
Note: The StreamOutput includes the audio field because a TTS message was defined (as shown in the nlg field). If no TTS message was specified, no audio would have been returned.
# First StreamOutput
{
"response": {
"payload": {
"messages": [],
"qa_action": {
"message": {
"nlg": [{
"text": "What size coffee would you like? "
}
],
"visual": [{
"text": "What size coffee would you like?"
}
],
"audio": []
}
}
}
},
"audio": "RIFF4\373\000\00.."
}
# Additional StreamOutputs with audio bytes
{
"audio": "...audio_bytes..."
}
TTS with orchestration by client app
Self-hosted environments: This feature requires version 1.3 of the Dialog service. The VoiceXML Connector does not support this feature.
To support alternate solutions for text to speech, DLGaaS provides the current conversation language and the TTS voice settings configured in Mix.dialog for the response messages as part of ExecuteResponse payload messages. The active language lets the client application know which language to generate speech for. The voice information lets the client application know, if you are using Mix TTSaaS, which Nuance voice profile to request as part of a TTSaaS SynthesisRequest.
Language and TTS voice parameters
{
"payload": {
"messages": [],
"qa_action": {
"message": {
"nlg": [{
"text": "What type of coffee would you like?"
}
],
"visual": [{
"text": "What <b>type</b> of coffee would you like? For the list of options, see the <a href=\"www.myserver.com/menu.html\">menu</a>."
}
],
"language": "en-us",
"tts_parameters": {
"voice": {
"name": "Evan",
"model": "enhanced",
"gender": "MALE",
"language": "en-us"
}
}
}
}
}
}
The nlg text contents of ExecuteResponse payload messages provide the text input to pass to TTSaaS if you are doing your own orchestration. Otherwise, it provides a text backup if TTSaaS fails.
Note that there are some important points to remember in your design and configuration in Mix.dialog:
- In your dialog designs, avoid changing the active language mid-flow between collection states, since messages are concatenated in the ExecuteResponse. To ensure messages will play in the intended language, you can set the language variable in the System Actions section of a question and answer node for example. All messages after the collection step will be in the new active language.
- Make sure that the TTS voice settings configured in Mix.dialog are valid in your target deployment environment. See Configure TTS settings for more information.
Performing both speech recognition and TTS in a single call
- The client application sends the StreamInput method with the asr_control_v1, tts_control_v1, and request parameters to DLGaaS; this lets DLGaaS know to expect audio.
- The client application streams the audio with the StreamInput method.
The audio is recognized, interpreted, and returned to the dialog application, which continues its flow. If the corresponding ExecuteResponse includes a TTS message, this message is synthesized and the audio is streamed back to the application in a series of StreamOutput calls.
Note about performing speech recognition and TTS in a dialog application
The speech recognition and TTS features provided as part of the DLGaaS API should be used in relation to your Mix.dialog, that is:
- To perform recognition on a spoken user input provided in answer to a question and answer node
- To synthesize TTS output audio corresponding to
messagetext for the agent response returned to the user
To perform recognition or TTS outside of a Mix.dialog, please use the following services:
- For speech recognition, see the ASR as a Service gRPC API documentation.
- For TTS, see the TTS as a Service gRPC API documentation.
Providing speech response using recorded speech audio
TTS synthesized speech is one way to provide speech responses in voice or omni-channel applications. Another option is to use recorded audio files.
This second option is available when an Audio Script message has been defined in Mix.dialog for the interaction. When using this option, you need to pre-record and store speech audio files within the client application. In this case, the StreamOutput response from DLGaaS includes, within the payload of its response field, local URI references for the appropriate audio file(s) to retrieve and play .
The message contents of both the messages and qa_action fields in the payload contain an audio field with one or more Message.Audio messages. The contents give details for recorded audio versions of the message contents. Message.Audio contains two key fields:
uri: string that indicates the name and local path in the application to find the appropriate recorded audio filetext: provides text for TTS backup is there is no audio file or the audio file cannot be played or found
Audio files and naming
Dialog expects recorded audio files related to a message to have file names derived systematically from the Audio File ID, or, if that is not specified, from the Message ID in Mix.dialog. How the file names are specified depends on whether the message is static or dynamic.
Static message audio file naming
Static messages have fixed contents and are the same every time they are used. An example of this is a standard greeting message or question posed routinely to the user.
For example, suppose in a banking application, the application sends an initial greeting message with a question to open the interaction, as follows:
"Welcome to your personal banking app. How may I help you today?"
In the case of a static message, the client application receives a payload message with one Message.Audio entry providing reference to a single audio file. Only one file is needed because the contents are fixed and can be recorded in one piece. If an Audio File ID is available, the file name is of the form Audio_File_ID. If only a Message ID is available, the file will instead be named Message_ID.
For the example above, the following payload message audio field contents would be returned:
#StreamOutput
{
"response": {
"payload": {
"messages": [],
"qa_action": {
"message": {
"visual": [{ "text": "Welcome to your personal banking app. How may I help you today?"}],
"audio": [{"text": "Welcome to your personal banking app. How may I help you today?", "uri": "en-US/prompts/default/IVRVoiceVA/welcomeAudio.wav?version=1.0_1612217879954"}]
}
}
}
}
}
Dynamic message audio file naming
Dynamic messages have all or part of the message depending on the value of session variables. As such, the full contents of the message are only knowable at runtime.
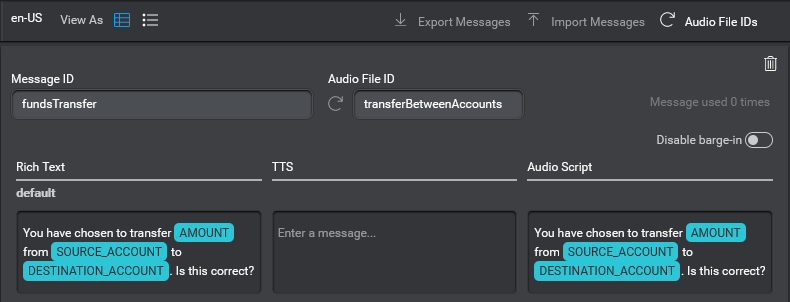
For example, suppose that in a banking application you want to read back the details of the requested transaction to the user and get their confirmation. So in the case of a funds transfer scenario, the message might be defined in Mix.dialog as follows:
"You have chosen to transfer AMOUNT from SOURCE_ACCOUNT to DESTINATION_ACCOUNT. Is this correct?"
Here, AMOUNT, SOURCE_ACCOUNT, and DESTINATION_ACCOUNT are placeholders for values of variables only known at runtime based on what the user says. The rest of the message is static content that is always the same.
In the case of a dynamic message with placeholders for variable values, the message is broken into parts representing the different static and dynamic segments in the message. The client application receives a payload message with multiple Message.Audio entries providing reference to either static audio files or fallback text for TTS.
Suppose that at runtime, you have:
- AMOUNT="$500"
- SOURCE_ACCOUNT="chequing"
- DESTINATION_ACCOUNT="savings"
The message breaks down into seven segments, alternating between static and dynamic content:
- You have chosen to transfer (static)
- $500 (dynamic)
- from (static)
- chequing (dynamic)
- to (static)
- savings (dynamic)
- Is this correct? (static)
Seven audio entries are sent within the response payload representing the static and dynamic segments.
If the message has an Audio File ID transferBetweenAccounts, and .wav was set as the desired audio file format in Mix.dialog, then Mix.dialog would expect four recorded audio files corresponding to the four static segments with file names:
- transferBetweenAccounts_01.wav for "you have chosen to transfer"
- transferBetweenAccounts_03.wav for "from"
- transferBetweenAccounts_05.wav for "to"
- transferBetweenAccounts_07.wav for "Is this correct?"
Here the numbers added to the end of the file name correspond to the segment number within the message.
For the dynamic segments, text is provided so that the client application can make a runtime request for TTS audio.
Here's the payload message audio field contents for the same example:
# StreamOutput
{
"response": {
"payload": {
"messages": [],
"qa_action": {
"message": {
"visual": [{ "text": "You have chosen to transfer $500 from checking to savings. Is this correct?"}],
"audio": [
{"text": "You have chosen to transfer", "uri": "en-US/prompts/default/IVRVoiceVA/transferBetweenAccounts_01.wav?version=1.0_1612217879954"},
{"text": "$500"},
{"text":"from", "uri": "en-US/prompts/default/IVRVoiceVA/transferBetweenAccounts_03.wav?version=1.0_1612217879954"},
{"text": "chequing" },
{"text": "to", "uri": "en-US/prompts/default/IVRVoiceVA/transferBetweenAccounts_05.wav?version=1.0_1612217879954" },
{"text": "savings" },
{"text": "Is this correct?", "uri": "en-US/prompts/default/IVRVoiceVA/transferBetweenAccounts_07.wav?version=1.0_1612217879954" }
]
}
}
}
}
}
For the static segments with URIs, the client application can try to retrieve the audio files at the expected location. For the dynamic segments with only text, the client application would need to obtain synthesized speech by sending the text segments to TTS.
Once the recorded audio files and the TTS audio files are all obtained, the client application can play the audio for the message together.
DynamicMessageReference
DynamicMessageReference is a predefined variable schema in Mix.dialog used for audio messages.
This schema includes two fields:
audioFileName: URI with local path and file name, with file extension includedttsBackup: Alternative text for TTS when the audio file is unavailable.
To use this, do the following in Mix.dialog:
- Create a variable based on this schema
- Create a data access node to obtain the field values for the variable at runtime from the client application or a backend data source
- Put the variable as a dynamic placeholder under Audio Script modality in the message definition in Mix.dialog.
At runtime, Mix.dialog gets the audioFileName and ttsBackup from the data source, and sends this to the client application as part of a response payload Message.Audio. There, it can be handled similarly to the case of a static message audio file.
TTS backup
In any case where either no URI is provided for a segment of the message or the audio file is not available at runtime, the backup text can be used to generate audio via TTS. The client application needs to make a separate request to TTS to generate speech for that text.
Dynamic concatenated audio
When Mix dialogs are driven by VoiceXML applications, Audio script messages for certain supported languages are played using audio files from dynamic concatenated audio packages. In this case, speech audio for both static and dynamic content is put together and played from recorded concatenated audio files with intonation and formatting driven by message formatting applied in Mix.dialog. For more information see Dynamic concatenated audio playback options.
Wordsets
This reference topic clarifies the use of inline wordsets to improve Dialog's ability to make sense of user inputs.
What is a wordset?
In ASRaaS and NLUaaS, wordsets are used to help boost performance of recognition and interpretation of values for dynamic list entities. Dynamic list entities are list entities where the entity can take on several different values, and where the set of possible values can only be fully specified at runtime. Wordsets are collections of words brought in at runtime to dynamically specify the allowed values for one or more entities. In DLGaaS, wordsets are passed in to data access nodes using dynamic entity data variables.
Use cases for wordsets
There are two different scenarios where wordsets can be useful:
- Values personalized to or configured by the user, for example a banking customer's list of cash transfer payees
- Values specified by the application relevant to the current session, for example the specific drinks currently available from a coffee shop chain in the user's location
Wordsets improve performance for interpretation and recognition by more completely delineating the possible values that ASRaaS and NLUaaS should expect to encounter in the present context for specified entities.
Inline vs compiled wordsets in ASRaaS and NLUaaS
In ASRaaS and NLUaaS, wordsets can be passed to the service in one of two ways:
- Inline
- Compiled
Inline wordsets are used for entities with a modest number of possible values (No more than 100 total items). Inline wordsets are:
- Passed in at runtime along with ASRaaS RecognitionRequest and NLUaaS InterpretRequest messages as resources
- Compiled at runtime
- Used as aids for making sense of user inputs.
Compiled wordsets are used in ASRaaS and NLUaaS for entities with a large number of possible values (hundreds to thousands of values). Examples of this could include, for example, all of a person's personal contacts, the staff directory of a large hospital, or a list of possible medication names.
Because of the size of these wordsets, trying to pass them in to be compiled at runtime adds undesirable or impractical amounts of latency. As a solution, ASRaaS and NLUaaS provide APIs to compile wordsets ahead of time. The Training API in ASRaaS and the Wordset API in NLUaaS provide this functionality. Once compiled, the wordsets can be referenced by URN at runtime using the regular runtime APIs of each service. This reduces the amount of latency added by using the wordset.
For details on using compiled wordsets, see Referencing compiled resources. The rest of this section focuses on how to use inline wordsets.
Passing inline wordsets: client-side vs server-side
Inline wordsets and server-side data integration
Client-side data integration
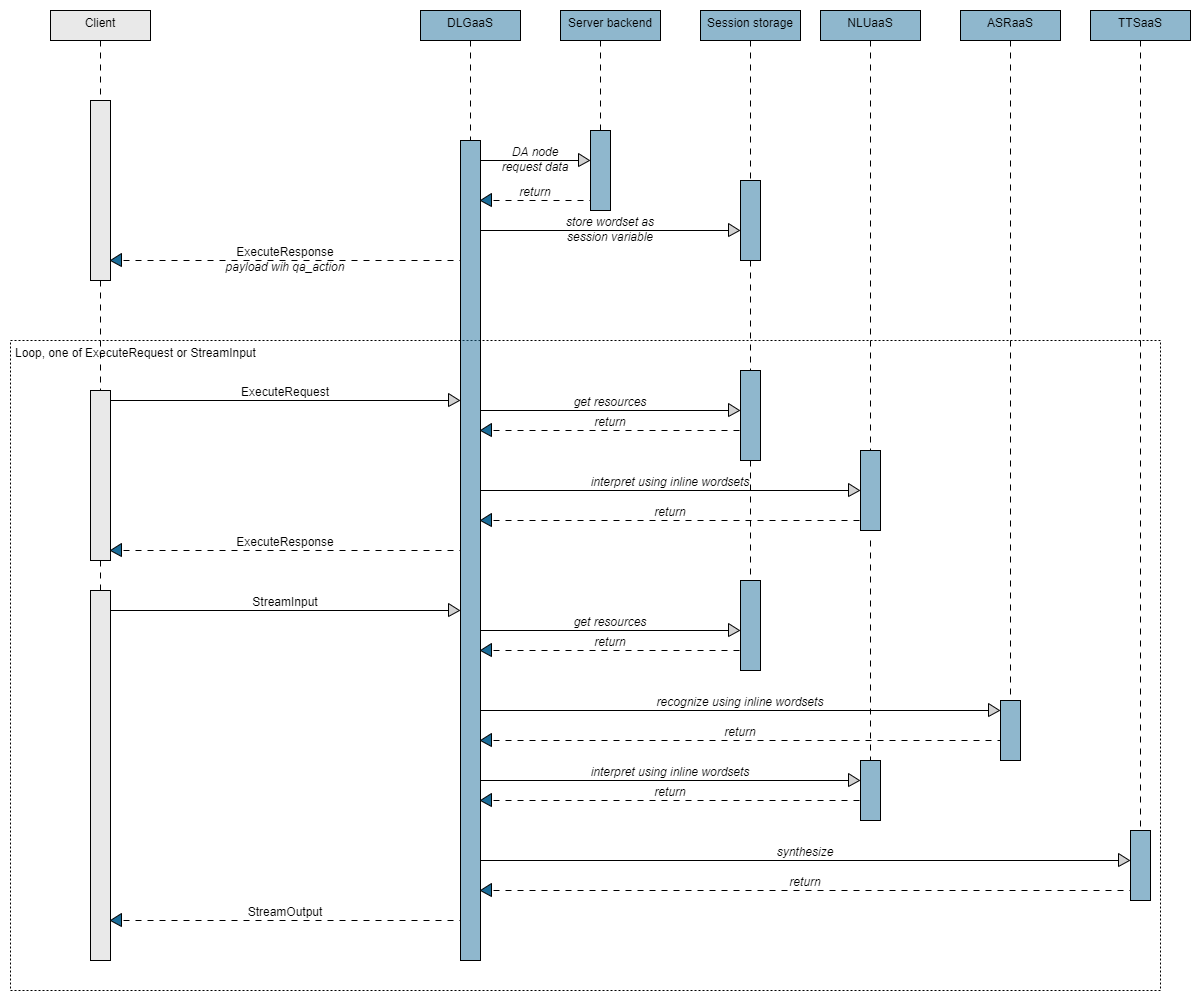
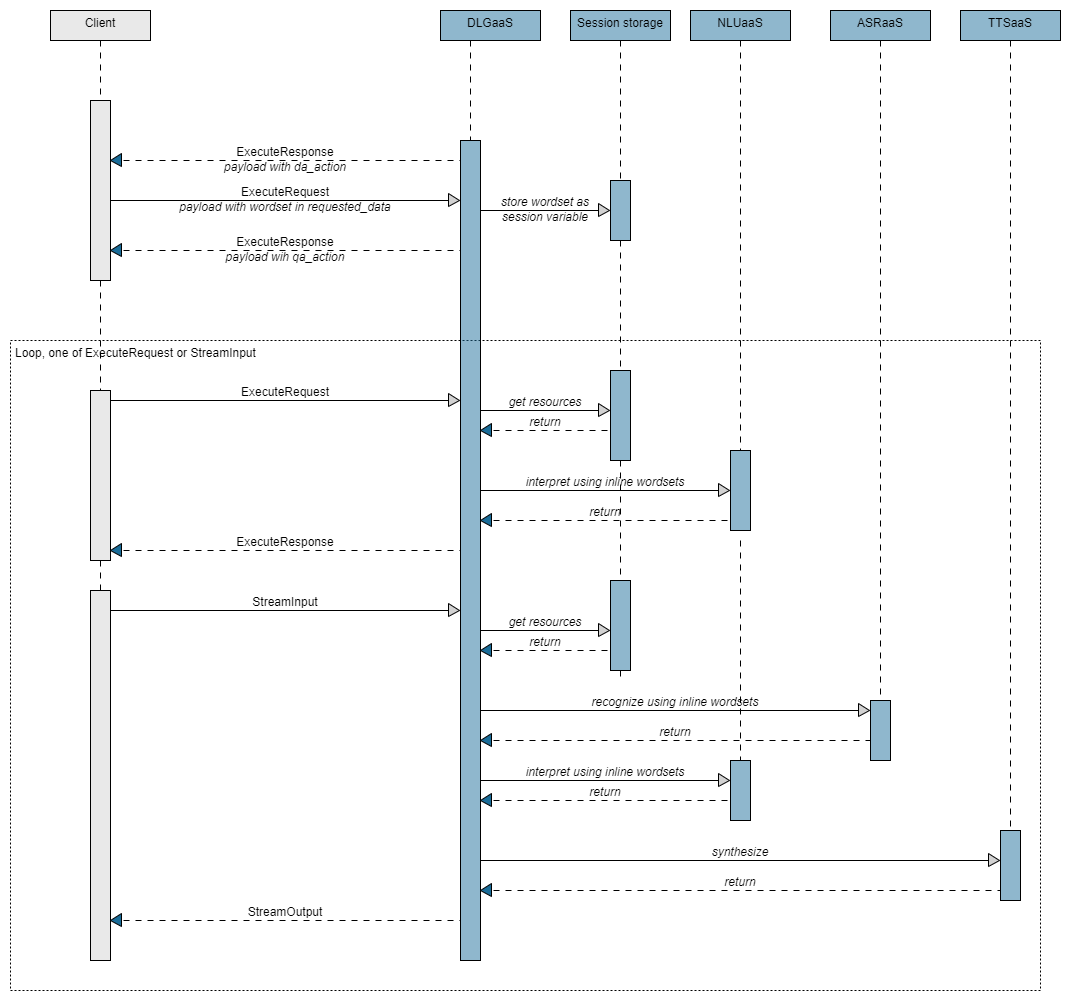
In DLGaaS, inline wordsets can be passed into the session at runtime through data transfers from external systems. This could either be from the client application or from a server-side data connection. For example:
- Using a Dialog data access node with either server-side integration or client-side integration (data access action in DLGaaS API)
- Through the data field in the payload of a StartRequest
When inline wordsets are used with Dialog, the accuracy and confidence levels for recognition and interpretation of dynamic list entities are boosted. This improves the overall ability of the Dialog to understand what your users want to do and route the Dialog accordingly to fulfill that intent.
Using wordsets with Dialog
To use inline wordsets with Dialog:
- Define one or more dynamic list entities in Mix.dialog or Mix.nlu by creating list entities and marking them as dynamic.
- Add at least a few initial values and literals for the each dynamic list entity in Mix.dialog or Mix.nlu.
- In Mix.nlu, for each dynamic list entity, create some annotated samples containing the entity, and train your NLU model.
- Create a new dynamic entity data variable in Mix.dialog. Note: Dynamic entity data objects are classified as simple objects in Mix.dialog.
- If a data access node is to be used for the data exchange, create and configure a data access node in Mix.dialog to get the dynamic entity data variable created earlier. The data access node also needs to be configured for either client-side or server-side integration with the data source.
- Create a question and answer node in Mix.dialog to collect your dynamic list entity.
- Set up your data source, whether server-side or client-side, to provide the dynamic entity data variable containing the wordset data to the data access node.
Wordsets schema
The inline wordset data is passed in the form of a dynamic entity data variable object.
A dynamic entity data variable contains one field, variable_name. This corresponds to the name of the variable created in Mix.dialog and configured to be collected by a data access node. The value for this field is a dynamic entity data object.
A dynamic entity data object contains a wordset for boosting one or more dynamic list entities. It has one or more fields with names of the form entity_name. Here, each entity_name corresponds to the name of one dynamic list entity that is being provided with values. The value for each entity_name field is an array of dynamic entity data items. Each dynamic entity data item describes one value for the corresponding dynamic list entity. In DLGaaS, the following fields can be used:
| Element | Type | Description | Used by |
|---|---|---|---|
canonical |
String | The value of the entity | ASR, NLU, DLG |
literal |
String | The written or spoken form of the value; doubles as the value when canonical is omitted | ASR, NLU, DLG |
spoken |
Array | (Optional) One or more additional spoken forms of the value—used by ASR; ignored for NLU | ASR |
label |
String | (Optional) A label, such as the text to show on a button | DLG |
image_url |
String | (Optional) A link (URL or relative path) for the image to use on a button | DLG |
description |
String | (Optional) A description | DLG |
As can be seen in the table, some of these fields are used by NLU and/or ASR, while others are used only by DLG. label, image_url, and description are used in DLGaaS only to identify how to display the options in an interactive element.
The example below shows the format for a dynamic entity data variable object holding a cold drinks wordset for a coffee shop application.
Here moreCoffeeTypes is the dynamic entity data variable set in Dialog.
COFFEE_TYPE is an entity to be boosted with a wordset. Associated with this is an array. The two entries within the array hold details related to two possible values for the entity, cold brew coffee and iced cappuccino.
{
"moreCoffeeTypes":
{
"COFFEE_TYPE":
[
{
"canonical": "cold_brew",
"literal": "cold brew",
"spoken":
[
"cold brew"
],
"label": "Cold brew coffee",
"image_url": "https://www.cafeitalia.com/images/drinks.cold/cold_brew.png",
"description": "Cafe Italia's famous and refreshing cold brew coffee. Great for summer."
},
{
"canonical": "ice_capp",
"literal": "iced cappuccino",
"spoken":
[
"iced kapucheeno",
"iced kapacheeno"
],
"label": "Iced cappuccino",
"image_url": "https://www.cafeitalia.com/images/drinks/cold/ice_cap.png",
"description": "A frosty, slushy burst of coffee to beat the heat."
}
]
}
}
For more information, see Dynamic entity data specification.
Set up your data source
Your data source provides the wordset data to a data access node. The data source can use either server-side integration or client-side integration.
Server-side integration
Set up a RESTful endpoint at the server URL specified in the data access node. The endpoint will take in the specified inputs and return the specified dynamic entity data variable according to the the Wordsets schema.
For details on how to do this, see Exchanging data from the dialog application.
Client-side integration
Set up a script in your client application to handle the data access action. This script takes in specified inputs and returns the specified dynamic entity data variable according to the the Wordsets schema.
For details on how to do this, see Data access actions.
Behind the scenes behavior
Once the dynamic entity data variable is pulled into Dialog, it is available afterwards during the session for as long as needed.
Whenever a call to ASRaaS and/or NLUaaS is triggered by a DLGaaS ExecuteStream or Execute request, the wordset contained in the dynamic entity data variable will be added to the call.
For each such call to ASRaaS or NLUaaS, the dynamic entity data object is extracted from the dynamic entity data variable object, and added by Dialog as an inline wordset resource.
Recommendations/best practices
Wordsets with multiple different dynamic list entities can be passed into Dialog for use during the session.
If you're unsure about the size of your inline wordset, test the latency.
For more details on setting up wordsets in Mix.dialog, see Dynamic list entities.
Referencing compiled resources
Self-hosted environments: Use of the ExternalResourceReferences variable requires version 1.1 (or later) of the Dialog service. IVR applications using the Speech Suite platform with VoiceXML Connector do not yet support fetching external NLU and ASR resources. Projects using the Speech Suite platform only support inline wordsets.
This reference topic clarifies the use of compiled resources by reference to improve Dialog's ability to make sense of user speech and text inputs.
As mentioned in the wordsets section, the APIs of NLUaaS and ASRaaS allow you to compile resources ahead of time and then reference these resources by URN at runtime. The resources are then shared with ASRaaS and NLUaaS to improve recognition and interpretation.
DLGaaS supports passing in ASRaaS and NLUaaS references at runtime to be used by calls made by DLGaaS to ASRaaS and NLUaaS. This is accomplished using a session variable called ExternalResourceReferences.
Types of resources
The following types of resources can be referenced using an ExternalResourceReferences variable.
| Service | Resource type | Description | URN format |
| NLU |
COMPILED_WORDSET (app-level) |
App-level NLU compiled wordset. Provides values for a dynamic list entity relevant to all users of the app. | urn:nuance-mix:tag:wordset:lang/context_tag/name/lang/mix.nlu |
| COMPILED_WORDSET (user-level) |
User-level NLU compiled wordset. Provides values for a dynamic list entity specific to the current user. | urn:nuance-mix:tag:wordset:lang/context_tag/name/lang/mix.nlu?=user_id=user_id | |
| ASR |
COMPILED_WORDSET (app-level) |
App-level ASR compiled wordset. Provides values for a dynamic list entity relevant to all users of the app. | urn:nuance-mix:tag:wordset:lang/context_tag/name/lang/mix.asr |
| COMPILED_WORDSET (user-level) | User-level ASR compiled wordset. Provides values for a dynamic list entity specific to the current user. | urn:nuance-mix:tag:wordset:lang/context_tag/name/lang/mix.nlu?=user_id=user_id | |
| DOMAIN_LM | ASR domain language model. Additional model that supplements a base language model and improves performance recognizing speech using specialized terms common to a specific knowledge domain but rare in everyday speech. | urn:nuance-mix:tag:model/context_tag/mix.asr?=language=lang | |
| SETTINGS | ASR settings. |
urn:nuance-mix:tag:setting/context_tag/asr |
|
| SPEAKER_PROFILE | ASR speaker profile for the current user_id. Contains data that improves recognition performance for the current user based on qualities of the speaker and channel. | N/A |
For the URNs:
- context_tag is an application context tag from Mix
- name is a name for the resource
- lang is the six-letter language and country code for which the wordset applies. For example,
eng-USA. - userId is a unique identifier for the user
Note that speaker profiles do not need a URI. Speaker profiles are specified by the current user_id, which is passed in with requests in the DLGaaS API.
For more information on recognition and interpretation resources, see:
Passing in ExternalResourceReferences
ExternalResourceReferences can be passed into Dialog in three different ways:
- Via a data access node, using either client-side or server-side data access
- Via an external actions node using a Transfer action
- Via the data field in the payload of a StartRequest
- Via the data field in the payload of a UpdateRequest
Using compiled resources with Dialog
To use compiled resources by reference with Dialog:
- If using compiled wordset resources:
- Define one or more dynamic list entities in Mix.dialog or Mix.nlu by creating list entities and marking them as dynamic.
- Add at least a few initial values and literals for the each dynamic list entity in Mix.dialog or Mix.nlu.
- In Mix.nlu, for each dynamic list entity, create some annotated samples containing the entity, and train your NLU model.
- If applicable, create and configure a data access node or an external actions node of Transfer action type with the predefined ExternalResourceReferences variable as a get data parameter to fetch references to the compiled resources.
- Create a question and answer node in Mix.dialog to collect your inputs on which the compiled resources will be applied.
- If using a data access node or external actions node, set up a data source to provide the value for the ExternalResourceReferences variable to be sent to Dialog.
ExternalResourceReferences schema
The value of ExternalResourceReferences is an object with two fields:
- NLUResources: A list of NLU resource reference entries
- ASRResources: A list of ASR resource reference entries
Each resource entry can have up to three fields:
- uri (required, except for speaker profiles): URN for the resource. Speaker profiles do not require a URN, because they are based on the current user_id, which is passed into the session as part of a StartRequest or UpdateRequest.
- resourceType (required): The type of resource as described in the types of resources above.
- weightValue (optional): Relative weighting to give to the resource in comparison to other resources. See Resource weights in the ASRaaS documentation for more details.
The code sample below shows the format of an ExternalResourceReferences object. See above for the details that need to be specified for each URN to identify the resource.
{
// Resources to improve NLU interpretation
"NLUResources": [
{
// NLU compiled wordset
"uri": "urn:nuance-mix:tag:wordset:lang/contextTag/resourceName/lang/mix.nlu?=user_id=userId",
"resourceType": "COMPILED_WORDSET"
}],
// Resources to improve ASR recognition
"ASRResources": [
{
// ASR compiled wordset
"uri": "urn:nuance-mix:tag:wordset:lang/contextTag/resourceName/lang/mix.asr",
"resourceType": "COMPILED_WORDSET"
},
{
// ASR domain language model
"uri": "urn:nuance-mix:tag:model/contextTag/mix.asr?=language=lang",
"resourceType": "DOMAIN_LM",
"weight_value": 0.7
},
{
// ASR speaker profile
"resourceType": "SPEAKER_PROFILE"
},
{
// ASR settings
"uri": "urn:nuance-mix:tag:settings/names-places/asr",
"resourceType": "SETTINGS"
}]
}
Use of ExternalResourceReferences
As with other session variables, once the set of resources is set, they will be available for use for the remainder of the session. DLGaaS will add references to these resources in any subsequent calls to ASRaaS and NLUaaS
Updating ExternalResourceReferences values
If the client application passes in a value for the ExternalResourceReferences variable again, this will overwrite the earlier values, and the new values will be used from that point forward.
Exchanging session data
In addition to data requested by data access actions, you can send data from the client application to the Dialog service with the following methods:
- StartRequest to send data at the beginning of a session
- UpdateRequest to update data once a session has started
This data can include:
- The userData predefined variable
- Variables defined in Mix.dialog
userData predefined variable
Example: StartRequest payload with session data
{
"selector":
{
"channel": "default",
"language": "en-US",
"library": "default"
},
"payload":
{
"data":
{
"userData":
{
"timezone": "America/Cancun",
"userGlobalID": "123123123",
"userChannelID": "163.128.3.254",
"userAuxiliaryID": "7319434000843499",
"systemID": "4561 9219 9923",
"location":
{
"latitude": "21.161908",
"longitude": "-86.8515279"
}
},
"preferred_coffee": "espresso",
"user_name": "Miranda"
}
}
}
Example: UpdateRequest payload with session data
{
"session_id": "27f8e613-f624-429b-8c11-d2465dbc2692",
"payload":
{
"data":
{
"userData":
{
"timezone": "America/Cancun",
"userGlobalID": "123123123",
"userChannelID": "163.128.3.254",
"userAuxiliaryID": "7319434000843499",
"systemID": "4561 9219 9923",
"location":
{
"latitude": "21.161908",
"longitude": "-86.8515279"
}
},
"preferred_coffee": "cappucino",
"user_name": "Sam"
}
}
}
All dialog projects include the userData predefined variable, which can be set in the StartRequest payload or in the UpdateRequest payload to provide end user data such as the user's timezone, location, and so on.
The JSON code shows an example of how to pass userData in the StartRequest and UpdateRequest payloads. This data can then be used in the dialog application.
For a description of the userData variable, see userData schema in the Mix.dialog documentation.
Variables defined in Mix.dialog
You can set variables that were previously defined in Mix.dialog in the StartRequest or UpdateRequest. For example, let's say that the user name and preferred coffee are stored on the user's phone, and you'd like to use them in your dialog application to customize your messages:
- System: Hey Miranda! What can I do for you today?
- User: I'd like my usual.
- System: Perfect, a double espresso coming up!
To implement this scenario:
- Create variables in Mix.dialog (for example,
user_nameandpreferred_coffee). See Manage variables in the Mix.dialog documentation for details. - Use the variables in the dialog; for example, the following message node includes the
user_namevalue in the initial prompt:
- Send the values of
user_nameandpreferred_coffeeas key-value pairs in the StartRequestPayload or UpdateRequestPayload.
The dialog app can then include the user name in the next prompt:
{
"payload": {
"messages": [],
"qa_action": {
"message": {
"nlg": [],
"visual": [
{
"text": "Hello Miranda ! What can I do for you today?"
}
],
"audio": []
}
}
}
}
Note: The variable values need to be sent in the expected format and range of expected values. If they are not, the variable value will not be updated. For example, the language session variable expects a four character language and country code combination from the set of languages configured in the project, for example en-US. So, for example, trying to set a language not supported by the project, or using an incorrect format like en will not result in an update to the language variable.
Simple variable types
Simple variables created in Mix.dialog are of a specified type. When you send a variable, whether in the StartRequest payload or in a data access action, you must make sure to send the data in the right format so that it can be used by the dialog application.
This table lists the types of simple variables and describes how to send them to the dialog application. The JSON code then shows examples of how to pass this type of data in a data access action.
For more information, see Variable types in the Mix.dialog documentation.
{
"selector": {
"channel": "default",
"language": "en-US",
"library": "default"
},
"payload": {
"requested_data": {
"id": "DataAccess",
"data": {
"returnCode": "0",
"sampleString": "This is a sample string",
"sampleAlphanumeric": "1-2 This is an alphanumeric string.",
"sampleDigits": "12",
"sampleBoolean": "true",
"sampleInt": 27,
"sampleDecimal": 12.34,
"sampleAmount": {
"unit": "USD",
"number": 10.5
},
"sampleDate": "202001014",
"sampleTime": "1212a",
"sampleDistance": {
"modifier": "LE",
"unit": "km",
"number": 10
},
"sampleTemperature": {
"unit": "C",
"number": 32
}
}
}
}
}
| Variable type | Description |
|---|---|
| String | String of characters |
| Alphanumeric | String of alphanumeric characters (a-z, A-Z, 0-9) |
| Digits | String of digits (0-9) |
| Boolean | Boolean (true, false) |
| Integer | Whole number |
| Decimal | Decimal-point number |
| Amount | Amount, including currency. Specify the amount in an object with the following elements:
|
| Date | Date (YYYYMMDD) |
| Time | Time. Specify as a string using the format HHMMx, where x is one of the following:
|
| Distance | Distance, including unit and modifier. Specify the distance in an object with the following elements:
unit and modifier values supported. |
| Temperature | Temperature, including unit. Specify the temperature in an object with the following elements:
unit values supported. |
Disabling logging
Sensitive flagging and partial redaction
By default, the values of any entities and variables marked as 'sensitive' in Mix.dialog and Mix.nlu are redacted for Dialog and NLU payload logs in the Nuance Mix runtime event logs. This is called partial redaction. The content of the text exchanges for both sides of the conversational will be partially readable, but traces of sensitive information are redacted.
Complete redaction
If you want to suppress logging of the contents of conversations more broadly and completely, set the suppress_log_user_data flag in the StartRequestPayload to True. This completely disables logging of the contents of the conversation for Dialog, and, whenever the other services are orchestrated by Dialog, this also triggers corresponding flags to suppress logging of contents in ASR, NLU, and TTS. This is the master redact button when you want the event logs to remember nothing of the words or data transmitted during the conversation.
- For Dialog, this disables all logging of the text content of both sides of the conversation.
- For calls to ASR, Dialog sets the
suppress_call_recordingRecognitionFlags field to True to disable call logging. See the ASRaaS RecognitionFlags documentation for details. - For calls to NLU, Dialog sets the
interpretation_input_logging_modeInterpretationParameters field to SUPPRESSED. See the NLUaaS InterpretationParameters documentation for details. - For calls to TTS, Dialog sets the
suppress_inputEventParameters field to True to omit input text and URIs from log events. See the TTSaaS EventParameters documentation for details.
See Managing sensitive information in an application in the Nuance Mix Runtime Event Logs documentation for more details.
User ID
You can specify a user ID in the StartRequest, ExecuteRequest, UpdateRequest, and StopRequest. This user ID is converted into an unreadable format and stored in call logs and user-specific files. It can be used for:
- General Data Protection Regulation (GDPR) compliance: Logs for a specific user can be deleted, if necessary.
- Performance tuning: User-specific voice tuning files and NLU wordsets (such as contact lists) can be saved and used to improve performance.
Note: The user_id value can accept any UTF-8 characters.
gRPC API
Dialog as a Service provides three protocol buffer (.proto) files to define the Dialog service for gRPC. These files contain the building blocks of your dialog applications:
- The dlg_interface.proto file defines the main DialogService interface.
- The dlg_messages.proto file defines the main DialogService methods.
- The dlg_common_messages.proto file defines the objects used in the methods.
Once you have transformed the proto files into functions and classes in your programming language using gRPC tools, you can call these functions from your client application to start a conversation with a user, collect the user's input, obtain the action to perform, and so on.
See Client app development for a scenario using Python that provides an overview of the different methods and messages used in a sample order coffee application. For other languages, consult the gRPC and Protocol Buffer documentation:
Field names in proto and stub files
In this section, the names of the fields are shown as they appear in the proto files. To see how they are generated in your programming language, consult your generated files. For example:
| Proto file | Python | Go | Java | |
|---|---|---|---|---|
| session_id | → | session_id | SessionId | sessionId or getSessionId |
| selector | → | selector | Selector | selector or setSelector |
For details, see the Protocol Buffers documentation for:
Python: https://developers.google.com/protocol-buffers/docs/reference/python-generated#fields.
Go: https://developers.google.com/protocol-buffers/docs/reference/go-generated#fields
Java: https://developers.google.com/protocol-buffers/docs/reference/java-generated#fields
Proto files structure
Structure of DLGaaS proto files
DialogService
Start
StartRequest
StartResponse
Status
StatusRequest
StatusResponse
Update
UpdateRequest
UpdateResponse
Execute
ExecuteRequest
ExecuteResponse
ExecuteStream
StreamInput
StreamOutput
Stop
StopRequest
StopResponseStartRequest
session_id
selector
channel
language
library
payload
model_ref
uri
type
data
suppress_log_user_data
session_timeout_sec
user_id
client_dataStartResponse
payload
session_idStatusRequest
session_idStatusResponse
session_remaining_secUpdateRequest
session_id
payload
client_data
user_idExecuteRequest
session_id
selector
channel
language
library
payload
user_text
interpretation
confidence
input_mode
utterance
data
key
value
slot_literals
key
value
slot_formatted_literals
key
value
slot_confidences
key
value
alternative_interpretations
selected_item
id
value
nluaas_interpretation
input_mode
dialog_event
type
message
event_name
requested_data
id
data
user_idExecuteResponse
payload
messages
nlg
text
mask
barge_in_disabled
visual
text
mask
barge_in_disabled
audio
text
uri
mask
barge_in_disabled
view
id
name
language
tts_parameters
voice
qa_action
message
nlg
text
mask
barge_in_disabled
visual
text
mask
barge_in_disabled
audio
text
uri
mask
barge_in_disabled
view
id
name
language
tts_parameters
voice
data
view
id
name
selectable
selectable_items
value
id
value
description
display_text
display_image_uri
recognition_settings
dtmf_mappings
collection_settings
speech_settings
dtmf_settings
mask
da_action
id
message
nlg
text
mask
barge_in_disabled
visual
text
mask
barge_in_disabled
audio
text
uri
mask
barge_in_disabled
view
id
name
language
tts_parameters
voice
view
id
name
message_settings
delay
minimum
data
escalation_action
message
nlg
text
mask
barge_in_disabled
visual
text
mask
barge_in_disabled
audio
text
uri
mask
barge_in_disabled
view
id
name
language
tts_parameters
voice
view
id
name
data
id
end_action
data
id
continue_action
message
nlg
text
mask
barge_in_disabled
visual
text
mask
barge_in_disabled
audio
text
uri
mask
barge_in_disabled
view
id
name
language
tts_parameters
voice
message_settings
delay
minimum
backend_connection_settings
fetch_timeout
connect_timeout
view
id
name
data
idStreamInput
request Standard DLGaaS ExecuteRequest
asr_control_v1
audio_format
pcm | alaw | ulaw | opus | ogg_opus
utterance_detection_mode
SINGLE | MULTIPLE | DISABLED
recognition_flags
auto_punctuate
filter_profanity
include_tokenization
stall_timers
etc.
result_type
no_input_timeout_ms
recognition_timeout_ms
utterance_end_silence_ms
speech_detection_sensitivity
max_hypotheses
end_stream_no_valid_hypotheses
resources
speech_domain formatting
audio
tts_control_v1
audio_params
audio_format
volume_percentage
speaking_rate_percentage
etc.
voice
name
model
etc.
control_message
start_timers_messageStreamOutput
response Standard DLGaaS ExecuteResponse
audio
asr_result
asr_status
asr_start_of_speechStopRequest
session_id
user_id



DialogService
| Name | Request Type | Response Type | Description |
|---|---|---|---|
| Start | StartRequest | StartResponse | Starts a conversation. Returns a StartResponse object. |
| Status | StatusRequest | StatusResponse | Returns the status of a session. Returns grpc status 0 (OK) if found, 5 (NOT_FOUND) if no session was found. Returns a StatusResponse object. |
| Update | UpdateRequest | UpdateResponse | Updates the state of a session without advancing the conversation. Returns an UpdateResponse object. |
| Execute | ExecuteRequest | ExecuteResponse | Used to continuously interact with the conversation based on end user input or events. Returns an ExecuteResponse object that will contain data related to the dialog interactions and that can be used by the client to interact with the end user. |
| ExecuteStream | StreamInput stream | StreamOutput stream | Performs recognition on streamed audio using ASRaaS and provides speech synthesis using TTSaaS. |
| Stop | StopRequest | StopResponse | Ends a conversation and performs cleanup. Returns a StopResponse object. |
This service includes:
DialogService
Start
StartRequest
StartResponse
Status
StatusRequest
StatusResponse
Update
UpdateRequest
UpdateResponse
Execute
ExecuteRequest
ExecuteResponse
ExecuteStream
StreamInput
StreamOutput
Stop
StopRequest
StopResponse
StartRequest
Request object used by the Start method.
| Field | Type | Description |
|---|---|---|
| session_id | string | Optional session ID. If not provided then one will be generated. |
| selector | common.Selector | Selector providing the channel and language used for the conversation. |
| payload | common.StartRequestPayload | Payload of the Start request. |
| session_timeout_sec | uint32 | Session timeout value (in seconds), after which the session is terminated. The maximum is configured in the deployment. |
| user_id | string | Identifies a specific user within the application. See User ID. |
| client_data | map<string,string> | Map of client-supplied key-value pairs to inject into the call log. Optional. Example: "client_data": { "param1": "value1", "param2": "value2" } |
This method includes:
StartRequest
session_id
selector
channel
language
library
payload
model_ref
uri
type
data
suppress_log_user_data
session_timeout_sec
user_id
client_data
StartResponse
Response object used by the Start method.
| Field | Type | Description |
|---|---|---|
| payload | common.StartResponsePayload | Payload of the Start response. Contains session ID. |
This method includes:
StartResponse
payload
session_id
StatusRequest
Request object used by Status method. For more information about the Status method, see Step 5. Check session status.
| Field | Type | Description |
|---|---|---|
| session_id | string | ID for the session. |
This method includes:
StatusRequest
session_id
StatusResponse
Response object used by the Status method.
| Field | Type | Description |
|---|---|---|
| session_remaining_sec | uint32 | Remaining session time to live (TTL) value in seconds, after which the session is terminated. Note: The TTL may be a few seconds off based on how long the round trip of the request took. |
This method includes:
StatusResponse
session_remaining_sec
UpdateRequest
Request object used by the Update method. For more information about the Update method, see Step 6. Update session data.
| Field | Type | Description |
|---|---|---|
| session_id | string | ID for the session. |
| payload | common.UpdateRequestPayload | Payload of the Update request. |
| client_data | map<string,string> | Map of client-supplied key-value pairs to inject into the call log. Optional. Example: "client_data": { "param1": "value1", "param2": "value2" } |
| user_id | string | Identifies a specific user within the application. See User ID. |
This method includes:
UpdateRequest
session_id
payload
client_data
user_id
UpdateResponse
Response object used by the Update method. Currently empty.
This method includes:
UpdateResponse
ExecuteRequest
Request object used by the Execute method.
| Field | Type | Description |
|---|---|---|
| session_id | string | ID for the session. |
| selector | common.Selector | Selector providing the channel and language used for the conversation. |
| payload | common.ExecuteRequestPayload | Payload of the Execute request. |
| user_id | string | Identifies a specific user within the application. See User ID. |
This method includes:
ExecuteRequest
session_id
selector
channel
language
library
payload
user_input
user_text
interpretation
confidence
input_mode
utterance
data
key
value
slot_literals
key
value
slot_formatted_literals
key
value
slot_confidences
key
value
alternative_interpretations
selected_item
id
value
nluaas_interpretation
input_mode
dialog_event
type
message
event_name
requested_data
id
data
user_id
ExecuteResponse
Response object used by the Execute method. This object carries a payload, which instructs the client app to play messages to the user (as needed) and do one of the following:
- Prompt for user input
- Provide requested data
- Fill time and keep user engaged while server side is fetching data
- Transfer or end the conversation
| Field | Type | Description |
|---|---|---|
| payload | common.ExecuteResponsePayload | Payload of the Execute response. |
This method includes:
ExecuteResponse
payload
messages
nlg
text
mask
barge_in_disabled
visual
text
mask
barge_in_disabled
audio
text
uri
mask
barge_in_disabled
view
id
name
language
tts_parameters
voice
qa_action
message
nlg
text
mask
barge_in_disabled
visual
text
mask
barge_in_disabled
audio
text
uri
mask
barge_in_disabled
view
id
name
language
tts_parameters
voice
data
view
id
name
selectable
selectable_items
value
id
value
description
display_text
display_image_uri
recognition_settings
dtmf_mappings
collection_settings
speech_settings
dtmf_settings
mask
da_action
id
message
nlg
text
mask
barge_in_disabled
visual
text
mask
barge_in_disabled
audio
text
uri
mask
barge_in_disabled
view
id
name
language
tts_parameters
voice
view
id
name
message_settings
delay
minimum
data
escalation_action
message
nlg
text
mask
barge_in_disabled
visual
text
mask
barge_in_disabled
audio
text
uri
mask
barge_in_disabled
view
id
name
language
tts_parameters
voice
view
id
name
data
id
end_action
data
id
continue_action
message
nlg
text
mask
barge_in_disabled
visual
text
mask
barge_in_disabled
audio
text
uri
mask
barge_in_disabled
view
id
name
language
tts_parameters
voice
message_settings
delay
minimum
backend_connection_settings
fetch_timeout
connect_timeout
view
id
name
data
id
StreamInput
Performs recognition on streamed audio using ASRaaS and requests speech synthesis using TTSaaS.
asr_control_v1 (and control_message if applicable) must be sent as part of the first StreamInput message in order for DLGaaS to chain the audio stream with ASRaaS. Audio is then sent in the subsequent StreamInput messages.
| Field | Type | Description |
|---|---|---|
| request | ExecuteRequest | Standard DLGaaS ExecuteRequest. Used to continue the dialog interactions. |
| asr_control_v1 | AsrParamsV1 | Defines audio recognition parameters to be forwarded to the ASR service to initiate audio streaming. The contents of this message correspond to those of the recognition_init_message field used in the first message of the ASR input stream. |
| audio | bytes | Subsequent message containing audio samples in the selected encoding for recognition. |
| tts_control_v1 | TtsParamsv1 | Parameters to be forwarded to the TTS service. |
| control_message | nuance.asr.v1.ControlMessage | Optional input message to be forwarded to the ASR service. This corresponds to the optional control_message field used in the first message of the ASR input stream. ASR uses this message to start the recognition no-input timer if it was disabled by a stall_timers recognition flag in asr_control_v1. See the ASRaaS RecognitionRequest documentation for details. |
This method includes:
StreamInput
request Standard DLGaaS ExecuteRequest
asr_control_v1
audio_format
pcm | alaw | ulaw | opus | ogg_opus
utterance_detection_mode
SINGLE | MULTIPLE | DISABLED
recognition_flags
auto_punctuate
filter_profanity
include_tokenization
stall_timers
etc.
result_type
no_input_timeout_ms
recognition_timeout_ms
utterance_end_silence_ms
speech_detection_sensitivity
max_hypotheses
end_stream_no_valid_hypotheses
resources
speech_domain
formatting
control_message
audio
start_timers_message
tts_control_v1
audio_params
audio_format
volume_percentage
speaking_rate_percentage
etc.
voice
name
model
etc.
StreamOutput
Streams the requested TTS output and returns ASR results.
| Field | Type | Description |
|---|---|---|
| response | ExecuteResponse | Standard DLGaaS ExecuteResponse; used to continue the dialog interactions. |
| audio | nuance.tts.v1.SynthesisResponse | TTS output. See the TTSaaS SynthesisResponse documentation for details. |
| asr_result | nuance.asr.v1.Result | Output message containing the transcription result, including the result type, the start and end times, metadata about the transcription, and one or more transcription hypotheses. See the ASRaaS Result documentation for details. |
| asr_status | nuance.asr.v1.Status | Output message indicating the status of the transcription. See the ASRaaS Status documentation for details. |
| asr_start_of_speech | nuance.asr.v1.StartOfSpeech | Output message containing the start-of-speech message. See the ASRaaS StartOfSpeech documentation for details. |
This method includes:
StreamOutput
response Standard DLGaaS ExecuteResponse
audio
asr_result
asr_status
asr_start_of_speech
StopRequest
Request object used by Stop method.
| Field | Type | Description |
|---|---|---|
| session_id | string | ID for the session. |
| user_id | string | Identifies a specific user within the application. See User ID. |
This method includes:
StopRequest
session_id
user_id
StopResponse
Response object used by the Stop method. Currently empty; reserved for future use.
This method includes:
StopResponse
Fields reference
AsrParamsV1
Parameters to be forwarded to the ASR service. See Step 4b. Interact with the user (using audio) for details.
| Field | Type | Description |
|---|---|---|
| audio_format | nuance.asr.v1.AudioFormat | Audio codec type and sample rate. See the ASRaaS AudioFormat documentation for details. |
| utterance_detection_mode | nuance.asr.v1. EnumUtteranceDetectionMode | How end of utterance is determined. Defaults to SINGLE. See the ASRaaS EnumUtteranceDetectionMode documentation for details. |
| recognition_flags | nuance.asr.v1.RecognitionFlags | Flags to fine tune recognition. See the ASRaaS RecognitionFlags documentation for details. |
| result_type | nuance.asr.v1.EnumResultType | Whether final, partial, or immutable results are returned. See the ASRaaS EnumResultType documentation for details. |
| no_input_timeout_ms | uint32 | Maximum silence, in ms, allowed while waiting for user input after recognition timers are started. Default (0) means server default, usually no timeout. See the ASRaaS Timers documentation for details. |
| recognition_timeout_ms | uint32 | Maximum duration, in ms, of recognition turn. Default (0) means server default, usually no timeout. See the ASRaaS Timers documentation for details. |
| utterance_end_silence_ms | uint32 | Minimum silence, in ms, that determines the end of an utterance. Default (0) means server default, usually 500ms or half a second. See the ASRaaS Timers documentation for details. |
| speech_detection_sensitivity | float | A balance between detecting speech and noise (breathing, etc.), from 0 to 1. 0 means ignore all noise, 1 means interpret all noise as speech. Default is 0.5. See the ASRaaS Timers documentation for details. |
| max_hypotheses | uint32 | Maximum number of n-best hypotheses to return. Default (0) means a server default, usually 10 hypotheses. |
| end_stream_no_valid_hypotheses | bool | Determines whether the dialog application or the client application handles the dialog flow when ASRaaS does not return a valid hypothesis. When set to false (default), the dialog flow is determined by the Mix.dialog application, according to the processing defined for the NO_INPUT and NO_MATCH events. To configure the streaming request so that the stream is closed if ASRaaS does not return a valid hypothesis, set to true. See Handling unusable ASR audio for details. |
| resources | nuance.asr.v1.RecognitionResource | Repeated. Resources (DLMs, wordsets, builtins) to improve recognition. See the ASRaaS RecognitionResource documentation for details. |
| speech_domain | string | Mapping to internal weight sets for language models in the data pack. Values depend on the data pack. |
| formatting | nuance.asr.v1.Formatting | Specifies how the transcription results are presented, using keywords for formatting schemes and options supported by the data pack. See ASRaaS Formatting for details. |
BackendConnectionSettings
Settings configured for a data access node backend connection.
| Field | Type | Description |
|---|---|---|
| fetch_timeout | string | Number of milliseconds allowed for fetching the data before timing out. |
| connect_timeout | string | Connect timeout in milliseconds. |
ContinueAction
Continue action provides the client application with information useful for handling latency or delays involved with a data access node using a backend data connection. The continue action prompts the client application to respond to initiate the data access.
| Field | Type | Description |
|---|---|---|
| message | Message | Latency message to be played to the user while waiting for the backend data access. |
| view | View | View details for this action. |
| data | google.protobuf.Struct | Map of data exchanged in this node. |
| id | string | ID identifying the Continue action node in the dialog application. |
| message_settings | MessageSettings | Settings to be used along with messages returned to the present user. |
| backend_connection_settings | BackendConnectionSettings | Backend settings that will be used by DLGaaS for connecting to and fetching from the backend. |
DAAction
A Data Access action is associated with a Data access node using client-side data access. It provides the client application with data needed to perform the data access as well as a message to play to the user while waiting for the data access to complete.
| Field | Type | Description |
|---|---|---|
| id | string | ID identifying the Data Access node in the dialog application. |
| message | Message | Message to be played to the user while waiting for the data access to complete. |
| view | View | View details for this action. |
| data | google.protobuf.Struct | Map of data exchanged in this node. |
| message_settings | MessageSettings | Settings to be used along with messages played to the present user. |
DialogEvent
Message used to indicate an event that occurred during the dialog interactions.
| Field | Type | Description |
|---|---|---|
| type | DialogEvent.EventType | Type of event being triggered. |
| message | string | Optional message providing additional information about the event. |
| event_name | string | Name of custom event. Must be set to the name of the custom event defined in Mix.dialog. See Manage events for details. Applies only when DialogEvent.EventType is set to CUSTOM. |
DialogEvent.EventType
The possible event types that can occur on the client side of interactions.
| Name | Number | Description |
|---|---|---|
| SUCCESS | 0 | Everything went as expected. |
| ERROR | 1 | An unexpected problem occurred. |
| NO_INPUT | 2 | End user has not provided any input. |
| NO_MATCH | 3 | End user provided unrecognizable input. |
| HANGUP | 4 | End user has hung up. Currently used for IVR interactions. |
| CUSTOM | 5 | Custom event. You must set field event_name in DialogEvent to the name of the custom event defined in Mix.dialog. |
EndAction
End node, indicates that the dialog has ended.
| Field | Type | Description |
|---|---|---|
| data | google.protobuf.Struct | Map of data exchanged in this node. |
| id | string | ID identifying the End Action node in the dialog application. |
EscalationAction
Escalation action to be performed by the client application.
| Field | Type | Description |
|---|---|---|
| message | Message | Message to be played as part of the escalation action. |
| view | View | View details for this action. |
| data | google.protobuf.Struct | Map of data exchanged in this node. |
| id | string | ID identifying the External Action node in the dialog application. |
ExecuteRequestPayload
Payload sent with the Execute request. If both an event and a user input are provided, the event has precedence. For example, if an error event is provided, the input will be ignored.
| Field | Type | Description |
|---|---|---|
| user_input | UserInput | Input provided to the Dialog engine. |
| dialog_event | DialogEvent | Used to pass in events that can drive the flow. Optional; if an event is not passed, the operation is assumed to be successful. |
| requested_data | RequestData | Data that was previously requested by engine. |
ExecuteResponsePayload
Payload returned after the Execute method is called. Specifies the action to be performed by the client application.
| Field | Type | Description |
|---|---|---|
| messages | Message | Repeated. Message action to be performed by the client application. |
| qa_action | QAAction | Question and answer action to be performed by the client application. |
| da_action | DAAction | Data access action to be performed by the client application in relation to data access node using client-side data connection. |
| escalation_action | EscalationAction | Escalation action to be performed by the client application. |
| end_action | EndAction | End action to be performed by the client application. |
| continue_action | ContinueAction | Continue action to be performed by the client application in relation to data access node using server-side data connection. |
Message
Specifies the message to be played to the user. See Message actions for details.
| Field | Type | Description |
|---|---|---|
| nlg | Message.Nlg | Repeated. Text to be played using Text-to-speech. |
| visual | Message.Visual | Repeated. Text to be displayed to the user (for example, in a chat). |
| audio | Message.Audio | Repeated. Prompt to be played from an audio file. |
| view | View | View details for this message. |
| language | string | Message language in xx-XX format, e.g. en-US. |
| tts_parameters | TTSParameters | Voice parameters for TTS to be used when TTSaaS orchestrated separately from DLGaaS. |
Message.Audio
| Field | Type | Description |
|---|---|---|
| text | string | Text to be used as TTS backup if the audio file cannot be played. |
| uri | string | URI to the audio file, in the following format:language/prompts/library/channel/filename?version=versionFor example: en-US/prompts/default/Omni_Channel_VA/Message_ini_01.wav?version=1.0_1602096507331See here for more details on how the filename portion is generated. |
| mask | bool | When set to true, indicates that the text contains sensitive data that will be masked in logs. |
| barge_in_disabled | bool | When set to true, indicates that barge-in is disabled. |
Message.TTSParameters
| Field | Type | Description |
|---|---|---|
| voice | Voice | TTSaaS voice to be used. |
Message.TTSParameters.Voice
| Field | Type | Description |
|---|---|---|
| name | string | The voice's name, e.g. 'Evan'. Mandatory for SynthesizeRequest. |
| model | string | The voice's quality model, e.g. 'standard' or 'enhanced'. Mandatory for SynthesizeRequest. |
| gender | EnumGender | Voice gender. Default ANY for SynthesisRequest. |
| language | string | Language associated with the voice in xx-XX format, e.g. en-US. |
Message.TTSParameters.Voice.EnumGender
TTSaaS voice gender.
| Name | Number | Description |
|---|---|---|
| ANY | 0 | Any gender voice. Default for SynthesisRequest. |
| MALE | 1 | Male voice. |
| FEMALE | 2 | Female voice. |
| NEUTRAL | 3 | Neutral gender voice. |
Message.Nlg
| Field | Type | Description |
|---|---|---|
| text | string | Text to be played using Text-to-speech. |
| mask | bool | When set to true, indicates that the text contains sensitive data that will be masked in logs. |
| barge_in_disabled | bool | When set to true, indicates that barge-in is disabled. |
Message.Visual
| Field | Type | Description |
|---|---|---|
| text | string | Text to be displayed to the user (for example, in a chat). |
| mask | bool | When set to true, indicates that the text contains sensitive data that will be masked in logs. |
| barge_in_disabled | bool | When set to true, indicates that barge-in is disabled. |
MessageSettings
Settings to be used with messages returned by DAAction or ContinueAction.
| Field | Type | Description |
|---|---|---|
| delay | string | Time in ms to wait before presenting user with message. |
| minimum | string | Time in ms to display/play message to user. |
QAAction
Question and answer action to be performed by the client application.
| Field | Type | Description |
|---|---|---|
| message | Message | Message to be played as part of the question and answer action. |
| data | google.protobuf.Struct | Map of data exchanged in this node. |
| view | View | View details for this action. |
| selectable | Selectable | Interactive elements to be displayed by the client app, such as clickable buttons or links. See Interactive elements for details. |
| recognition_settings | RecognitionSettings | Configuration information to be used during recognition. |
| mask | bool | When set to true, indicates that the Question and Answer node is meant to collect an entity that will hold sensitive data to be masked in logs. |
RecognitionSettings
Configuration information to be used during recognition.
| Field | Type | Description |
|---|---|---|
| dtmf_mappings | DtmfMapping | Array of DTMF mappings configured in Mix.dialog. |
| collection_settings | CollectionSettings | Collection settings configured in Mix.dialog. |
| speech_settings | SpeechSettings | Speech settings configured in Mix.dialog. |
| dtmf_settings | DtmfSettings | DTMF settings configured in Mix.dialog. |
RecognitionSettings.CollectionSettings
Collection settings configured in Mix.dialog.
| Field | Type | Description |
|---|---|---|
| timeout | string | Time, in ms, to wait for speech once a prompt has finished playing before throwing a NO_INPUT event. |
| complete_timeout | string | Duration of silence, in ms, to determine the user has finished speaking. The timer starts when the recognizer has a well-formed hypothesis. |
| incomplete_timeout | string | Duration of silence, in ms, to determine the user has finished speaking. The timer starts when the user stops speaking. |
| max_speech_timeout | string | Maximum duration, in ms, of an utterance collected from the user. |
RecognitionSettings.DtmfMapping
DTMF mappings configured in Mix.dialog. See Set DTMF mappings for details.
| Field | Type | Description |
|---|---|---|
| id | string | Name of the entity to which the DTMF mapping applies. |
| value | string | Entity value to map to a DTMF key. |
| dtmf_key | string | DTMF key associated with this entity value. Valid values are: 0-9, *, # |
RecognitionSettings.DtmfSettings
DTMF settings configured in Mix.dialog.
| Field | Type | Description |
|---|---|---|
| inter_digit_timeout | string | Maximum time, in ms, allowed between each DTMF character entered by the user. |
| term_timeout | string | Maximum time, in ms, to wait for an additional DTMF character before terminating the input. |
| term_char | string | Character that terminates a DTMF input. |
RecognitionSettings.SpeechSettings
Speech settings configured in Mix.dialog.
| Field | Type | Description |
|---|---|---|
| sensitivity | string | Level of sensitivity to speech. 1.0 means highly sensitive to quiet input, while 0.0 means least sensitive to noise. |
| barge_in_type | string | Barge-in type; possible values: "speech" (interrupt a prompt by using any word) and "hotword" (interrupt a prompt by using a specific hotword). |
| speed_vs_accuracy | string | Desired balance between speed and accuracy. 0.0 means fastest recognition, while 1.0 means best accuracy. |
RequestData
Data that was requested by the dialog application.
| Field | Type | Description |
|---|---|---|
| id | string | ID used by the dialog application to identify which node requested the data. |
| data | google.protobuf.Struct | Map of keys to json objects of the data requested. |
ResourceReference
Reference object of the resource to use for the request (for example, URN or URL of the model)
| Field | Type | Description |
|---|---|---|
| uri | string | Reference (for example, the URL or URN for the Dialog model). |
| type | ResourceReference. EnumResourceType | Type of resource. |
ResourceReference.EnumResourceType
| Name | Number | Description |
|---|---|---|
| APPLICATION_MODEL | 0 | Dialog application model. |
Selectable
Interactive elements to be displayed by the client app, such as clickable buttons or links. See Interactive elements for details.
| Field | Type | Description |
|---|---|---|
| selectable_items | Selectable.SelectableItem | Repeated. Ordered list of interactive elements. |
Selectable.SelectableItem
| Field | Type | Description |
|---|---|---|
| value | Selectable.SelectableItem. SelectedValue | Key-value pair of entity information (name and value) for the interactive element. A selected key-value pair is passed in an ExecuteRequest when the user interacts with the element. |
| description | string | Description of the interactive element. |
| display_text | string | Label to display for this interactive element. |
| display_image_uri | string | URI of image to display for this interactive element. |
Selectable.SelectableItem.SelectedValue
| Field | Type | Description |
|---|---|---|
| id | string | Name of the entity being collected. |
| value | string | Entity value corresponding to the interactive element. |
Selector
Provides channel and language used for the conversation. See Selectors for details.
| Field | Type | Description |
|---|---|---|
| channel | string | Optional: Channel that this conversation is going to use (for example, WebVA). Note: Replace any spaces or slashes in the name of the channel with the underscore character (_). |
| language | string | Optional: Language to use for this conversation. This sets the language session variable. The format is xx-XX, for example, "en-US" |
| library | string | Optional: Library to use for this conversation. Advanced customization reserved for future use. Always use the default value for now, which is default. |
StartRequestPayload
Payload sent with the Start request.
| Field | Type | Description |
|---|---|---|
| model_ref | ResourceReference | Reference object for the Dialog model. |
| data | google.protobuf.Struct | Session variables data sent in the request as a map of key-value pairs. |
| suppress_log_user_data | bool | Set to true to disable logging for ASR, NLU, TTS, and Dialog. |
StartResponsePayload
Payload returned after the Start method is called. If a session ID is not provided in the request, a new one is generated and should be used for subsequent calls.
| Field | Type | Description |
|---|---|---|
| session_id | string | Returns session ID to use for subsequent calls. |
UpdateRequestPayload
Payload sent with the Update request.
| Field | Type | Description |
|---|---|---|
| data | google.protobuf.Struct | Map of key-value pairs of session variables to update. |
TtsParamsv1
Parameters to be forwarded to the TTS service. See Step 4b. Interact with the user (using audio) for details.
| Field | Type | Description |
|---|---|---|
| audio_params | nuance.tts.v1. AudioParameters |
Output audio parameters, such as encoding and volume. See the TTSaaS AudioParameters documentation for details. |
| voice | nuance.tts.v1.Voice | The voice to use for audio synthesis. See the TTSaaS Voice documentation for details. |
UserInput
Provides input to the Dialog engine. The client application sends either the text collected from the user, to be interpreted by Mix, or an interpretation that was performed externally.
Note: Provide only one of the following fields: user_text, interpretation, selected_item, nluaas_interpretation.
| Field | Type | Description |
|---|---|---|
| user_text | string | Text collected from end user. |
| interpretation | UserInput.Interpretation | Interpretation that was done externally (for example, Nuance Recognizer for VoiceXML). This can be used for simple interpretations that include entities with string values only. Use nluaas_interpretation for interpretations that include complex entities. |
| selected_item | Selectable.SelectableItem. SelectedValue |
Value of element selected by end user. |
| nluaas_interpretation | nuance.nlu.v1.InterpretResult | Interpretation that was done externally (for example, Nuance Recognizer for VoiceXML), provided in the NLUaaS format. See Interpreting text user input for an example. Note that DLGaaS currently only supports single intent interpretations. |
| input_mode | string | Optional: Input mode. Used for reporting. Current values are dtmf/voice. Applies to user_text and nluaas_interpretation input only. |
UserInput.Interpretation
Sends interpretation data.
| Field | Type | Description |
|---|---|---|
| confidence | float | Required: Value from 0..1 that indicates the confidence of the interpretation. |
| input_mode | string | Optional: Input mode. Current values are dtmf/voice (but input mode not limited to these). |
| utterance | string | Raw collected text. |
| data | UserInput.Interpretation. DataEntry |
Repeated. Data from the interpretation of intents and entities. For example, INTENT:BILL_PAY or or AMOUNT:100. |
| slot_literals | UserInput.Interpretation. SlotLiteralsEntry |
Repeated. Slot literals from the interpretation of the entities. The slot literal provides the exact words used by the user. For example, AMOUNT: One hundred dollars. |
| slot_formatted_literals | UserInput.Interpretation. SlotFormattedLiteralsEntry |
Repeated. Slot formatted literals from the interpretation of the entities. |
| slot_confidences | UserInput.Interpretation. SlotConfidencesEntry |
Repeated. Slot confidences from the interpretation of the entities. |
| alternative_interpretations | UserInput.Interpretation | Repeated. Alternative interpretations possible from the interaction, that is, n-best list. |
UserInput.Interpretation.DataEntry
| Field | Type | Description |
|---|---|---|
| key | string | Key of the data. |
| value | string | Value of the data. |
UserInput.Interpretation.SlotConfidencesEntry
| Field | Type | Description |
|---|---|---|
| key | string | Name of the entity. |
| value | float | Value from 0..1 that indicates the confidence of the interpretation for this entity. |
UserInput.Interpretation.SlotLiteralsEntry
| Field | Type | Description |
|---|---|---|
| key | string | Name of the entity. |
| value | string | Literal value of the entity. |
UserInput.Interpretation.SlotFormattedLiteralsEntry
| Field | Type | Description |
|---|---|---|
| key | string | Name of the entity. |
| value | string | Literal value of the entity. |
View
Specifies view details for this action.
| Field | Type | Description |
|---|---|---|
| id | string | Class or CSS defined for the view details in the node. |
| name | string | Type defined for the view details in the node. |
Scalar Value Types
Change log
2022-10-19
Updates to Session lifetime. The maximum configurable session time limit has been increased from 24 hours to 72 hours.
2022-08-17
- Updates to Sample Python app to clarify OS dependent details for setting up environment and installing dependencies.
- Updates to Dialog essentials to add some more conceptual background on the conversation metaphor underlying the API flow.
- Updates to Client app development. Moved some content from Step 4b. Interact with the user using audio to Reference topics for added readability.
2022-05-18
- Updates to Sample Python app and Client app development.
- Minor updates to gRPC setup
2022-05-11
- Updates to gRPC setup and Sample Python app to reflect updates to bundled proto files for other services.
The proto files have been updated. To use the new fields:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2022-03-30
- Updates to Session lifetime to add information on how to reset the time remaining on a Dialog sesion.
- Minor updates to gRPC setup.
The proto files have been updated. To use the new fields:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2022-03-23
A Message returned as part of an ExecuteResponse now includes the current active language for the conversation. This allows the client application to be aware when the language is changed in the dialog. The message also includes information about the TTS voice configured to use for the message. This voice information includes the name of the voice, quality model, gender, and language for which the voice applies.
The TTS voice information is useful if you need to orchestrate with TTSaaS separately from Dialog using a TTSaaS SynthesisRequest.
Being aware when the active language is changed is useful if the client application is using a third-party solution for text to speech.
For more information about handling TTSaaS orchestration in the client application, see Generating synthesized speech output.
The proto files have been updated. To use the new fields:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2022-03-16
Minor updates to sample app run script in Client app development.
2022-03-02
Updates to Disabling logging.
2022-02-16
Adding new content about Handling DTMF input in IVR applications.
2021-09-29
- Adding content about support for Data access node latency prompts. Data access nodes in Dialog allow you to define a latency message along with properties. The message is to be played to users while the data is being retrieved. The message information is sent via a
da_actionobjects for client-side fetching and via acontinue_actionobject for backend fetching. The continue action also provides details about the timeout settings for the backend server. See Data access actions and Continue actions for more detail. - Adding content about support for passing in references to compiled ASR and NLU resources using a new predefined Dialog variable. At runtime, these resources augment and improve recognition and interpretation results. For more detail, see Referencing compiled resources.
To use new fields:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2021-08-04
- The section Interact with the user using audio includes additional information on how to reference recorded audio files for the Audio Script modality.
- The UserInput.Interpretation message now contains a
slot_formatted_literalsfield. This field is used to include formatted literals from external interpretation of entities.
To use the new field:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2021-06-23
- Expanding content on the concept of Sessions in DLGaaS.
- Adding new content to document how to provide inline Wordsets to DLGaaS. Wordsets are used by ASRaaS and NLUaaS to improve speech recognition and natural language understanding of user input for dynamic list entities.
2021-03-31
- The maximum value for the session idle timeout, set with the
session_timeout_secfield of the StartRequest message, has been increased to 90000 seconds (25 hours). - The DLGaaS gRPC API now includes a new method, Status, to check how much time is left on a previously started session.
To use this new method:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2021-03-17
- The DLGaaS gRPC API now includes a new method, Update, to update session data once a session has started. See Step 6. Update session data for details.
To use this new method:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2021-03-03
- The StreamInput message now contains a
control_messagesfield. This message is used by ASR to start the recognition no-input timer if it was disabled by astall_timersrecognition flag inasr_control_v1. - The ASRParamsV1 message now contains
speech_domainandformattingfields, which let customers set weights for language models and specify text formatting of results from recognition.
To use the new fields:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2021-02-17
- The AsrParamsV1 message now contains the
resourcesfield, which lets customers specify ASR resources (DLMs, wordsets, builtins, speaker profiles) to improve recognition.
To use the new resources field:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2021-02-03
- When DLGaaS calls TTSaaS through the StreamInput request, it now specifies the
ssmlinput type, which lets customers use SSML tags to tune the synthesized TTS output. For more information about SSML tags, see the TTSaaS documentation. - The UserInput field of the ExecuteRequest payload now includes the
input_modeas a top-level field, to allow DLGaaS clients to send the input mode (dtmf/voice) with the recognition results for reporting purposes. In previous releases, theinput_modecould only be sent as part of theinterpretationfield.
To use the new input_mode field:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2021-01-13
- The RecognitionSettings field of QA action now includes new fields to show settings configured in Mix.dialog:
- The CLIENT_ID example was updated to show latest Mix syntax.
To use these features:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2020-12-14
- The userData predefined variable section shows how to send the userData predefined variable to the dialog application in the StartRequest payload.
- The nlg, visual, and audio messages now include two new fields,
maskandbarge_in_disabled. - The QA action now includes a new field,
mask.
To use these features:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2020-10-28
- The Simple variable types section describes the new variable types that can be set in Mix.dialog and shows how to send them to the dialog application in a data access node.
- The QA action now includes a new field,
RecognitionSettings, that includes DTMF mappings configured in Mix.dialog.
To use this feature:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2020-10-08
Added more information about URIs for audio files.
2020-09-16
- The obsolete API versions (v1beta1 and v1beta2) were removed from the documentation.
- The UserInput message now includes a new field,
nluaas_interpretation, to provide interpretations in the NLUaaS format. See Interpreting text user input for an example. Note that DLGaaS currently only supports single intent interpretations.
To use this feature:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2020-09-03
- The AsrParamsV1 message now contains the
end_stream_no_valid_hypothesesfield to close the stream when no valid hypotheses is returned by ASRaaS. See Handling unusable ASR audio for details. - The StartRequest now includes a new field,
client_data, to inject data in call logs. - The following ASR parameters can now be set in the AsrParamsV1 message:
no_input_timeout_msrecognition_timeout_msutterance_end_silence_msspeech_detection_sensitivitymax_hypotheses
To use these features:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2020-08-26
- Noted in Selectors to replace any spaces or slashes in the name of the channel with the underscore character (_).
2020-07-22
- Added more information about Transfer actions.
2020-07-09
- Versions v1beta1 and v1beta2 of the DLGaaS API are now obsolete.
2020-06-24
- Custom events are now supported. The DialogEvent.EventType field supports a new type,
CUSTOM, and the custom event name can be set in fieldevent_nameof DialogEvent.
To use this feature:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2020-05-28
- The StartRequest, ExecuteRequest, and StopRequest now include a new field,
user_id, which identifies a specific user. See UserID for details. - The ASR proto files were renamed from nuance_asr*.proto to recognizer.proto, resource.proto, and result.proto.
To use these features:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2020-05-14
- Added information about data sent in a question and answer action.
2020-05-13
- The StreamOutput method contains two new fields:
asr_status, to provide the status of the transcription.asr_start_of_speech, to provide start-of-speech message.
To use these features:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2020-04-30
- The Interpretation message contains a new field,
slot_confidences, to provide the confidence values for entities. - The escalation action, end action, and continue action now include an ID that identifies the node in the dialog application.
- The TtsParamsv1 contains a new field,
voice, that lets you specify the voice to use for audio synthesis.
To use these features:
- Download the latest version of the proto files.
- Generate the client stubs from the proto files as described in gRPC setup.
2020-04-15
- Added Status messages and codes
- Added an example for using interactive elements
- Provided additional information about nodes and actions
2020-03-31
First release of this new version.