
TTS as a Service gRPC API
Nuance TTS provides speech synthesis
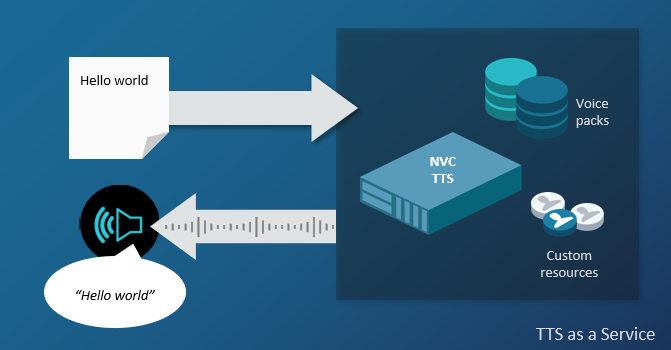
Nuance TTS (Text to Speech) as a Service is powered by the Nuance Vocalizer for Cloud (NVC) engine, which synthesizes speech from plain text, SSML, or Nuance control codes. NVC works with Nuance Vocalizer for Enterprise (NVE) and Nuance voice packs to generate speech.
TTS as a Service lets you request speech synthesis from NVC engines running on Nuance-hosted machines. It works with voices in many languages and locales, with choices of gender and age.
The gRPC synthesizer protocol provided by NVC can request synthesis services in any of the programming languages supported by gRPC. An HTTP API for synthesis is also available.
An additional gRPC storage protocol can upload synthesis resources to cloud storage.
gRPC is an open source RPC (remote procedure call) software used to create services. It uses HTTP/2 for transport, and protocol buffers to define the structure of the application. NVC supports Protocol Buffers version 3, also known as proto3.
Version: v1
This release supports version v1 of the synthesizer API and v1beta1 of the storage API.
Prerequisites from Mix
Before developing your TTS gRPC application, you need a Nuance Mix project. This project provides credentials to run your application against the Nuance-hosted NVC engine.
Create a Mix project and model: see Mix.nlu workflow to:
Create a Mix project.
Optionally build a model in the project. If you are using other Nuance "as a service" products (such as ASRaaS or NLUaaS), you may use the same Mix project for NVC. A model is not needed for your NVC application.
Create and deploy an application configuration for the project.
Generate a client ID and "secret" in your Mix project: see Authorize your client application. Later you will use these credentials to request an access token to run your application.
Learn the URL to call the TTS service: see Accessing a runtime service.
The URLs for NVC in the hosted Mix environment are:
- Runtime:
tts.api.nuance.co.uk:443 - Authorization:
https://auth.crt.nuance.co.uk/oauth2/token
gRPC setup
Install gRPC for programming language
$ python -m pip install --upgrade pip
$ python -m pip install grpcio
$ python -m pip install grpcio-tools
Download and unzip proto files
$ unzip nuance_tts_and_storage_protos.zip
Archive: nuance_tts_and_storage_protos.zip
inflating: nuance/rpc/error_details.proto
inflating: nuance/rpc/status.proto
inflating: nuance/rpc/status_code.proto
inflating: nuance/tts/storage/v1beta1/storage.proto
inflating: nuance/tts/v1/synthesizer.proto
Generate client stubs
# Generate Python stubs from TTS proto files
python -m grpc_tools.protoc --proto_path=./ --python_out=./ --grpc_python_out=./ nuance/tts/v1/synthesizer.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=./ --grpc_python_out=./ nuance/tts/storage/v1beta1/storage.proto
# Generate Python stubs from RPC proto files
python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/error_details.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/status_code.proto
python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/status.proto
Final structure of protos and stubs for TTS and storage
├── Your client apps here
└── nuance
├── rpc
│ ├── error_details_pb2.py
│ ├── error_details.proto
│ ├── status_code_pb2.py
│ ├── status_code.proto
│ ├── status_pb2.py
│ └── status.proto
└── tts
├── storage
│ └── v1beta1
│ ├── storage_pb2.py
│ ├── storage_pb2_grpc.py
│ └── storage.proto
└── v1
├── synthesizer_pb2.py
├── synthesizer_pb2_grpc.py
└── synthesizer.proto
The basic steps in using the NVC gRPC protocol are:
Install gRPC for the programming language of your choice, including C++, Java, Python, Go, Ruby, C#, Node.js, and others. See gRPC Documentation for a complete list and instructions on using gRPC with each one.
Download the NVC gRPC proto files, which contain a generic version of the functions or classes that perform speech synthesis and upload operations:
Synthesizer and storage gRPC protos: nuance_tts_and_storage_protos.zip
Unzip the file in a location that your applications can access, for example in the directory that contains or will contain your client apps.
If your programming language requires client stub files, generate the stubs from the proto files using gRPC protoc, following the Python example as guidance. The resulting files contain the information in the proto files in your programming language.
Once you have the proto files and optionally the client stubs, you are ready to start writing client applications with the help of the API and several sample applications. See:
| Topic | Description |
|---|---|
| Synthesizer API | The gRPC protocol for synthesis. |
| Client app development | A walk-through of the major components of a synthesis client using a simple client. |
| Sample synthesis client | A full-fledged synthesis client, written in Python. |
| Storage API | The gRPC protocol for uploading resources to cloud storage. |
| Sample storage client | A client application for uploading synthesis resources to cloud storage, written in Python. |
Client app development
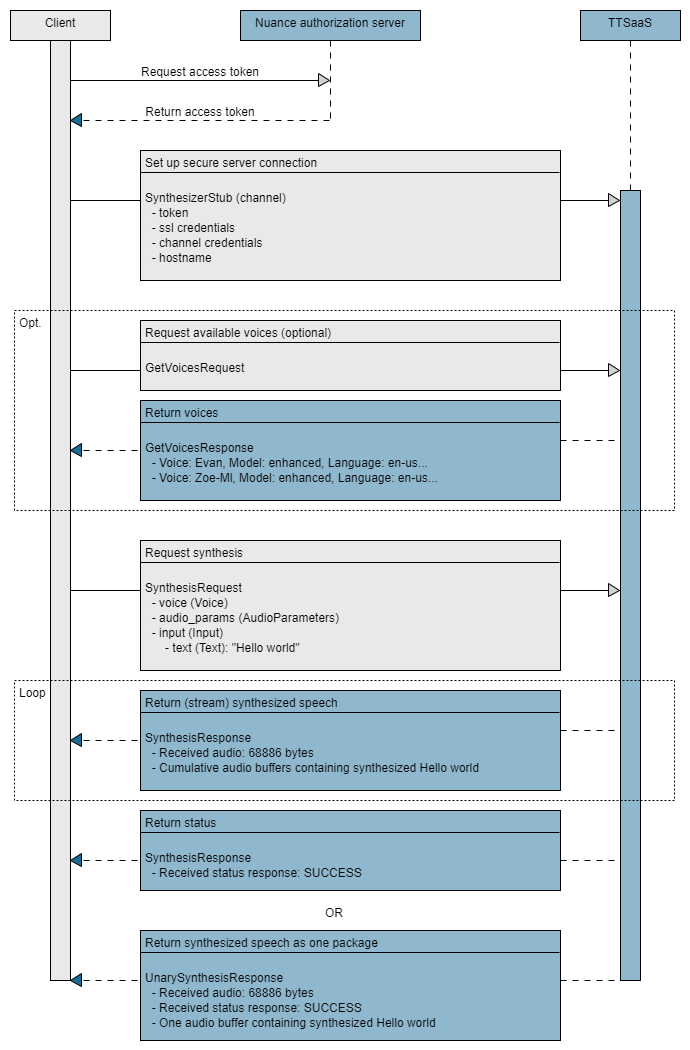
The synthesizer gRPC protocol for NVC lets you create client applications for synthesizing text and obtaining information about available voices.
Sequence flow
The essential tasks are illustrated in the following high-level sequence flow of an application at run time.
Development steps
Try it out: Copy client files into place (some proto files are omitted for clarity)
├── simple-mix-client.py
├── run-simple-mix-client.sh
└── nuance
├── rpc (RPC message files)
└── tts
├── storage (Storage files)
└── v1
├── synthesizer_pb2_grpc.py
├── synthesizer_pb2.py
└── synthesizer.proto
run-simple-mix-client.sh: Shell script to authorize and run simple client
#!/bin/bash
CLIENT_ID=<Mix client ID, colons replaced with %3A>
SECRET=<Mix client secret>
export MY_TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" \
https://auth.crt.nuance.co.uk/oauth2/token \
-d "grant_type=client_credentials" -d "scope=tts" \
| python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`"
./simple-mix-client.py --server_url tts.api.nuance.co.uk:443 \
--token $MY_TOKEN \
--name "Zoe-Ml" \
--model "enhanced" \
--text "The wind was a torrent of darkness, among the gusty trees." \
--output_wav_file "highwayman.wav"
simple-mix-client.py: Simple client: adjust the first line for your environment
#!/usr/bin/env python3
# Import functions
import sys
import grpc
import argparse
from nuance.tts.v1.synthesizer_pb2 import *
from nuance.tts.v1.synthesizer_pb2_grpc import *
from google.protobuf import text_format
# Generate a .wav file header
def generate_wav_header(sample_rate, bits_per_sample, channels, audio_len, audio_format):
# (4byte) Marks file as RIFF
o = bytes("RIFF", 'ascii')
# (4byte) File size in bytes excluding this and RIFF marker
o += (audio_len + 36).to_bytes(4, 'little')
# (4byte) File type
o += bytes("WAVE", 'ascii')
# (4byte) Format Chunk Marker
o += bytes("fmt ", 'ascii')
# (4byte) Length of above format data
o += (16).to_bytes(4, 'little')
# (2byte) Format type (1 - PCM)
o += (audio_format).to_bytes(2, 'little')
# (2byte) Will always be 1 for TTS
o += (channels).to_bytes(2, 'little')
# (4byte)
o += (sample_rate).to_bytes(4, 'little')
o += (sample_rate * channels * bits_per_sample // 8).to_bytes(4, 'little') # (4byte)
o += (channels * bits_per_sample // 8).to_bytes(2,'little') # (2byte)
# (2byte)
o += (bits_per_sample).to_bytes(2, 'little')
# (4byte) Data Chunk Marker
o += bytes("data", 'ascii')
# (4byte) Data size in bytes
o += (audio_len).to_bytes(4, 'little')
return o
# Define synthesis request
def create_synthesis_request(name, model, text, ssml, sample_rate, send_log_events, client_data):
request = SynthesisRequest()
request.voice.name = name
request.voice.model = model
pcm = PCM(sample_rate_hz=sample_rate)
request.audio_params.audio_format.pcm.CopyFrom(pcm)
if text:
request.input.text.text = text
elif ssml:
request.input.ssml.text = ssml
else:
raise RuntimeError("No input text or SSML defined.")
request.event_params.send_log_events = send_log_events
return request
def main():
parser = argparse.ArgumentParser(
prog="simple-mix-client.py",
usage="%(prog)s [-options]",
add_help=False,
formatter_class=lambda prog: argparse.HelpFormatter(
prog, max_help_position=45, width=100)
)
# Set arguments
options = parser.add_argument_group("options")
options.add_argument("-h", "--help", action="help",
help="Show this help message and exit")
options.add_argument("--server_url", nargs="?",
help="Server hostname (default=localhost)", default="localhost:8080")
options.add_argument("--token", nargs="?",
help="Access token", required=True)
options.add_argument("--name", nargs="?", help="Voice name", required=True)
options.add_argument("--model", nargs="?",
help="Voice model", required=True)
options.add_argument("--sample_rate", nargs="?",
help="Audio sample rate (default=22050)", type=int, default=22050)
options.add_argument("--text", nargs="?", help="Input text")
options.add_argument("--ssml", nargs="?", help="Input SSML")
options.add_argument("--send_log_events",
action="store_true", help="Subscribe to Log Events")
options.add_argument("--output_wav_file", nargs="?",
help="Destination file path for synthesized audio")
options.add_argument("--client_data", nargs="?",
help="Client information in key value pairs")
args = parser.parse_args()
# Create channel and stub
call_credentials = grpc.access_token_call_credentials(args.token)
channel_credentials = grpc.composite_channel_credentials(
grpc.ssl_channel_credentials(), call_credentials)
# Send request and process results
with grpc.secure_channel(args.server_url, credentials=channel_credentials) as channel:
stub = SynthesizerStub(channel)
request = create_synthesis_request(name=args.name, model=args.model, text=args.text,
ssml=args.ssml, sample_rate=args.sample_rate, send_log_events=args.send_log_events,
client_data=args.client_data)
stream_in = stub.Synthesize(request)
audio_file = None
wav_header = None
total_audio_len = 0
try:
if args.output_wav_file:
audio_file = open(args.output_wav_file, "wb")
# Write an empty wav header for now, until we know the final audio length
wav_header = generate_wav_header(sample_rate=args.sample_rate, bits_per_sample=16, channels=1, audio_len=0, audio_format=1)
audio_file.write(wav_header)
for response in stream_in:
if response.HasField("audio"):
print("Received audio: %d bytes" % len(response.audio))
total_audio_len = total_audio_len + len(response.audio)
if(audio_file):
audio_file.write(response.audio)
elif response.HasField("events"):
print("Received events")
print(text_format.MessageToString(response.events))
else:
if response.status.code == 200:
print("Received status response: SUCCESS")
else:
print("Received status response: FAILED")
print("Code: {}, Message: {}".format(response.status.code, response.status.message))
print('Error: {}'.format(response.status.details))
except Exception as e:
print(e)
if audio_file:
wav_header = generate_wav_header(sample_rate=args.sample_rate, bits_per_sample=16, channels=1, audio_len=total_audio_len, audio_format=1)
audio_file.seek(0, 0)
audio_file.write(wav_header)
audio_file.close()
print("Saved audio to {}".format(args.output_wav_file))
if __name__ == '__main__':
main()
This section describes how to implement basic speech synthesis in the context of a simple Python client application, shown at the right.
This client synthesizes plain text or SSML input, streaming the audio back to the client and optionally creating an audio file containing the synthesized speech.
Try it out
You can try out this simple client application to synthesize text and save it in an audio file. To run it, you need:
- Python 3.6 or later.
- The generated Python stub files from gRPC setup.
- Your client ID and secret from Prerequisites from Mix.
- run-simple-mix-client.sh: Copy the shell script at the right into the directory above your proto files and stubs.
Give it execute permissionchmod +x run-simple-mix-client.sh
Edit the shell script to add your client ID and secret (see Authorize next). - simple-mix-client.py: Copy the Python file at the right into the same directory.
Run the client using the shell script. All the arguments are in the shell script, including the text to synthesize and the output file.
$ ./run-simple-mix-client.sh
Received audio: 24926 bytes
Received audio: 11942 bytes
Received audio: 10580 bytes
Received audio: 9198 bytes
Received audio: 6316 bytes
Received audio: 8908 bytes
Received audio: 27008 bytes
Received audio: 59466 bytes
Received status response: SUCCESS
Saved audio to highwayman.wav
The synthesized speech is in the audio file, highwayman.wav, which you can play in an audio player.
Optionally synthesize your own text: edit the shell script to change the text and output_wav_file arguments, then rerun the client.
Read on to learn more about how this simple client is constructed.
Authorize
Nuance Mix uses the OAuth 2.0 protocol for authorization. The client application must provide an access token to be able to access the NVC runtime service. The token expires after a short period of time so must be regenerated frequently.
Your client application uses the client ID and secret from the Mix Dashboard (see Prerequisites from Mix), along with the OAuth scope for NVC, to generate an access token from the Nuance authorization server.
The client ID starts with appID: followed by a unique identifier. If you are using the curl command, replace the colon with %3A so the value can be parsed correctly:
appID:NMDPTRIAL_your_name_company_com_2020...
-->
appID%3ANMDPTRIAL_your_name_company_com_2020...
The OAuth scope for the NVC service is tts.
The token may be generated in several ways, either as part of the client application or as a script file. This Python example uses a Linux script to generate a token and store it in an environment variable. The token is then passed to the application, where it is used to create a secure connection to the TTS service.
Import functions
The first step is to import all functions from the NVC client stubs, synthesizer*.py, generated from the proto files in gRPC setup, along with other utilities. The client stubs (and the proto files) are in the following path under the location of the simple client:
nuance/tts/v1/synthesizer_pb2.py, synthesizer_pb2_grpc.py
Do not edit these synthesizer*.* files.
Set arguments
The client includes arguments that that it can accept, allowing users to customize its operation. For example:
--server_url: The Mix endpoint and port number for the NVC service.--token: An access token.--nameand--model: The name and model of a voice to perform the synthesis. To learn which voices are available, see Sample synthesis client.--textorssml: The material to be synthesized, in this case either plain text or SSML.--output_wav_file: Optionally, a filename for saving the synthesized audio as a wave file.
To see the arguments, run the app with the --help option:
$ ./simple-mix-client.py --help
usage: simple-mix-client.py [-options]
options:
-h, --help Show this help message and exit
--server_url [SERVER_URL] Server hostname (default=localhost)
--token [TOKEN] Access token
--name [NAME] Voice name
--model [MODEL] Voice model
--sample_rate [SAMPLE_RATE] Audio sample rate (default=22050)
--text [TEXT] Input text
--ssml [SSML] Input SSML
--send_log_events Subscribe to Log Events
--output_wav_file [OUTPUT_WAV_FILE] Destination file path for synthesized audio
--client_data [CLIENT_DATA] Client information in key value pairs
Define synthesis request
The client creates a synthesis request using SynthesisRequest, including the arguments received from the end user. In this example, the request looks for a voice name and model plus the input to synthesize, either plain text or SSML.
The input is provided in the script file that runs the client, for example:
Plain text input and an audio file to hold the results:
--text "The wind was a torrent of darkness, among the gusty trees." \ --output_wav_file "highwayman.wav"
SSML input, with optional SSML elements, and an audio file:
--ssml '<speak>This is the normal volume of my voice. \ <prosody volume="10">I can speak rather quietly,</prosody> \ <prosody volume="90">But also very loudly.</prosody></speak>' \ --output_wav_file "ssml-loud.wav"
Create channel and stub
To call NVC, the client creates a secure gRPC channel and authorizes itself by providing the URL of the hosted service and an access token.
In many situations, users can pass the service URL and token to the client as arguments. In this Python app, the URL is in the --server_url argument and the token is in --token.
A client stub function or class is defined using this channel information.
In some languages, this stub is defined in the generated client files: in Python it is named SynthesizerStub and in Go it is SynthesizerClient. In other languages, such as Java, you must create your own stub.
Send request and process results
Finally, the client calls the stub to send the synthesis request, then processes the response (a stream of responses) using the fields in SynthesisResponse.
The response returns the synthesized audio to the client, streaming it and optionally saving it in an audio file. In this client, the audio is saved to a file named in the --output_wav_file argument.
More features
Features not shown in this simple application are described in the sample synthesis client and other sections:
Get voices: To learn which voices are available, see Run client for voices.
Control codes: To provide input in the form of a tokenized sequence of text and Nuance control codes, see Input to synthesize and Control codes.
More SSML: For more information about SSML input and tags, see SSML tags.
Upload resources. See Reference topics - Synthesis resources and Sample storage client.
User dictionary: To provide a user dictionary or other resources, see Run client with resources.
Unary: If you prefer a non-streamed response, see Run client for unary response.
Multi requests: If you have multiple requests, direct them all to the same channel and stub. See Multiple requests.
Sample synthesis client
Download and extract the sample synthesis client
$ unzip sample-synthesis-client.zip
Archive: sample-synthesis-client.zip
inflating: mix-client.py
inflating: flow.py
inflating: run-mix-client.sh
$ chmod +x mix-client.py
$ chmod +x run-mix-client.sh
Location of application files, above the directory holding the Python stubs
├── flow.py
├── mix-client.py
├── run-mix-client.sh
└── nuance
├── rpc (RPC message files)
└── tts
├── storage (Storage files)
└── v1
├── synthesizer_pb2_grpc.py
├── synthesizer_pb2.py
└── synthesizer.proto
This section contains a fully-functional Python client that you may download and use to synthesize speech using the Synthesizer API. To run this client, you need:
- Python 3.6 or later.
- The generated Python stub files from gRPC setup.
- Your client ID and secret from Prerequisites from Mix.
- The OAuth scope for the NVC service:
tts. - A zip file containing the client files: sample-synthesis-client.zip. Download this zip file and extract its files into the same directory as the nuance directory, which contains your proto files and Python stubs.
- Give mix-client.py and run-mix-client.sh execute permission with
chmod +x
You can use the application to check for available voices and/or request synthesis. Here are a few scenarios you can try.
Run client for help
For a quick check that the client is working, and to see the arguments it accepts, run it using the help (-h or --help) option.
$ ./mix-client.py -h
The token option is required. Other defaults mean you do not need to specify an input file or a server URL as you run the client.
| Option | Description |
|---|---|
| -h, --help | Show help message. |
| -f, --file file(s) | List of flow files to execute sequentially. Default is flow.py. For multiple flow files, enter: --files flow.py flow2.py |
| -p, --parallel | Run each flow in a separate thread. |
| -i, --iterations num | Number of times to run the list of files. Default is 1. |
| -s, --serverUrl url | Mix TTS server URL, default is tts.api.nuance.co.uk |
| --token token | Mandatory. Access token. See step 1 in Run client for voices next. |
| --saveAudio | Save whole audio to disk. |
| --saveAudioChunks | Save each individual audio chunk to disk. |
| --saveAudioAsWav | Save each audio file in WAV format. |
| --sendUnary | Receive one response (UnarySynthesis) instead of a stream of responses (Synthesize). |
| ‑‑maxReceiveSizeMB mb | Maximum length of gRPC server response in megabytes. Default is 50 MB. |
Run client for voices
Results from get-voices request
$ ./run-mix-client.sh
2020-09-09 13:46:27,629 (140276734273344) INFO Iteration #1
2020-09-09 13:46:27,638 (140276734273344) DEBUG Creating secure gRPC channel
2020-09-09 13:46:27,640 (140276734273344) INFO Running file [flow.py]
2020-09-09 13:46:27,640 (140276734273344) DEBUG [voice {
language: "en-us"
}
]
2020-09-09 13:46:27,640 (140276734273344) INFO Sending GetVoices request
2020-09-09 13:46:27,976 (140276734273344) INFO voices {
name: "Ava-Mls"
model: "enhanced"
language: "en-us"
gender: FEMALE
sample_rate_hz: 22050
language_tlw: "enu"
version: "2.0.1"
}
...
voices {
name: "Evan"
model: "enhanced"
language: "en-us"
gender: MALE
sample_rate_hz: 22050
language_tlw: "enu"
version: "1.1.1"
}
voices {
name: "Nathan"
model: "enhanced"
language: "en-us"
gender: MALE
sample_rate_hz: 22050
language_tlw: "enu"
version: "3.0.1"
}
...
voices {
name: "Zoe-Ml"
model: "enhanced"
language: "en-us"
gender: FEMALE
sample_rate_hz: 22050
language_tlw: "enu"
version: "1.0.2"
}
2020-09-09 13:46:27,977 (140276734273344) INFO Done running file [flow.py]
2020-09-09 13:46:27,977 (140276734273344) INFO Iteration #1 complete
2020-09-09 13:46:27,978 (140276734273344) INFO Done
When you ask NVC to synthesize text, you must specify a named voice. To learn which voices are available, send a GetVoicesRequest, entering your requirements in the flow.py input file.
- Edit the run script, run-mix-client.sh, to add your CLIENT_ID and SECRET and generate an access token. These are your Mix credentials as described in Authorize. The OAuth scope,
tts, is included in the script, along with scopes for other Mix services.#!/bin/bash CLIENT_ID=<Mix client ID, replace colons with %3A> SECRET=<Mix client secret> export MY_TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" \ "https://auth.crt.nuance.co.uk/oauth2/token" \ -d "grant_type=client_credentials" -d "scope=asr nlu tts" \ | python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`" ./mix-client.py --token $MY_TOKEN --saveAudio --saveAudioAsWav
- Edit the input file, flow.py, to request all American English voices, and turn off synthesis.
from nuance.tts.v1.synthesizer_pb2 import * list_of_requests = [] # GetVoices request request = GetVoicesRequest() #request.voice.name = "Evan" request.voice.language = "en-us" # Request all en-us voices # Add request to list list_of_requests.append(request) # Enable voice request # Synthesis request ... #Add request to list #list_of_requests.append(request) # Disable synthesis with #
- Run the client using the script file.
$ ./run-mix-client.sh
See the results at the right.
Get more voices
You can experiment with this request: for example, to see all available voices, remove or comment out all the request.voice lines, leaving only the main GetVoicesRequest.
# GetVoices request request = GetVoicesRequest() # Keep only this line #request.voice.name = "Evan" #request.voice.language = "en-us"
The results include all voices available from the Nuance-hosted NVC service.
Run client for synthesis
Results from synthesis request (some events are omitted)
$ ./run-mix-client.sh
2020-09-09 13:58:52,142 (140022203164480) INFO Iteration #1
2020-09-09 13:58:52,151 (140022203164480) DEBUG Creating secure gRPC channel
2020-09-09 13:58:52,153 (140022203164480) INFO Running file [flow.py]
2020-09-09 13:58:52,153 (140022203164480) DEBUG [voice {
name: "Evan"
}
, voice {
name: "Evan"
model: "enhanced"
}
audio_params {
audio_format {
pcm {
sample_rate_hz: 22050
}
}
volume_percentage: 80
speaking_rate_factor: 1.0
audio_chunk_duration_ms: 2000
}
input {
text {
text: "This is a test. A very simple test."
}
}
event_params {
send_log_events: true
}
user_id: "MyApplicationUser"
]
2020-09-09 13:58:52,154 (140022203164480) INFO Sending GetVoices request
2020-09-09 13:58:52,303 (140022203164480) INFO voices {
name: "Evan"
model: "enhanced"
language: "en-us"
gender: MALE
sample_rate_hz: 22050
language_tlw: "enu"
version: "1.1.1"
}
2020-09-09 13:58:52,303 (140022203164480) INFO Sending Synthesis request
. . .
2020-09-09 13:58:52,663 (140022203164480) INFO Received status response: SUCCESS
2020-09-09 13:58:52,664 (140022203164480) INFO Wrote audio to flow.py_i1_s1.wav
2020-09-09 13:58:52,664 (140022203164480) INFO Done running file [flow.py]
2020-09-09 13:58:52,665 (140022203164480) INFO Iteration #1 complete
2020-09-09 13:58:52,665 (140022203164480) INFO Done
Once you know the voice you want to use, you can ask NVC to synthesize a simple test string and save the resulting audio in a wave file using a SynthesisRequest. Again enter your requirements in flow.py.
- Look at run-mix-client.sh and notice the –saveAudio and –saveAudioAsWav arguments. There is no need to include the ‑‑file argument since flow.py is the default input filename.
. . . ./mix-client.py --token $MY_TOKEN --saveAudio --saveAudioAsWav
Edit flow.py to verify that your voice is available, then request synthesis using that voice.
from nuance.tts.v1.synthesizer_pb2 import * list_of_requests = [] # GetVoices request request = GetVoicesRequest() request.voice.name = "Evan" # Request a specific voice # Add request to list list_of_requests.append(request) # Synthesis request request = SynthesisRequest() request.voice.name = "Evan" # Request synthesis using that voice request.voice.model = "enhanced" pcm = PCM(sample_rate_hz=22050) request.audio_params.audio_format.pcm.CopyFrom(pcm) request.audio_params.volume_percentage = 80 request.audio_params.speaking_rate_factor = 1.0 request.audio_params.audio_chunk_duration_ms = 2000 request.input.text.text = "This is a test. A very simple test." request.event_params.send_log_events = True request.user_id = "MyApplicationUser" #Add request to list list_of_requests.append(request) # Enable synthesis request
Run the client using the script file.
$ ./run-mix-client.sh
See the results at the right and notice the audio file created:
- flow.py_i1_s1.wav: Evan saying: "This is a test. A very simple test."
Multiple requests
Results from multiple synthesis requests
$ ./run-mix-client.sh
2020-09-27 14:26:27,209 (140665436571456) INFO Iteration #1
2020-09-27 14:26:27,219 (140665436571456) DEBUG Creating secure gRPC channel
2020-09-27 14:26:27,221 (140665436571456) INFO Running file [flow.py]
2020-09-27 14:26:27,221 (140665436571456) DEBUG [voice {
name: "Evan"
model: "enhanced"
}
audio_params {
audio_format {
pcm {
sample_rate_hz: 22050
}
}
}
input {
text {
text: "This is a test. A very simple test."
}
}
, 2, voice {
name: "Evan"
model: "enhanced"
}
audio_params {
audio_format {
pcm {
sample_rate_hz: 22050
}
}
}
input {
text {
text: "Your coffee will be ready in 5 minutes."
}
}
, 2, voice {
name: "Zoe-Ml"
model: "enhanced"
}
audio_params {
audio_format {
pcm {
sample_rate_hz: 22050
}
}
}
input {
text {
text: "The wind was a torrent of darkness, among the gusty trees."
}
}
]
2020-09-27 14:26:27,221 (140665436571456) INFO Sending Synthesis request
2020-09-27 14:26:27,673 (140665436571456) INFO Wrote audio to flow.py_i1_s1.wav
2020-09-27 14:26:27,673 (140665436571456) INFO Waiting for 2 seconds
2020-09-27 14:26:29,675 (140665436571456) INFO Sending Synthesis request
2020-09-27 14:26:29,883 (140665436571456) INFO Wrote audio to flow.py_i1_s2.wav
2020-09-27 14:26:29,883 (140665436571456) INFO Waiting for 2 seconds
2020-09-27 14:26:31,885 (140665436571456) INFO Sending Synthesis request
2020-09-27 14:26:32,102 (140665436571456) INFO Wrote audio to flow.py_i1_s3.wav
2020-09-27 14:26:32,102 (140665436571456) INFO Done running file [flow.py]
2020-09-27 14:26:32,102 (140665436571456) INFO Iteration #1 complete
2020-09-27 14:26:32,102 (140665436571456) INFO Done
You can send multiple requests for synthesis (and/or get voices) in the same session. For efficient communication with the NVC server, all requests use the same channel and stub. This scenario sends three synthesis requests.
Edit flow.py to add two more synthesis requests. (You may keep the get-voices request or remove it.) Optionally pause for a couple of seconds after each synthesis request.
from nuance.tts.v1.synthesizer_pb2 import * list_of_requests = [] # Synthesis request request = SynthesisRequest() # First request request.voice.name = "Evan" request.voice.model = "enhanced" pcm = PCM(sample_rate_hz=22050) request.audio_params.audio_format.pcm.CopyFrom(pcm) request.input.text.text = "This is a test. A very simple test." list_of_requests.append(request) list_of_requests.append(2) # Optionally pause after request # Synthesis request request = SynthesisRequest() # Second request request.voice.name = "Evan" request.voice.model = "enhanced" pcm = PCM(sample_rate_hz=22050) request.audio_params.audio_format.pcm.CopyFrom(pcm) request.input.text.text = "Your coffee will be ready in 5 minutes." list_of_requests.append(request) list_of_requests.append(2) # Optionally pause after request # Synthesis request request = SynthesisRequest() # Third request request.voice.name = "Zoe-Ml" request.voice.model = "enhanced" pcm = PCM(sample_rate_hz=22050) request.audio_params.audio_format.pcm.CopyFrom(pcm) request.input.text.text = "The wind was a torrent of darkness, among the gusty trees." list_of_requests.append(request)
Run the client using the script file.
$ ./run-mix-client.sh
See the results at the right and notice the three audio files created:
- flow.py_i1_s1.wav: Evan saying: "This is a test..."
- flow.py_i1_s2.wav: Evan saying: "Your coffee will be ready..."
- flow.py_i1_s3.wav: Zoe saying: "The wind was a torrent of darkness..."
Run client with resources
Results from synthesis request
$ ./run-mix-client.sh
2021-05-23 15:56:19,442 (140367419443008) INFO Iteration #1
2021-05-23 15:56:19,454 (140367419443008) DEBUG Creating secure gRPC channel
2021-05-23 15:56:19,458 (140367419443008) INFO Running file [flow.py]
2021-05-23 15:56:19,458 (140367419443008) DEBUG [voice {...}
audio_params {...}
input {
text {
text: "This is a test. A very simple test."
}
resources {
uri: "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_dict/en-us/mix.tts"
}
}
]
2021-05-23 15:56:19,458 (140367419443008) INFO Sending Synthesis request
2021-05-23 15:56:20,015 (140367419443008) INFO Wrote audio to flow.py_i1_s1.wav
2021-05-23 15:56:20,015 (140367419443008) INFO Done running file [flow.py]
2021-05-23 15:56:20,016 (140367419443008) INFO Done
If you have uploaded synthesis resources using the Storage API (see the Sample storage client), you can reference them in a synthesis request. Enter the resources in flow.py.
- Use run-mix-client.sh with –saveAudio and –saveAudioAsWav arguments.
. . . ./mix-client.py --token $MY_TOKEN --saveAudio --saveAudioAsWav
- Edit flow.py to specify a resource within the synthesis request, for example a user dictionary uploaded with the storage API.
from nuance.tts.v1.synthesizer_pb2 import * . . . # Synthesis request request = SynthesisRequest() request.voice.name = "Evan" request.voice.model = "enhanced" pcm = PCM(sample_rate_hz=22050) request.audio_params.audio_format.pcm.CopyFrom(pcm) user_dict = SynthesisResource() # Add a user dictionary user_dict.type = EnumResourceType.USER_DICTIONARY user_dict.uri = "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_dict/en-us/mix.tts" request.input.resources.extend([user_dict]) request.input.text.text = "This is a test. A very simple test." #Add request to list list_of_requests.append(request)
- Run the client using the script file.
$ ./run-mix-client.sh
See the results at the right and notice the user dictionary listed under resources.
Other input: SSML and control codes
The input in these examples is plain text ("This is a test," etc.) but you can also provide input in the form of SSML and control codes.
See Reference topics - Input to synthesize for details and examples you can use in this sample application.
What's list_of_requests?
The application expects all input files to declare a global array named list_of_requests. It sequentially processes the requests contained in that array.
You may optionally instruct the application to wait a number of seconds between requests, by appending a number value to list_of_requests. For example:
list_of_requests.append(request1) list_of_requests.append(1.5) list_of_requests.append(request2)
Once request1 is complete, the application pauses for 1.5 seconds before executing request2.
Run client for unary response
Unary response gives one response for each request
...
2021-09-09 14:28:00,425 (140444352841536) INFO Sending Unary Synthesis request
2021-09-09 14:28:00,425 (140444352841536) INFO Received audio: 127916 bytes
2021-09-09 14:28:00,425 (140444352841536) INFO First chunk latency: 0.1435282602906227 seconds
2021-09-09 14:28:00,425 (140444352841536) INFO Average first-chunk latency (over 1 synthesis requests): 0.1435282602906227 seconds
2021-09-09 14:28:00,426 (140444352841536) INFO Received events
2021-09-09 14:28:00,428 (140444352841536) INFO events {
. . .
2021-09-09 14:28:00,428 (140444352841536) INFO Received status response: SUCCESS
2021-09-09 14:28:00,429 (140444352841536) INFO Wrote audio to flow.py_i1_s1.wav
2021-09-09 14:28:00,429 (140444352841536) INFO Done running file [flow.py]
2021-09-09 14:28:00,431 (140444352841536) INFO Iteration #1 complete
2021-09-09 14:28:00,431 (140444352841536) INFO Average first-chunk latency (over 1 synthesis requests): 0.1435282602906227 seconds
2021-09-09 14:28:00,431 (140444352841536) INFO Done
By default, the synthesized voice is streamed back to the client, but you may request a unary (non-streamed, single package) response. Using the sample client, include the ‑‑sendUnary argument as you run mix-client.py in run-mix-client.sh, for example:
. . . ./mix-client.py --token $MY_TOKEN --saveAudio --saveAudioAsWav --sendUnary
This example uses the same input flow.py file as Run client for synthesis. In this unary response, the request returns a single non-streamed audio package. See the results at the right.
If you have multiple requests, each request returns a single audio package.
See also Streamed vs. unary response.
Sample storage client
Download and extract the sample storage client
$ unzip sample-storage-client.zip
Archive: sample-storage-client.zip
inflating: run-storage-client.sh
inflating: storage-client.py
$ chmod +x storage-client.py
$ chmod +x run-storage-client.sh
Location of client files, above the directory holding the Python stubs
├── storage-client.py
├── run-storage-client.sh
└── nuance
├── rpc (RPC message files)
└── tts
├── storage
│ └── v1beta1
│ ├── storage_pb2_grpc.py
│ ├── storage_pb2.py
│ └── storage.proto
└── v1 (Synthesizer files)
This section contains a Python client for uploading and deleting synthesis resources using the Storage API. To run this client, you need:
- Python 3.6 or later.
- The generated Python stubs from gRPC setup.
- Your client ID and secret from Prerequisites from Mix.
The OAuth scope for the NVC service:
tts.A zip file containing the client files: sample-storage-client.zip. Download this zip file and extract its files into the same directory as the nuance directory, which contains your proto files and Python stubs.
Give storage-client.py and run-storage-client.sh execute permission with
chmod +x
You can use the application to upload and delete synthesis resources to storage.
Run storage client for help
To check that the client is working, and to see the arguments it accepts, run it using the help (-h or --help) option.
$ ./storage-client.py --help
Some options, shown in bold below, are required in all requests. Others are needed depending on the type.
| Option | Description |
|---|---|
| -h, --help | Show help message. |
| --server_url url | Hostname of NVC server, default localhost. Use tts.api.nuance.co.uk |
| --token token | Access token generated by Nuance Oauth service: https://auth.crt.nuance.co.uk/oauth2/token. See General options next. |
| ‑‑max_chunk_size_bytes num | Maximum size, in bytes, of each file chunk. Default is 4096 (4 MB). |
| --upload | Send an upload RPC. Requires --context_tag, --name, and resource-specific options. One of --upload or --delete is mandatory. |
| --delete | Send a delete RPC. Requires the --uri option. |
| --file file | File to upload. For ActivePrompt database, must be a zip file. |
| --context_tag tag | A group name, either existing or new. If it doesn't exist, it will be created. |
| --name name | A name for the resource within the context. |
| --type type | The resource type, one of: activeprompt, user_dictionary, text_ruleset, or wav. |
| --language code | IETF language code. Required when type is user_dictionary or text_ruleset. |
| --voice voice | A Nuance voice. Required when type is activeprompt. |
| --voice_model model | The voice model. Required when type is activeprompt. |
| --voice_version version | The version of the voice. Required when type is activeprompt. |
| ‑‑vocalizer_studio_version version | The Nuance Vocalizer Studio version. Required when type is activeprompt. |
| --uri urn | For the delete operation, the URN of the object to delete. |
General options
First edit the shell script, run-storage-client.sh, to add your credentials to generate an access token, and check the general access options.
#!/bin/bash CLIENT_ID=<Mix client ID, replace colons with %3A> SECRET=<Mix client secret> export MY_TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" \ "https://auth.crt.nuance.co.uk/oauth2/token" \ -d "grant_type=client_credentials" -d "scope=asr nlu tts" \ | python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`" ./storage-client.py server_url tts.api.nuance.co.uk --token $MY_TOKEN --upload --type user_dictionary --file coffee-dictionary.dcb \ --context_tag coffee_app --name coffee_dict \ --language en-us
Add or verify these values in the shell script:
CLIENT_ID: Your client ID from Mix, starting withappID%3ASECRET: The secret you generated for your client in Mix--server_url: The host name of the NVC service, usuallytts.api.nuance.co.uk--token: The environment variable containing your generated access token, in this example$MY_TOKEN- The OAuth scope,
tts, is included in the script, along with scopes for other Mix services.
Then use the shell script to add the options required for the type of resource you want to upload. See the following scenarios for details.
Upload user dictionary
Follow these steps to upload a user dictionary created in Nuance Vocalizer Studio. See Reference topics - User dictionary.
Make sure run-storage-client.sh contains your credentials as described in General options.
Add the arguments for uploading a user dictionary, for example:
./storage-client.py --server_url tts.api.nuance.co.uk --token $MY_TOKEN \ --upload --type user_dictionary --file coffee-dictionary.dcb \ --context_tag coffee_app --name coffee_dict \ --language en-us
Run the client using the script file to upload the user dictionary.
$ ./run-storage-client.sh 2021-05-20 11:38:36,060 INFO Type is User Dictionary 2021-05-20 11:38:36,205 INFO Done reading data 2021-05-20 11:38:36,474 INFO status { status_code: OK } uri: "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_dict/en-us/mix.tts?type=userdict
To use this dictionary in your synthesis requests, reference it using the URN. The type=userdict field is for information only and is not required as part of the reference.
Upload ActivePrompts
Follow these steps to upload an ActivePrompt database created in Nuance Vocalizer Studio. See Reference topics - ActivePrompt database.
Make sure run-storage-client.sh contains your credentials as described in General options.
Add the arguments for uploading an ActivePrompt database, for example:
./storage-client.py --server_url tts.api.nuance.co.uk --token $MY_TOKEN \ --upload --type activeprompt --file coffee-activeprompts.zip \ --context_tag coffee_app --name coffee_prompts \ --voice evan --voice_model enhanced --voice_version 1.0.0 \ --vocalizer_studio_version 3.4
Run the client using the script file to upload the ActivePrompt database.
$ ./run-storage-client.sh 2021-05-20 11:40:16,389 INFO Type is ActivePromptDB 2021-05-20 11:40:16,648 INFO Done reading data 2021-05-20 11:40:16,961 INFO status { status_code: OK } uri: "urn:nuance-mix:tag:tuning:voice/coffee_app/coffee_prompts/evan/mix.tts?type=activeprompt"
To use this ActivePrompt database in your synthesis requests, reference it using the URN. The type=activeprompt field is for information only and is not required as part of the reference.
Upload rulesets
Follow these steps to upload a text ruleset. (Binary, or encrypted, rulesets are not supported.) See Reference topics - Ruleset.
Make sure run-storage-client.sh contains your credentials as described in General options.
Add the arguments for uploading a text ruleset, for example:
./storage-client.py --server_url tts.api.nuance.co.uk --token $MY_TOKEN \ --upload --type text_ruleset --file coffee-ruleset.rst.txt \ --context_tag coffee_app --name coffee_rules \ --language en-us
Run the client using the script file to upload the ruleset.
$ ./run-storage-client.sh 2021-05-20 11:44:08,234 INFO Type is Text User Ruleset 2021-05-20 11:44:08,386 INFO Done reading data 2021-05-20 11:44:08,476 INFO status { status_code: OK } uri: "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_rules/en-us/mix.tts?type=textruleset"
To use this ruleset in your synthesis requests, reference it using the URN. The type=textruleset field is for information only and is not required as part of the reference.
Upload audio
Follow these steps to upload an audio wave file. See Reference topics - Audio file.
Make sure run-storage-client.sh contains your credentials as described in General options.
Add the arguments for uploading an audio file, for example:
./storage-client.py --server_url tts.api.nuance.co.uk --token $MY_TOKEN \ --upload --type wav --file greetings.wav \ --context_tag coffee_app --name audio_hi
Run the client using the script file to upload the audio file.
$ ./run-storage-client.sh 2021-05-20 11:53:55,761 INFO Type is Wav 2021-05-20 11:53:56,080 INFO Done reading data 2021-05-20 11:53:56,189 INFO status { status_code: OK } uri: "urn:nuance-mix:tag:tuning:audio/coffee_app/audio_hi/mix.tts?type=wav"
To use this audio recording in your synthesis requests, reference it using the URN. The type=wav field is for information only and is not required as part of the reference.
Delete resource
If you need to remove a resource from storage, include the --delete option and the resource URN.
Make sure run-storage-client.sh contains your credentials as described in General options.
Add the arguments for deleting a resource. For example, this removes a previously-uploaded ruleset:
./storage-client.py --server_url tts.api.nuance.co.uk --token $MY_TOKEN \ --delete \ --uri urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_rules/en-us/mix.tts
Run the client using the script file to delete the resource.
$ ./run-storage-client.sh 2021-05-26 08:53:51,584 INFO status { status_code: OK }
The resource is removed from storage.
Reference topics
This section provides more information about topics in the gRPC APIs.
Status codes
An HTML status code is returned for all requests.
| Code | Message | Indicates |
|---|---|---|
| 200 | Success | Successful response. |
| 400 | Bad request | A malformed or unsupported client request was rejected. |
| 401 | Unauthenticated | Request could not be authorized. See Authorize. |
| 403 | Forbidden | A restricted voice was requested but you are not authorized to use it. |
| 413 | Payload too large | A synthesis request has exceeded the limits for voice switching. |
| 500 | Internal server error | An unknown error has occurred on the server. |
| 502 | Resource error | An error has occurred with a synthesis resource. |
Streamed vs. unary response
One request, two possible responses (from proto file)
service Synthesizer {
rpc Synthesize(SynthesisRequest) returns (stream SynthesisResponse) {}
rpc UnarySynthesize(SynthesisRequest) returns (UnarySynthesisResponse {}
. . .
message SynthesisRequest {
Voice voice = 1;
AudioParameters audio_params = 2;
Input input = 3;
EventParameters event_params = 4;
map<string, string> client_data = 5;
}
message SynthesisResponse {
oneof response {
Status status = 1;
Events events = 2;
bytes audio = 3;
}
}
message UnarySynthesisResponse {
Status status = 1;
Events events = 2;
bytes audio = 3;
}
NVC offers two types of synthesis response: a streamed response available in SynthesisResponse and a non-streamed response in UnarySynthesisResponse.
The request is the same in both cases: SynthesisRequest specifies a voice, the input text to synthesize, and optional parameters. The response can be either:
SynthesisResponse: Returns one status message followed by multiple streamed audio buffers, each including the markers or other events specified in the request. Each audio buffer contains the latest synthesized audio.
UnarySynthesisResponse: Returns one status message and one audio buffer, containing all the markers and events specified in the request. The underlying NVC engine caps the audio response size.
See Run client for unary response to run the sample Python client with a unary response, activated by a command line flag.
Defaults
The proto file provides the following defaults for messages in SynthesisRequest. Mandatory fields are shown in bold.
| Items in SynthesisRequest | Default | |||
|---|---|---|---|---|
| voice (Voice) | ||||
| name | Mandatory, e.g. Evan | |||
| model | Mandatory, e.g. enhanced | |||
| age_group (EnumAgeGroup) | ADULT | |||
| gender (EnumGender) | ANY | |||
| audio_params (AudioParameters) | ||||
| audio_format (AudioFormat) | PCM 22.5kHz | |||
| volume_percentage | 80 | |||
| speaking_rate_factor | 1.0 | |||
| audio_chunk_duration_ms | 20000 (20 seconds) | |||
| target_audio_length_ms | 0, meaning no maximum duration | |||
| disable_early_emission | False: Send audio segments as soon as possible | |||
| input (Input) | ||||
| text (Text) | Mandatory: one of text, tokenized_sequence, or ssmls | |||
| tokenized_sequence (TokenizedSequence) | ||||
| ssml (SSML) | ||||
| ssml_validation_mode (EnumSSMLValidationMode) | STRICT | |||
| escape_sequence (non-modifiable field) | \! and <ESC> | |||
| resources (SynthesisResource) | ||||
| type (EnumResourceType) | USER_DICTIONARY | |||
| lid_params (LanguageIdentificationParameters) | ||||
| disable | False: LID is turned on | |||
| languages | Empty, meaning use all available languages | |||
| always_use_ highest_confidence | False: Use highest language with any confidence score | |||
| download_params (DownloadParameters) | ||||
| headers | Empty | |||
| refuse_cookies | False: Accept cookies | |||
| request_timeout_ms | NVC server default, usually 30000 (30 seconds) | |||
| event_params (EventParameters) | ||||
| send_sentence_marker_events | False: Do not send | |||
| send_word_marker_events | False: Do not send | |||
| send_phoneme_marker_events | False: Do not send | |||
| send_bookmark_marker_events | False: Do not send | |||
| send_paragraph_marker_events | False: Do not send | |||
| send_visemes | False: Do not send | |||
| send_log_events | False: Do not send | |||
| suppress_input | False: Include text and URIs in logs | |||
| client_data | Empty | |||
| user_id | Empty | |||
Input to synthesize
Plain text input
SynthesisRequest (
voice = Voice (
name = "Evan",
model = "enhanced"),
input.text.text = "Your order will be ready to pick up in 45 minutes."
)
SSML input containing plain text only
SynthesisRequest (
voice = Voice (
name = "Evan",
model = "enhanced"),
input = Input (
ssml = SSML (
text = "<speak>It's 24,901 miles around the earth, or 40,075 km.</speak>",
ssml_validation_mode = WARN)
)
)
SSML input containing text and SSML elements to change the volume
SynthesisRequest (
voice = Voice (
name = "Evan",
model = "enhanced"),
input = Input (
ssml = SSML (
text = '<speak><prosody volume="10">I can speak rather quietly,</prosody>
<prosody volume="90">But also very loudly.</prosody></speak>',
ssml_validation_mode = WARN)
)
)
Tokenized sequence input
SynthesisRequest (
voice = Voice (
name = "Evan",
model = "enhanced"),
input = Input (
tokenized_sequence = TokenizedSequence (
tokens = [
Token (text = "My name is "),
Token (control_code = ControlCode (key = "pause", value = "300")),
Token (text = "Jeremiah Jones") ]
)
)
)
You provide the text for NVC to synthesize in the Input message. It can be plain text, SSML code, or a sequence of plain text and Nuance control codes.
If you are using the Sample synthesis client, enter the different types of input as request.input lines in the input file, flow.py. (When flow.py contains multiple requests, it executes only the last uncommented section.) For example, using an American English voice:
Plain text input, synthesized as: "Your order will be ready to pick up in forty five minutes."
request.input.text.text = "Your order will be ready to pick up in 45 minutes."
SSML input, synthesized as "It’s twenty four thousand nine hundred one miles around the earth, or forty thousand seventy five kilometers."
request.input.ssml.text = "<speak>It's 24,901 miles around the earth, or 40,075 km.</speak>"
SSML input with elements, synthesized as "I can speak rather quietly, BUT ALSO VERY LOUDLY."
request.input.ssml.text = '<speak><prosody volume="10">I can speak rather quietly, </prosody><prosody volume="90">But also very loudly.</prosody></speak>'
Tokenized sequence of text and Nuance control codes, synthesized as: "My name is... Jeremiah Jones."
request.input.tokenized_sequence.tokens.extend([ Token(text="My name is "), Token(control_code=ControlCode(key="pause", value="300")), Token(text="Jeremiah Jones") ])
Another tokenized sequence, synthesized as: "The time and date is: ten o'clock, May twenty-sixth, two thousand twenty. My phone number is: one eight hundred, six eight eight, zero zero six eight."
request.input.tokenized_sequence.tokens.extend([ Token(text="The time and date is."), Token(control_code=ControlCode(key="tn", value="time")), Token(text="10:00"), Token(control_code=ControlCode(key="pause", value="300")), Token(control_code=ControlCode(key="tn", value="date")), Token(text="05/26/2020"), Token(control_code=ControlCode(key="pause", value="300")), Token(text="My phone number is."), Token(control_code=ControlCode(key="tn", value="phone")), Token(text="1-800-688-0068") ])
SSML tags
Generic example, with optional elements omitted
<speak>Text before SSML element.
<prosody volume="10">Text following or affected by SSML element code.</prosody>
</speak>
Optional elements may be included without error
<?xml version="1.0"?>
<speak xmlns="http://www.w3.org/2001/10/synthesis" xml:lang="en-US" version="1.0">
Text before SSML element.
<prosody volume="10">Text following or affected by SSML element code.</prosody>
</speak>
Examples using flow.py with sample client
# You can enclose the SSML in double quotes with single quotes inside
request.input.ssml.text = "<speak>It's easy. Take a deep breath, pause for a second or two <break time='1500ms'/> and then exhale slowly.</speak>"
# Or vice versa, escaping any apostrophes
request.input.ssml.text = '<speak>It\'s easy. Take a deep breath, pause for a second or two <break time="1500ms"/> and then exhale slowly.</speak>'
# Or enclose in three single (or double) quotes for multiline text
request.input.ssml.text = '''<speak>It's easy.
Take a deep breath, pause for a second or two
<break time="1500ms"/> and then exhale slowly.
</speak>'''
SSML elements may be included when using the input type Input - SSML. These tags indicate how the text segments within the tag should be spoken.
See Control codes to accomplish the same type of control in tokenized sequence input.
NVC supports the following SSML elements and attributes in SSML input. For details about these items, see SSML Specification 1.0. Note that NVC does not support all SSML elements and attributes listed in the W3C specification.
Switching voice and/or language
You can change the voice and/or the language of the speaker within SSML input, using several methods. These elements change to a voice with a different language:
And this control code changes the language in a multilingual voice:
langwith escape codes
xml
xml (optional) and speak (with optional attributes)
<speak>Input text and tags</speak>
Optional elements may be included if wanted
<?xml version="1.0"?>
<speak xmlns="http://www.w3.org/2001/10/synthesis" xml:lang="en-US" version="1.0">
Input text and tags</speak>
An XML declaration, specifying the XML version, 1.0.
In NVC, this element is optional. If omitted, NVC adds it automatically.
speak
The root SSML element. Mandatory. It contains the required attributes, xml:lang and version, and encloses text to be synthesized along with optional elements shown below. The xml:lang attribute sets the base language for the synthesis.
In NVC, the attributes of this element are optional: only <speak> is required. If the attributes are omitted, NVC adds them automatically to the speak element.
Optional attributes may be specified if wanted. If you include the language with xml:lang, it must match the language of the principal voice.
audio
Audio file in cloud storage via URN
<speak>Please leave your name after the tone.
<audio src="urn:nuance-mix:tag:tuning:audio/coffee_app/beep/mix.tts" />
</speak>
Audio file via secure URL
<speak>Please leave your name after the tone.
<audio src="https://mtl-host42.nuance.co.uk/audio/beep.wav" />
</speak>
The audio element inserts a digital audio recording at the current location. The src attribute specifies the location of the recording as either:
A URN in Mix cloud storage. Use the Storage API to upload the audio file. See Sample storage client - Upload audio.
A secure URL. The file must be a WAV file on a web server accessed through a secure (https) URL, with a valid TLS certificate.
Alternative text
Alternative text for URN or URL access
<speak>Please leave your name after the tone.
<audio src="urn:nuance-mix:tag:tuning:audio/coffee_app/beep/mix.tts">Beep</audio>
</speak>
<speak>Please leave your name after the tone.
<audio src="https://mtl-host42.nuance.co.uk/audio/beep.wav">Beep</audio>
</speak>
For both URN and URL access, you may include alternative text in the <audio> element. If the audio file cannot be found or is not a WAV file, NVC synthesizes the alternative text and includes it in the results. In these examples, if the audio file is unavailable, the synthesis results are: "Please leave your name after the tone. Beep."
Without the alternative text, NVC reports an error if the file is not a WAV file or is not accessed through a URN or an https URL.
WAV format
NVC supports WAV files containing 16-bit PCM samples.
break
break
<speak>His name is <break time="300ms"/> Michael. </speak>
<speak>Tom lives in New York City. So does John. He\'s at 180 Park Ave. <break strength="none"/> Room 24.</speak>
The break element controls pausing between words, overriding the default breaks based on punctuation in the text. The break tag has two optional attributes:
timespecifies the duration of the break as seconds (1s) or milliseconds (300ms).strengthspecifies a keyword to indicate the duration of the break: none, x-weak, weak, medium (default), strong, or x-strong.break strength="none"can prevent a pause (caused by a comma or period, for example) that would otherwise occur.
These examples are read as: "His name is... Michael" and "Tom lives in New York City. So does John. He’s at one hundred eighty Park Avenue room twenty four." Notice there's no break between "Park Avenue" and "room twenty four."
lang
lang using escape code, in input flow file
request.voice.name = "Zoe-Ml"
request.voice.model = "enhanced"
request.input.ssml.text = "<speak>Hello and welcome to \!\lang=fr-CA\ St-Jean-sur-Richelieu \!\lang=normal\. </speak>"
When used in SSML with a multilingual (-Ml) voice, the lang control code switches to another language supported by the voice. This example uses Zoe-Ml, defined with two languages apart from American English.
voices {
name: "Zoe-Ml"
model: "enhanced"
language: "en-us"
. . .
foreign_languages: "es-mx"
foreign_languages: "fr-ca"
}
In this example, Zoe starts in her English voice, then switches to her French voice to read "St-Jean-sur-Richelieu" using French pronunciation. When lang is used with a non-multilingual voice, the text is pronounced using the voice's base language.
This code is supported in SSML using escape code format, as shown.
mark
mark
<speak>This bookmark <mark name="bookmark1"/> marks a reference point.
Another <mark name="bookmark2"/> does the same.</speak>
The mark element inserts a bookmark that is returned in the results. The value can be any string.
p
p
<speak><p>Welcome to Vocalizer.</p>
<p>Vocalizer is a state-of-the-art text to speech system.</p></speak>
p with change to a Spanish voice
<speak>Say English for an English message.
<p xml:lang="es-MX">O decir español para un mensaje en español.</p></speak>
The p element indicates a paragraph break. A paragraph break is equivalent to break strength="x-strong".
The optional xml:lang attribute switches to a voice whose base language is the locale specified. It does not use a foreign language of the current voice. If possible, the same gender as the original voice is used.
In the second scenario, installed voices include en-US voices, Evan and Zoe-Ml, as well as es-MX voices, Javier and Paulina-Ml. In this example, Evan reads the English text, then Javier reads the Spanish. When starting with Zoe-Ml, the female Paulina-Ml voice is selected as the Spanish voice.
prosody
The prosody element specifies intonation in the generated voice using several attributes. You may combine multiple attributes within the same prosody element.
prosody - pitch
prosody - pitch
<speak>Hi, I\'m Zoe. This is the normal pitch and timbre of my voice.
<prosody pitch="80" timbre="90">But now my voice sounds lower and richer.</prosody></speak>
Prosody pitch changes the speaking voice to sound lower (lower values) or higher (higher values). Not supported for all languages. The value is a keyword, a number (50-200, default is 100), or a relative percentage (+/-n%). The keywords are:
- x-low (-30%)
- low (-15%)
- medium (0%)
- default (0%)
- high
- x-high
You may combine pitch, rate, and timbre for more precise results. For example, pitch and timbre values of 80 or 90 for a female voice give a more neutral voice.
prosody - rate
prosody - rate
<speak>This is my normal speaking rate.
<prosody rate="+50%"> But I can speed up the rate.</prosody>
<prosody rate="-25%"> Or I can slow it down.</prosody></speak>
Prosody rate sets the speaking rate as a keyword, a number (0-100), or a relative percentage (+/-n%). The keywords are:
- x-slow (-50%)
- slow (-30%)
- medium (0%)
- fast (+60%)
- x-fast (+150%)
prosody - timbre
prosody - timbre
<speak>This is the normal timbre of my voice.
<prosody timbre="young"> I can sound a bit younger. </prosody>
<prosody timbre="old" rate="-10%"> Or older and hopefully wiser. </prosody></speak>
Prosody timbre changes the speaking voice to sound bigger and older (lower values) or smaller and younger (higher values). Not supported for all languages. The value is a keyword, a number (50-200, default is 100), or a relative percentage (+/-n%). The keywords are:
- x-young (+35%)
- young (+20%)
- medium (0%)
- default (0%)
- old (-20%)
- x-old (-35%)
prosody - volume
prosody - volume
<speak>This is my normal speaking volume.
<prosody volume="-50%">I can also speak rather quietly,</prosody>
<prosody volume="+50%"> or also very loudly.</prosody></speak>
Prosody volume changes the speaking volume. The value is a keyword, a number (0-100), or a relative percentage (+/-n%). The keywords are: silent, x-soft, soft, medium (default), loud, or x-loud.
s
s
<speak><s>The wind was a torrent of darkness, among the gusty trees</s>
<s>The moon was a ghostly galleon, tossed upon cloudy seas</s></speak>
p with change to a French Canadian voice
<speak>The name of the song is <s xml:lang="fr-CA"> Je ne regrette rien.</s></speak>
The s element indicates a sentence break. A sentence break is equivalent to break strength="strong".
The optional xml:lang attribute works as for the p element. In this example, it switches to a fr-CA voice to say the name of the song.
say-as
say-as
<speak>My address is: <say-as interpret-as="address">Apt. 17, 28 N. Whitney St., Saint Augustine Beach, FL 32084-6715</say-as></speak>
<say-as interpret-as="currency">12USD</say-as>
<say-as interpret-as="date">11/21/2020</say-as>
<say-as interpret-as="name">Care Telecom Ltd</say-as>
<say-as interpret-as="name">King Richard III</say-as>
<say-as interpret-as="ordinal">12th</say-as>
<say-as interpret-as="phone">1-800-688-0068</say-as>
<say-as interpret-as="raw">app.</say-as>
<say-as interpret-as="sms">CU :-)</say-as>
<say-as interpret-as="spell" format="alphanumeric">a34y - 347</say-as>
<say-as interpret-as="spell" format="strict">a34y - 347</say-as>
<say-as interpret-as="state">FL</say-as>
<say-as interpret-as="streetname">Emerson Rd.</say-as>
<say-as interpret-as="streetnumber">11001-11010</say-as>
<say-as interpret-as="time">10:00</say-as>
<say-as interpret-as="zip">01803</say-as>
The say-as element controls how to say specific types of text, using the interpret-as attribute to specify a value and (in some cases) a format. A wide range of input is accepted for most values. The values are:
address: Provides optimal reading for complete postal addresses. For example, "Apt. 17, 28 N. Whitney St., Saint Augustine Beach, FL 32084-6715" is read as "apartment seventeen, twenty eight north Whitney street, Saint Augustine Beach, Florida three two zero eight four six seven one five."
currency: Reads text as currency. For example, "123.45USD" is read as "one hundred twenty three U S dollars and forty five cents."
date: Reads text as a date. For example, "11/21/2020" is read as "November twenty-first, two thousand twenty." The
formatattribute is ignored for date values. It may be specified without error but has no effect.The precise date output is determined by the voice, and ambiguous dates are interpreted according to the conventions of the voice's locale. For example, "05/12/2020" is read by an American English voice as "May twelfth two thousand twenty" and by a British English voice as "the fifth of December two thousand and twenty."
name: Gives correct reading of names, including personal names with roman numerals, such as Pius IX (read as "Pius the ninth"), John I ("John the first"), and Richard III ("Richard the third"). The name must be capitalized but the roman numeral may be in upper or lowercase (III or iii). Do not add a punctuation mark immediately following the roman numeral.
ordinal: Reads positional numbers such as 1st, 2nd, 3rd, and so on. For example, "12th" is read as "twelfth."
phone: Reads telephone numbers. For example, "1-800-688-0068" is read as "One, eight hundred, six eight eight, zero zero six eight."
raw: Provides a literal reading of the text, such as blocking undesired abbreviation expansion. It operates principally on the abbreviations and acronyms but may impact the surrounding text as well.
sms: Gives short message service (SMS) reading. For example, "ttyl, James, :-)" is read as "Talk to you later, James, smiley happy."
spell format=alphanumeric: Spells out all alphabetic and numeric characters, but does not read white space, special characters, and punctuation marks. This is how items are spoken with and without this tag, in American English.
Input With spell - alphanumeric Without spell - alphanumeric a34y - 347 A three four Y three four seven a thirty-four y three hundred forty-seven 12345 one two three four five twelve thousand three hundred forty-five Smythe capital S M Y T H E smith spell format=strict: Spells out all characters, including white space, special characters, and punctuation marks. For example, "a34y - 347" is pronounced "A three four Y space hyphen space three four seven."
For both types of spelling, accented and capital characters are indicated. For example: "café" is spoken as "C A F E acute" and "Abc" is spoken as "capital A B C."
state: Expands and pronounces state, city, and province names and abbreviations, as appropriate for the locale. For example, "FL" is read as "Florida." Not supported for all languages.
streetname: Reads street names and abbreviations. For example, "Emerson Rd." is prounounced "Emerson road." Not supported for all languages.
streetnumber: Reads street numbers. For example, "11001-11010" is read as "eleven oh oh one to eleven oh ten." Not supported for all languages.
time: Gives a time of day reading. For example, "10:00" is pronounced "ten o'clock." The
formatattribute is ignored for time values. It may be specified without error but has no effect.zip: Reads US zip codes. Supported for American English only.
style
style
<speak>Hello, this is Samantha. <style name="lively">Hope you’re having a nice day!</style></speak>
<speak>Hello, this is Samantha. <style name="lively">Hope you’re having a nice day!</style>
<voice name="nathan">Hello, this is Nathan.</voice></speak>
The style element sets the speaking style of the voice. Values for name depend on the voice but are usually neutral, lively, forceful, and apologetic. The default depends on the voice. If you request a style that the voice does not support, there is no effect.
The first example reads "Hello, this is Samantha" in Samantha's default style, then switches to lively style to say "Hope you're having a nice day!"
The style resets to default at the end of the synthesis request or if it encounters a change of voice. The second example continues with Nathan in default style saying "Hello, I am Nathan."
voice
voice
<speak><voice name="samantha">Hello, this is Samantha. </voice>
<voice name="tom">Hello, this is Tom.</voice></speak>
This voices changes to a French voice, Audrey-Ml
<speak>Hi, my name is Zoe.
<voice name="Audrey-Ml">Bonjour, je m\'appelle Audrey.</voice></speak>
The voice element changes the speaking voice, which also forces a sentence break. Values for name are the voices available to the session.
If you specify a voice with another language, the text is spoken using that language.
Control codes
Tokenized sequence structure
SynthesisRequest - Input - TokenizedSequence -
Token (text = "Text before control code"),
Token (control_code=ControlCode (key="code name", value="code value")),
Token (text = "Text following or affected by control code")
Example using flow.py with sample client
request.input.tokenized_sequence.tokens.extend([
Token (text = "My name and address is: "),
Token (control_code = ControlCode (key = "tn", value = "name")),
Token (text = "Aardvark & Sons Co. Inc.,"),
Token (control_code = ControlCode (key = "tn", value = "address")),
Token (text = "123 E. Forest Ave., Portland, ME 04103"),
Token (control_code = ControlCode (key = "tn", value = "normal"))
])
Control codes, sometimes known as control sequences, may be included in the input text when using the input type Input - TokenizedSequence. These codes indicate how the text segments following the code should be spoken.
See Input to synthesize for an example using the sample client.
See SSML tags to accomplish the same types of control in SSML input.
Nuance supports the following control codes and values in TokenizedSequence.
audio
Audio file in cloud storage via URN
Token (text = "Please leave your name after the tone. "),
Token (control_code = ControlCode (key = "audio",
value = "urn:nuance-mix:tag:tuning:audio/coffee_app/beep/mix.tts"))
Audio file from URL
Token (text = "Please leave your name after the tone. "),
Token (control_code = ControlCode (key = "audio",
value = "https://mtl-host42.nuance.co.uk/audio/beep.wav"))
The audio code inserts a digital audio recording at the current location. The value attribute specifies the location of the recording, as either:
A URN in Mix cloud storage. Use the Storage API to upload the audio file. See Sample storage client - Upload audio.
A secure URL. The file must be a WAV file on a web server accessed through a secure (https) URL, with a valid TLS certificate.
NVC supports WAV files containing 16-bit PCM samples.
If the audio file cannot be found or is not a WAV file, NVC reports an error. With the Synthesize method, NVC synthesizes any text tokens in the sequence but does not download or include the file. In these examples, if the audio file is unavailable, the results are only: "Please leave your name after the tone."
With UnarySynthesize, NVC does not synthesize anything and simply reports an error.
eos
eos
Token (text = "Tom lives in the U.S."),
Token (control_code=ControlCode (key="eos", value="1")),
Token (text = "So does John. 180 Park Ave."),
Token (control_code=ControlCode (key="eos", value="0")),
Token (text = "Room 24")
The eos code controls end-of-sentence detection. Values are:
- 1: Forces a sentence break.
- 0: Suppresses a sentence break. To suppress a sentence break, eos 0 must appear immediately after the symbol (such as a period) that triggers the break.
To disable automatic end-of-sentence detection for a block of text, use readmode explicit_eos.
lang
lang with unknown
Token (text = "The name of the song is."),
Token (control_code=ControlCode (key="lang", value="unknown")),
Token (text = "Au clair de la lune."),
Token (control_code=ControlCode (key="lang", value="normal")),
Token (text = "It's a folk song meaning, in the light of the moon.")
lang with specific language
Token (text = "Hello and welcome to the city of "),
Token (control_code=ControlCode (key="lang", value="fr-CA")),
Token (text = "St-Jean-sur-Richelieu."),
Token (control_code=ControlCode (key="lang", value="normal"))
The lang code labels text identified as from an unknown language, or a specific language. Values are:
- normal: The current voice language.
- unknown: Any other language.
- xx-XX: A specific language
The value lang unknown labels all text from that position (up to a lang normal or the end of input) as being from an unknown language. NVC then uses its language identification feature on a sentence-by-sentence basis to determine the language, and switches to a voice for that language if necessary. The original voice is restored at the next lang normal or the end of the synthesis request.
See LanguageIdentificationParameters.
Language identification is only supported for a limited set of languages.
When used with a multilingual (-Ml) voice, the lang code switches to another language supported by the voice. This example uses Zoe-Ml, defined with two languages apart from American English.
voices {
name: "Zoe-Ml"
model: "enhanced"
language: "en-us"
. . .
foreign_languages: "es-mx"
foreign_languages: "fr-ca"
}
In this example, the voice reads "St-Jean-sur-Richelieu" using French pronunciation, while the rest of the sentence is in English. When the lang code is used with a non-multilingual voice, "St-Jean-sur-Richelieu" is pronounced using the voice's base language.
mrk
mrk
Token (control_code=ControlCode (key="mrk", value="important")),
Token (text = "This is an important point. ")
The mrk code inserts a bookmark that is returned in the results. The value can be any name.
pause
pause
Token (text = "My name is "),
Token (control_code=ControlCode (key="pause", value="300")),
Token (text = "Jeremiah Jones. ")
The pause code inserts a pause of a specified duration in milliseconds. Values from 1 to 65,535.
para
para
Token (text = "Introduction to Vocalizer"),
Token (control_code=ControlCode (key="para")),
Token (text = "Vocalizer is a state-of-the-art text-to-speech system.")
The para code indicates a paragraph break and implies a sentence break. The difference between this and eos 1 (end of sentence) is that this triggers the delivery of a paragraph mark event.
pitch
pitch
Token (text = "Hi I'm Zoe. This is the normal pitch and timbre of my voice."),
Token (control_code=ControlCode (key="pitch", value="80")),
Token (control_code=ControlCode (key="timbre", value="90")),
Token (text = "But now my voice sounds lower and richer.")
The pitch code changes the speaking voice to sound lower (lower values) or higher (higher values). Values are between 50 and 200, and 100 is typical.
You may combine pitch, rate, and timbre for more precise results. For example, pitch and timbre values of 80 or 90 for a female voice give a more neutral voice.
prompt
prompt
Token (control_code=ControlCode (key="prompt", value="banking::confirm_account_number")),
Token (text = "Thanks ")
The prompt code inserts an ActivePrompt at a specific location in the text. The value is the name of the prompt within an ActivePrompt database.
To use an ActivePrompt database, you must upload it to central storage using UploadRequest and load it into the session using SynthesisRequest - Input - SynthesisResource - EnumResourceType - ACTIVEPROMPT_DB or ACTIVEPROMPT_DB_AUTO.
rate
rate
Token (text = "I can "),
Token (control_code=ControlCode (key="rate", value="75")),
Token (text = "speed up the rate"),
Token (control_code=ControlCode (key="rate", value="25")),
Token (text = "or slow it down")
The rate code sets the speaking rate as a percentage of the default speaking rate. Values are from 1 to 100, with 50 as the default rate.
You may combine the pitch, rate, and timbre codes for more precise results.
readmode
readmode
Token (control_code=ControlCode (key="readmode", value="sent")),
Token (text = "Please buy green apples. You can also get pears.")
Token (control_code=ControlCode (key="readmode", value="char")),
Token (text = "Apples")
Token (control_code=ControlCode (key="readmode", value="word")),
Token (text = "Please buy green apples.")
Token (control_code=ControlCode (key="readmode", value="line")),
Token (text = "Bananas. Low-fat milk. Whole wheat flour.")
Token (control_code=ControlCode (key="readmode", value="explicit_eos")),
Token (text = "Bananas. Low-fat milk. Whole wheat flour.")
The readmode code changes the reading mode from sentence mode (the default) to specialized modes. Values are the modes:
- sent: Sentence mode (default).
- char: Character-by-character mode, similar to spelling.
- word: Word-by-word mode.
- line: Line-by-line, or list mode, with a pause at the end of each line.
- explicit_eos: Explicit end-of-sentence mode, with sentence breaks only where indicated by eos 1. In the example, the list will be read without sentence breaks.
Return to readmode sent after the specialized readme.
rst
rst
Token (control_code=ControlCode (key="vol", value="10")),
Token (text = "The volume is set to a low value."),
Token (control_code=ControlCode (key="rst")),
Token (text = "Now it is reset to its default value.")
The rst code resets all codes to the default values.
spell
spell
Token (control_code=ControlCode (key="tn", value="spell")),
Token (control_code=ControlCode (key="spell", value="200")),
Token (text = "a134b"),
Token (control_code=ControlCode (key="tn", value="normal"))
The spell code sets the inter-character pause, in milliseconds, for tn - spell. Values are from 1 to 65535.
style
style
Token (text = "Hello, this is Samantha. "),
Token (control_code=ControlCode (key="style", value="lively")),
Token (text = "Hope you're having a nice day!")
Token (text = "Hello, this is Samantha. "),
Token (control_code=ControlCode (key="style", value="lively")),
Token (text = "Hope you're having a nice day!"),
Token (control_code=ControlCode (key="voice", value="nathan")),
Token (text = "Hello, this is Nathan."),
The style code sets the speaking style of the voice. Values depend on the voice but are usually neutral, lively, forceful, and apologetic. The default is usually neutral. If you request a style that the voice does not support, there is no effect.
The first example reads "Hello, this is Samantha" in Samantha's default style, then switches to lively style to say "Hope you're having a nice day!"
The style resets to default at the end of the synthesis request or if it encounters a change of voice. The second example continues with Nathan in default style saying "Hello, this is Nathan."
timbre
timbre
Token (control_code=ControlCode (key="timbre", value="180")),
Token (text = "I can sound quite young. "),
Token (control_code=ControlCode (key="timbre", value="50")),
Token (text = "Or I can sound old and maybe wise. "),
Token (control_code=ControlCode (key="tn", value="normal"))
The timbre code changes the speaking voice to sound bigger and older (lower values) or smaller and younger (higher values). Values are between 50 and 200, and 100 is typical.
You may combine the pitch, rate, and timbre codes for more precise results.
tn
The tn code guides text normalization. Values are the different types of text.
tn - address
tn - address
Token (control_code=ControlCode (key="tn", value="address")),
Token (text = "Apt. 7-12, 28 N. Whitney St., Saint Augustine Beach, FL 32084-6715 "),
Token (control_code=ControlCode (key="tn", value="normal"))
Full name and address
Token (control_code=ControlCode (key="tn", value="name")),
Token (text = "Aardvark & Sons Co. Inc., "),
Token (control_code=ControlCode (key="tn", value="address")),
Token (text = "123 E. Forest Ave., Portland, ME 04103 "),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - address code provides optimal reading for complete postal addresses.
Do not include the name portion of the address to avoid undesired expansions of name-specific abbreviations. Instead, include the name in a separate tn - name section prior to the tn - address.
For example, the full name and address at the right is read as: "Aardvark and Sons Company Incorporated, one two three East Forest avenue, Portland, Maine, zero four one zero three."
tn - alphanumeric
The tn - alphanumeric code is an alias of tn - spell:alphanumeric.
tn - boolean
tn - boolean
Token (control_code=ControlCode (key="tn", value="boolean")),
Token (text = "true "),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - boolean code reads boolean values (true, false, yes, no) by spelling them out. This example spells out "T R U E."
tn - cardinal
The tn - cardinal code is an alias of tn - number.
tn - characters
The tn - characters code is an alias of tn - spell:alphanumeric.
tn - currency
tn - currency
Token (control_code=ControlCode (key="tn", value="currency")),
Token (text = "123.45USD "),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - currency code reads text as currency. For example, "123.45USD" is read as "one hundred twenty three U S dollars and forty five cents."
tn - date
tn - date
Token (control_code=ControlCode (key="tn", value="date")),
Token (text = "11/21/1984 "),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - date code reads text as a date. For example, "11/21/1984" is read as "November twenty-first, nineteen eighty four."
The precise output is determined by the voice, and ambiguous dates are interpreted according to the conventions of the voice's locale. For example, "05/12/2020" is read by an American English voice as "May twelfth two thousand twenty" and by a British English voice as "the fifth of December two thousand and twenty."
tn - digits
The tn - digits code is an alias for tn - spell:alphanumeric.
tn - name
tn - name
Token (control_code=ControlCode (key="tn", value="name")),
Token (text = "Care Telecom Ltd. "),
Token (control_code=ControlCode (key="tn", value="normal"))
Token (text = "I'm talking about "),
Token (control_code=ControlCode (key="tn", value="name")),
Token (text = "King Richard III "),
Token (control_code=ControlCode (key="tn", value="normal")),
Token (text = ". He lived in the 15th century. ")
The tn - name code gives correct reading of names, including personal names with roman numerals, such as Pius IX (read as "Pius the ninth"), John I ("John the first"), and Richard III ("Richard the third"). The name must be capitalized but the roman numeral may be in upper or lowercase (III or iii). Do not include punctuation immediately following the roman numeral in the tn - name text. If punctuation is required, include it in the tn - normal text.
The examples at the right are read as: "Care Telecom Limited" and "I'm talking about Richard the third. He lived in the fifteenth century."
tn - normal
The tn - normal code returns to generic normalization following a text fragment that is normalized in a special way. All the examples in this tn section include tn - normal following the specific normalization segment.
tn - ordinal
tn - ordinal
Token (control_code=ControlCode (key="tn", value="ordinal")),
Token (text = "12th "),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - ordinal code reads positional numbers such as 1st, 2nd, 3rd, and so on.
tn - phone
tn - phone
Token (control_code=ControlCode (key="tn", value="phone")),
Token (text = "1-800-688-0068 "),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - phone code reads telephone numbers. For example, "1-800-688-0068" is read as "One, eight hundred, six eight eight, zero zero six eight."
tn - raw
tn - raw
Token (control_code=ControlCode (key="tn", value="raw")),
Token (text = "app. "),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - raw code provides a literal reading of the text, such as blocking undesired abbreviation expansion. It operates principally on the abbreviations and acronyms but may impact the surrounding text as well.
For example, "app." is read as "app" only, without expanding the abbreviation.
tn - scope
tn - scope
Token (control_code=ControlCode (key="tn", value="biking")),
Token (text = "Welcome to the randonneuring hotline. Every brevet in the series begins on Thursday mornings. "),
Token (control_code=ControlCode (key="tn", value="normal"))
Use the control sequence tn=scope to activate a dictionary for a specific scope. The value of scope is any TN type including any user-defined types you might create.
When creating a dictionary with Vocalizer Studio, you define a scope by assigning a domain to that dictionary. When the dictionary is loaded, the scope is declared as a suffix to the MIME type. When your application supplies marked-up text to be spoken, the mark-up can activate that dictionary by referring to its scope: when the mark-up matches the language and scope of any loaded dictionary, Vocalizer consults that dictionary at runtime. Otherwise, Vocalizer ignores dictionaries that don't match the language and scope.
Imagine you have an English-speaking application for the sport of long-distance bicycling, and many of the technical descriptions use French words such as "brevet" and "randonneuring" with peculiar American pronunciations. You could create a user dictionary designated as a "biking" domain.
In the example at the right, the dictionary might normalize the spoken text as "Welcome to the render nearing hotline. Every brevay in the series begins on Thursday mornings."
tn - sms
tn - sms
Token (control_code=ControlCode (key="tn", value="sms")),
Token (text = "ttyl, James, :-) "),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - sms code gives short message service (SMS) reading. For example, "ttyl, James, :-)" is read as "Talk to you later, James, smiley happy."
tn - spell:alphanumeric
tn - spell:alphanumeric
Token (control_code=ControlCode (key="tn", value="spell:alphanumeric")),
Token (text = "a34y - 347"),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - spell:alphanumeric code spells out all alphabetic and numeric characters, but does not read white space, special characters, and punctuation marks. This is how items are spoken with and without this code, in American English.
| Input | With spell:alphanumeric | Without spell:alphanumeric |
|---|---|---|
| a34y - 347 | A three four Y three four seven | a thirty-four y three hundred forty-seven |
| 12345 | one two three four five | twelve thousand three hundred forty-five |
| Smythe | capital S M Y T H E | smith |
For both types of spell normalization, accented and capital characters are indicated. For example: "café" is spoken as "C A F E acute" and "Abc" is spoken as "capital A B C."
tn - spell:strict
tn - spell:strict
Token (control_code=ControlCode (key="tn", value="spell:strict")),
Token (text = "a34y - 347"),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - spell:strict code spells out all characters, including white space, special characters, and punctuation marks.
For example, "a34y - 347" is pronounced "A three four Y, space hyphen space, three four seven."
tn - state
tn - state
Token (control_code=ControlCode (key="tn", value="state")),
Token (text = "FL"),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - state code expands and pronounces state, city, and province names and abbreviations, as appropriate for the locale. Not supported for all languages.
tn - streetname
tn - streetname
Token (control_code=ControlCode (key="tn", value="streetname")),
Token (text = "Emerson Rd."),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - streetname reads street names and abbreviations. Not supported for all languages.
tn - telephone
The tn - telephone code is an alias of tn - phone.
tn - time
tn - time
Token (control_code=ControlCode (key="tn", value="time")),
Token (text = "10:00"),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - time code gives a time of day reading. For example, 10:00 is pronounced "ten o'clock."
tn- zip
tn - zip
Token (control_code=ControlCode (key="tn", value="zip")),
Token (text = "01803"),
Token (control_code=ControlCode (key="tn", value="normal"))
The tn - zip code reads US zip codes. Supported for American English only.
voice
voice
Token (control_code=ControlCode (key="voice", value="samantha")),
Token (text = "Hello, this is Samantha."),
Token (control_code=ControlCode (key="voice", value="tom")),
Token (text = "Hello, this is Tom.")
voice changes language
Token (control_code=ControlCode (key="voice", value="samantha")),
Token (text = "Hello, this is Samantha."),
Token (control_code=ControlCode (key="voice", value="aurelie")),
Token (text = "Bonjour, je m\'appelle Aurelie.")
The voice code changes the speaking voice, which also forces a sentence break. Values are the voices within the request.
If you specify a voice in another language, the text is spoken using that language.
vol
vol
Token (text = "I can "),
Token (control_code=ControlCode (key="vol", value="10")),
Token (text = "speak rather quietly,"),
Token (control_code=ControlCode (key="vol", value="90")),
Token (text = "but also very loudly.")
The vol code changes the volume as a percentage of maximum volume. Values are from 0 (silent) to 100 (maximum volume). The default is typically 80.
wait
wait
Token (control_code=ControlCode (key="wait", value="2")),
Token (text = "There will be a short wait period after this sentence."),
Token (control_code=ControlCode (key="wait", value="9")),
Token (text = "This sentence will be followed by a long wait. Did you notice the difference? ")
The wait code specifies the end-of-sentence pause duration. Values are from 0 to 9, where the pause is 200 milliseconds multiplied by the value.
Synthesis resources
Synthesis resources are objects that facilitate or improve speech synthesis. The principal resource is a mandatory voice pack and optional resources include user dictionaries, ActivePrompt databases, rulesets, and audio files.
To use these optional resources, upload them to storage using UploadRequest, then reference them in SynthesisResource - type and uri. You may also specify user dictionaries inline, using SynthesisResource - body.
See the following scenarios for details about each type of resource.
Voice pack
NVC works with one or more factory voice packs, available in several languages and locales.
For the list of voices available in the Mix environment, see Languages and Voices - Text-to-Speech (TTS) voices.
You may also query your environment programmatically for supported voices using GetVoicesRequest. See Sample synthesis client - Run client for voices for an example.
For issues relating to voices, see Known issues.
User dictionary
Compile source dictionary in Vocalizer Studio
$ ls
coffee-dictionary.dcb
Upload dictionary to storage
$ run-storage-client.sh --upload --type user_dictionary --file coffee-dictionary.dcb ...
uri: "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_dict/en-us/mix.tts?type=userdict"
Reference dictionary in synthesis session
synthesis_resource = SynthesisResource()
synthesis_resource.type = EnumResourceType.USER_DICTIONARY
synthesis_resource.uri = "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_dict/en-us/mix.tts"
request.input.resources.extend([synthesis_resource])
A user dictionary alters the default pronunciation of words spoken by NVC. For example, you can define the pronunciation of words from foreign languages, expand special acronyms, and tune the pronunciation of words with unusual spelling.
User dictionaries are created using Nuance Vocalizer Studio. For details, see "Specifying pronunciations with user dictionaries" in the Nuance Vocalizer for Enterprise documentation.
The steps for using a user dictionary are:
Compile the source dictionary using Nuance Vocalizer Studio.
Upload the dictionary to storage UploadRequest. See Sample storage client - Upload user dictionary.
UploadResponse returns the complete URN for this dictionary in the response.
Reference the dictionary using its URN using SynthesisRequest - Input - SynthesisResource - USER_DICTIONARY. See Sample synthesis client - Run client with resources.
To remove a resource from storage, use DeleteRequest. See Sample storage client - Delete resource.
Inline dictionary
Source user dictionary
[Header]
Language = ENU
[SubHeader]
Content = EDCT_CONTENT_BROAD_NARROWS
Representation = EDCT_REPR_SZZ_STRING
[Data]
zero // #'zi.R+o&U#
addr // #'@.dR+Es#
adm // #@d.'2mI.n$.'stR+e&I.S$n#
[SubHeader]
Content=EDCT_CONTENT_ORTHOGRAPHIC
Representation=EDCT_REPR_SZ_STRING
[Data]
Info Information
IT "Information Technology"
DLL "Dynamic Link Library"
A-level "advanced level"
Afr africa
Acc account
TEL telephone
Anon anonymous
AP "associated press"
Compiled dictionary referenced in flow.py with SynthesisResource - body
request.input.text.text = "I need to find a DLL."
synthesis_resource = SynthesisResource()
synthesis_resource.type = EnumResourceType.USER_DICTIONARY
synthesis_resource.body = open('/path/to/user_dictionary.dcb', 'rb').read()
request.input.resources.extend([synthesis_resource])
Alternatively, you may reference a dictionary inline, using SynthesisResource - body.
The sample dictionary shown at the right includes the pronunciation of "zero," the expansion and pronunciation of "addr" and "adm," plus the expansion of several abbreviated words and acronyms.
To use this as an inline dictionary:
Compile the source dictionary using Nuance Vocalizer Studio or its conversion tool, dictcpl. In this example, the resulting compiled file is user_dictionary.dcb.
Read the dictionary as a local file in SynthesisResource - body. The example at the right shows user_dictionary.dcb in flow.py, which serves as input to the Sample synthesis client.
Run client.py, the main file in the sample synthesis client. The audio output is: "I need to find a dynamic link library."
ActivePrompt database
Create database in Vocalizer Studio
$ ls
coffee-prompts.zip
Upload database to storage
$ run-storage-client.sh --upload --type activeprompt --file coffee-prompts.zip ...
uri: "urn:nuance-mix:tag:tuning:voice/coffee_app/coffee_prompts/evan/mix.tts?type=activeprompt"
Reference database in synthesis session
synthesis_resource = SynthesisResource()
synthesis_resource.type = EnumResourceType.ACTIVEPROMPT_DB
synthesis_resource.uri = "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_prompts/evan/mix.tts"
request.input.resources.extend([synthesis_resource])
Use a prompt from the database in Nuance control code
Token - ControlCode (key="prompt", value="coffee::confirm_order")
Token - text "Thanks"
An ActivePrompt database is a collection of digital audio recordings and pronunciation instructions that can be used within synthesized speech using the Nuance control code, prompt.
ActivePrompt databases are created using Nuance Vocalizer Studio. For details, see "Tuning TTS output with ActivePrompts" in the Nuance Vocalizer for Enterprise documentation.
To create and use an ActivePrompt database:
Create the database using Nuance Vocalizer studio.
Rename the database to index.dat, and add the database and all recordings to a zip file without a root folder.
Upload the database to storage using UploadRequest. See Sample storage client - Upload ActivePrompts.
UploadResponse returns the complete URN for this database in the response.
Load the database into a synthesis session with its URN using SynthesisRequest - Input - SynthesisResource - ACTIVEPROMPT_DB or ACTIVEPROMPT_DB_AUTO. See Sample synthesis client - Run client with resources.
Reference prompts in the database in SynthesisRequest - Input - TokenizedSequence - prompt code. See Control codes - prompt.
To remove a resource from storage, use DeleteRequest. See Sample storage client - Delete resource.
Ruleset
Create or obtain text ruleset
$ ls
coffee-ruleset.rst.txt
Upload ruleset to storage
$ run-storage-client.sh --upload --type text_ruleset --file coffee-ruleset.rst.txt ...
uri: "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_rules/en-us/mix.tts?type=textruleset"
Reference ruleset in synthesis session
synthesis_resource = SynthesisResource()
synthesis_resource.type = EnumResourceType.TEXT_USER_RULESET
synthesis_resource.uri = "uri: "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_rules/en-us/mix.tts
request.input.resources.extend([synthesis_resource])
A user ruleset is a set of match-and-replace rules that replace sections of input text during voice synthesis. For example, a ruleset may expand an abbreviation (from "PIN" to "personal information number"), or convert currency symbols into full words.
Whereas user dictionaries only support search and replace for complete words or phrases, user rulesets support any search pattern that can be expressed using regular expressions. You can use rulesets to search for multiple words, part of a word, or a repeated pattern. For example, you can use an expression to find all uses of a currency symbol, and replace it with words ("dollars" or "euros") regardless of the amounts.
Rulesets are created following the instructions in "Rulesets" in the Nuance Vocalizer for Enterprise documentation. Only text rulesets are allowed, binary (or encrypted) rulesets are not supported.
To include rulesets in your applications:
Define the ruleset as a text file.
Upload the ruleset to storage using UploadRequest. See Sample storage client - Upload rulesets.
UploadResponse returns the complete URN for the ruleset in the response.
Load the ruleset into a synthesis session with its URN using SynthesisRequest - Input - SynthesisResource - TEXT_USER_RULESET. See Sample synthesis client - Run client with resources.
To remove a resource from storage, use DeleteRequest. See Sample storage client - Delete resource.
Audio file
Audio file in cloud storage via URN
<speak>Please leave your name after the tone.
<audio src="urn:nuance-mix:tag:tuning:audio/coffee_app/beep/mix.tts">Beep</audio>
</speak>
Audio file via secure URL
<speak>Please leave your name after the tone.
<audio src="https://mtl-host42.nuance.co.uk/audio/beep.wav">Beep</audio>
</speak>
An audio file may be included in SSML input or tokenized sequences to provide speech or sounds during synthesis.
You may include audio files using the SSML <audio> element or the audio control code.
You may optionally include alternative text in the SSML audio element as <audio src="file.wav">Alt text</audio>.If the file is not found or is not a WAV file, NVC synthesizes the alternative text and includes it in the results.
Tokenized sequences do not support alternative text for the audio file. With the Synthesize method, if the audio file is not found or is not WAV, NVC reports an error but synthesizes any text tokens in the sequence, ignoring the audio file. For UnarySynthesize, NVC does not synthesize the text tokens and returns no synthesis.
If there is no alternative text or text token, NVC reports errors for unavailable or non-WAV files.
gRPC APIs
NVC provides several protocol buffer (.proto) files, to define its gRPC protocol. These files contain the building blocks of your voice synthesis applications, and are grouped by function:
After transforming the proto files (if required by your programming language) into functions and classes using gRPC tools, you call these services from your application to request speech synthesis and upload resources.
Synthesizer API
Proto and stub files for Synthesizer service
└── nuance
├── rpc (RPC message files)
└── tts
├── storage (Storage files)
└── v1
├── synthesizer_pb2_grpc.py
├── synthesizer_pb2.py
└── synthesizer.proto
The synthesizer API defines RPC methods for requesting speech synthesis.
A transcoded HTTP version of this Synthesizer API is also available: see Synthesizer HTTP API. The HTTP version uses the UnarySynthesize method, meaning the results are returned in one package instead of being streamed.
Proto file structure
Structure of synthesizer.proto
Synthesizer
Get Voices
GetVoicesRequest
GetVoicesResponse
Synthesize
SynthesisRequest
SynthesisResponse
UnarySynthesize
SynthesisRequest
UnarySynthesisResponseGetVoicesRequest / GetVoicesResponse
voice Voice
age_group EnumAgeGroup
gender EnumGender
voice fieldsSynthesisRequest
voice Voice
voice fields
audio_params AudioParameters
audio parm fields
audio_format AudioFormat
audio format fields
ogg_opus OggOpus | opus Opus
Opus fields
vbr EnumVariableBitrate
input Input
text Text
ssml SSML
ssml_validation_mode EnumSSMLValidationMode
tokenized_sequence TokenizedSequence
resources SynthesisResource
resource fields
type EnumResourceType
lid_params LanguageIdentificationParameters
download_params DownloadParameters
event_params EventParameters
event parm fields
client_data
user_idSynthesisResponse
status Status
events Events
Event
audioUnarySynthesisResponse
status Status
events Events
Event
audio
The proto file defines a Synthesizer service with three RPC methods: GetVoices, Synthesize, and UnarySynthesize. Details about each component are referenced by name within the proto file.
These are the fields that make up the GetVoices request and response:
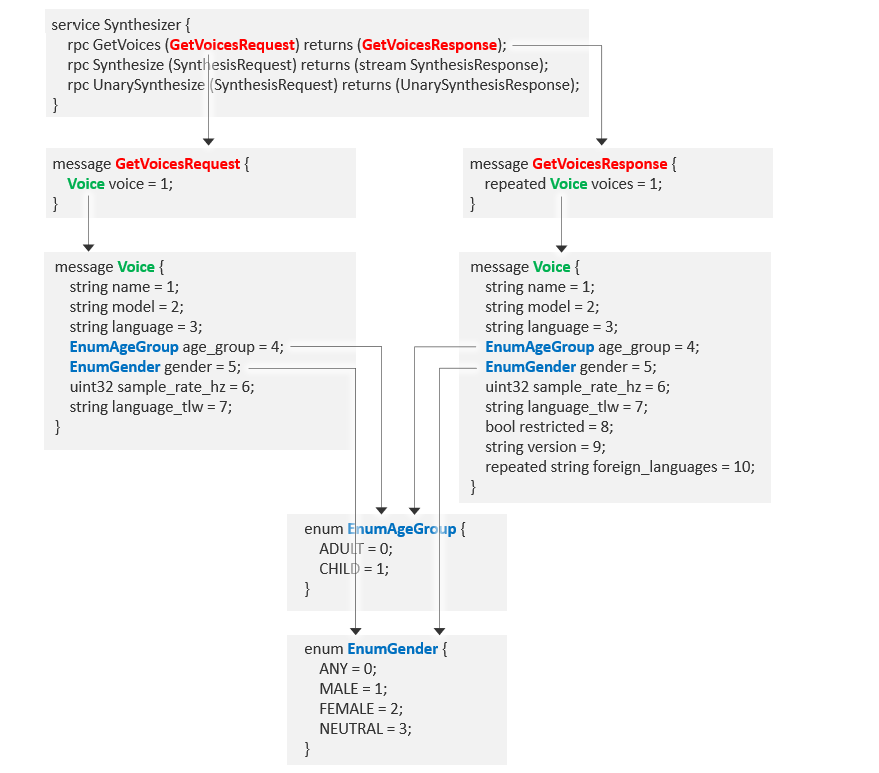
And these are the principal fields in the Synthesize and UnarySynthesize request and response:

Synthesizer
The Synthesizer service offers these functionalities:
- GetVoices: Queries the list of available voices, with filters to reduce the search space.
- Synthesize: Synthesizes audio from input text and parameters, and returns an audio stream.
- UnarySynthesize: Synthesizes audio from input text and parameters, and returns a single audio response.
| Method | Request Type | Response Type |
|---|---|---|
| GetVoices | GetVoicesRequest | GetVoicesResponse |
| Synthesize | SynthesisRequest | SynthesisResponse stream |
| UnarySynthesize | SynthesisRequest | UnarySynthesisResponse |
GetVoicesRequest
Get all American English voices
GetVoicesRequest (
voice = Voice (
language = "en-us"
)
)
Get one named voice
GetVoicesRequest (
voice = Voice (
name = "Evan"
)
)
Input message for message for Synthesizer - GetVoices, to query voices available to the client.
| Field | Type | Description |
|---|---|---|
| voice | Voice | Optionally filter the voices to retrieve, e.g. set language to en-US to return only American English voices. |
Voice
Input or output message for voices.
- In GetVoicesRequest, it filters the list of available voices.
- In SynthesisRequest, it specifies the voice to use for synthesis.
- In GetVoicesResponse, it returns the list of available voices.
These fields are supported in all cases:
| Field | Type | Description |
|---|---|---|
| name | string | The voice's name, e.g. Evan. Mandatory for SynthesisRequest. |
| model | string | The voice's quality model, e.g. enhanced or standard. Mandatory for SynthesisRequest. |
These Voice fields are used only in GetVoicesRequest and GetVoicesResponse. They are ignored in SynthesisRequest.
| Field | Type | Description |
|---|---|---|
| language | string | IETF language code, e.g. en-US. Search for voices with a specific language. Some voices support multiple languages. |
| age_group | EnumAgeGroup | Search for adult or child voices. |
| gender | EnumGender | Search for voices with a certain gender. |
| sample_rate_hz | uint32 | Search for a certain native sample rate. |
| language_tlw | string | Three-letter language code (e.g. enu for American English) for configuring language identification in Input. |
| restricted | bool | Used only in GetVoicesResponse, to identify restricted voices (restricted true). These are custom voices available only to specific customers. Default is false, meaning the voice is public. |
| version | string | Used only in GetVoicesResponse, to return the voice's version. |
| foreign_languages | string | Repeated. Used only in GetVoicesResponse, to return the foreign languages of a multilingual voice. |
EnumAgeGroup
Input field for GetVoicesRequest or output field for GetVoicesResponse, specifying whether the voice uses its adult or child version, if available. Included in Voice.
| Name | Number | Description |
|---|---|---|
| ADULT | 0 | Adult voice. Default for GetVoicesRequest. |
| CHILD | 1 | Child voice. |
EnumGender
Input field for GetVoicesRequest or output field for GetVoicesResponse, specifying gender for voices that support multiple genders. Included in Voice.
| Name | Number | Description |
|---|---|---|
| ANY | 0 | Any gender voice. Default for GetVoicesRequest. |
| MALE | 1 | Male voice. |
| FEMALE | 2 | Female voice. |
| NEUTRAL | 3 | Neutral gender voice. |
GetVoicesResponse
Response to GetVoicesRequest for all American English (en-us) voices
2021-07-14 10:14:42,290 (140157303519040) DEBUG [voice { language: "en-us" } ]
2021-07-14 10:14:42,291 (140157303519040) INFO Sending GetVoices request
2021-07-14 10:14:42,480 (140157303519040) INFO voices {
name: "Allison"
model: "standard"
language: "en-us"
gender: FEMALE
sample_rate_hz: 22050
language_tlw: "enu"
version: "5.2.3.12283"
}
voices {
name: "Allison"
model: "standard"
language: "en-us"
gender: FEMALE
sample_rate_hz: 8000
language_tlw: "enu"
version: "5.2.3.12283"
}
voices {
name: "Ava-Ml"
model: "enhanced"
language: "en-us"
gender: FEMALE
sample_rate_hz: 22050
language_tlw: "enu"
version: "3.0.1"
foreign_languages: "es-mx"
}
voices {
name: "Chloe"
model: "standard"
language: "en-us"
gender: FEMALE
sample_rate_hz: 22050
language_tlw: "enu"
version: "5.2.3.15315"
}
voices {
name: "Chloe"
model: "standard"
language: "en-us"
gender: FEMALE
sample_rate_hz: 8000
language_tlw: "enu"
version: "5.2.3.15315"
}
voices {
name: "Erica"
model: "standard"
language: "en-us"
gender: FEMALE
sample_rate_hz: 22050
language_tlw: "enu"
restricted: true
version: "1.0.2"
}
voices {
name: "Erica"
model: "standard"
language: "en-us"
gender: FEMALE
sample_rate_hz: 8000
language_tlw: "enu"
restricted: true
version: "1.0.2"
}
voices {
name: "Evan"
model: "enhanced"
language: "en-us"
gender: MALE
sample_rate_hz: 22050
language_tlw: "enu"
version: "1.1.1"
}
. . .
voices {
name: "Zoe-Ml"
model: "enhanced"
language: "en-us"
gender: FEMALE
sample_rate_hz: 22050
language_tlw: "enu"
version: "1.0.2"
foreign_languages: "es-mx"
foreign_languages: "fr-ca"
}
Output message for Synthesizer - GetVoices. Includes a list of voices that matched the input criteria, if any.
| Field | Type | Description |
|---|---|---|
| voices | Voice | Repeated. Voices and characteristics returned. |
SynthesisRequest
Synthesis request with most fields
SynthesisRequest(
voice = Voice(
name = "Evan",
model = "enhanced"
),
audio_params = AudioParameters(
audio_format = AudioFormat(
pcm = PCM(sample_rate_hz = 22050)
),
volume_percentage = 80, # Default value
speaking_rate_factor = 1.0 # Default value
),
input = Input(
text = Text(
text = "Your coffee will be ready in 5 minutes")
),
event_params = EventParameters(
send_log_events = True,
suppress_input = True
),
client_data = {'company':'Aardvark Coffee','user':'Leslie'},
user_id = "leslie.somebody@aardvark.com"
)
Minimal synthesis request, using all defaults
SynthesisRequest(
voice = Voice(
name = "Evan",
model = "enhanced"
),
input = Input(
text = Text(
text = "Your coffee will be ready in 5 minutes")
)
)
Input message for Synthesizer - Synthesize. Specifies input text, audio parameters, and events to subscribe to, in exchange for synthesized audio. See Defaults for default values for optional fields.
| Field | Type | Description |
|---|---|---|
| voice | Voice | Mandatory. The voice to use for audio synthesis. |
| audio_params | AudioParameters | Output audio parameters, such as encoding and volume. Default is PCM audio at 22050 Hz. |
| input | Input | Mandatory. Input text to synthesize, tuning data, etc. |
| event_params | EventParameters | Markers and other info to include in server events returned during synthesis. |
| client_data | map<string,string> | Map of client-supplied key:value pairs to inject into the call log. |
| user_id | string | Identifies a specific user within the application. |
AudioParameters
Input message for audio-related parameters during synthesis, including encoding, volume, and audio length. Included in SynthesisRequest.
| Field | Type | Description |
|---|---|---|
| audio_format | AudioFormat | Audio encoding. Default PCM 22050 Hz. |
| volume_percentage | uint32 | Volume amplitude, from 0 to 100. Default 80. |
| speaking_rate_factor | float | Speaking rate, from 0 to 2.0. Default 1.0. |
| audio_chunk_ duration_ms | uint32 | Maximum duration, in ms, of an audio chunk delivered to the client, from 1 to 60000. Default is 20000 (20 seconds). When this parameter is large enough (for example, 20 or 30 seconds), each audio chunk contains an audible segment surrounded by silence. |
| target_audio_length_ms | uint32 | Maximum duration, in ms, of synthesized audio. When greater than 0, the server stops ongoing synthesis at the first sentence end, or silence, closest to the value. |
| disable_early_emission | bool | By default, audio segments are emitted as soon as possible, even if they are not audible. This behavior may be disabled. |
AudioFormat
PCM audio format shown, with alternatives in commented lines
SynthesisRequest(
voice = Voice(
name = "Evan",
model = "enhanced"
),
audio_params = AudioParameters(
audio_format = AudioFormat(
pcm = PCM(sample_rate_hz = 22050)
# alaw = ALaw()
# ulaw = ULaw()
# ogg_opus = OggOpus(sample_rate_hz = 16000)
# opus = Opus(sample_rate_hz = 8000, bit_rate_bps = 30000)
)
)
Input message for audio encoding of synthesized text. Included in AudioParameters.
| Field | Type | Description |
|---|---|---|
| pcm | PCM | Signed 16-bit little endian PCM. |
| alaw | ALaw | G.711 A-law, 8kHz. |
| ulaw | ULaw | G.711 Mu-law, 8kHz. |
| ogg_opus | OggOpus | Ogg Opus, 8kHz,16kHz, or 24 kHz. |
| opus | Opus | Opus, 8kHz, 16kHz, or 24kHz. The audio will be sent one Opus packet at a time. |
PCM
Input message defining PCM sample rate. Included in AudioFormat.
| Field | Type | Description |
|---|---|---|
| sample_rate_hz | uint32 | Output sample rate in Hz. Supported values: 8000, 11025, 16000, 22050, 24000. |
ALaw
Input message defining A-law audio format. Included in AudioFormat. G.711 audio formats are set to 8kHz.
ULaw
Input message defining Mu-law audio format. Included in AudioFormat. G.711 audio formats are set to 8kHz.
OggOpus
Input message defining Ogg Opus output rate. Included in AudioFormat.
| Field | Type | Description |
|---|---|---|
| sample_rate_hz | uint32 | Output sample rate in Hz. Supported values: 8000, 16000, 24000. |
| bit_rate_bps | uint32 | Valid range is 500 to 256000 bps. Default 28000. |
| max_frame_ duration_ms | float | Opus frame size in ms: 2.5, 5, 10, 20, 40, 60. Default 20. |
| complexity | uint32 | Computational complexity. A complexity of 0 means the codec default. |
| vbr | EnumVariableBitrate | Variable bitrate. On by default. |
Opus
Input message defining Opus output rate. Included in AudioFormat.
| Field | Type | Description |
|---|---|---|
| sample_rate_hz | uint32 | Output sample rate in Hz. Supported values: 8000, 16000, 24000. |
| bit_rate_bps | uint32 | Valid range is 500 to 256000 bps. Default 28000. |
| max_frame_ duration_ms | float | Opus frame size in ms: 2.5, 5, 10, 20, 40, 60. Default 20. |
| complexity | uint32 | Computational complexity. A complexity of 0 means the codec default. |
| vbr | EnumVariableBitrate | Variable bitrate. On by default. |
EnumVariableBitrate
Settings for variable bitrate. Included in OggOpus and Opus. Turned on by default.
| Name | Number | Description |
|---|---|---|
| VARIABLE_BITRATE_ON | 0 | Use variable bitrate. Default. |
| VARIABLE_BITRATE_OFF | 1 | Do not use variable bitrate. |
| VARIABLE_BITRATE_ CONSTRAINED | 2 | Use constrained variable bitrate. |
Input
Input message containing text to synthesize and synthesis parameters, including tuning data, etc. Included in SynthesisRequest. The type of input may be plain text, SSML, or a sequence of plain text and Nuance control codes. See Input to synthesize for more examples.
| Field | Type | Description |
|---|---|---|
| text | Text | Plain text input. |
| ssml | SSML | SSML input, including text and SSML elements. |
| tokenized_sequence | TokenizedSequence | Sequence of text and Nuance control codes. |
| resources | SynthesisResource | Repeated. Synthesis resources (user dictionaries, rulesets, etc.) to tune synthesized audio. Default blank. |
| lid_params | LanguageIdentification Parameters | LID parameters. |
| download_params | DownloadParameters | Remote file download parameters. |
Text
Plain text input
SynthesisRequest(
voice = Voice(
name = "Evan",
model = "enhanced"
),
input = Input(
text = Text(
text = "Your coffee will be ready in 5 minutes")
),
)
Input message for synthesizing plain text. The encoding must be UTF-8.
| Field | Type | Description |
|---|---|---|
| text | string | Plain input text in UTF-8 encoding. |
| uri | string | Remote URI to the plain input text. Not supported in Nuance-hosted NVC. |
SSML
SSML input
SynthesisRequest(
voice = Voice(
name = "Evan",
model = "enhanced"
),
input = Input(
ssml = SSML(
text = '<?xml version="1.0"?><speak xmlns="http://www.w3.org/2001/10/synthesis"
xml:lang="en-US" version="1.0">This is the normal volume of my voice.
<prosody volume="10">I can speak rather quietly, </prosody>
<prosody volume="90">But also very loudly.</prosody></speak>',
ssml_validation_mode = WARN
)
)
)
The xml tag and the speak attributes may be omitted
SynthesisRequest(
voice = Voice(
name = "Evan",
model = "enhanced"
),
input = Input(
ssml = SSML(
text = '<speak>This is the normal volume of my voice.
<prosody volume="10">I can speak rather quietly,</prosody>
<prosody volume="90">But also very loudly.</prosody></speak>',
ssml_validation_mode = WARN
)
)
)
Input message for synthesizing SSML input. See SSML tags for a list of supported elements and examples.
| Field | Type | Description |
|---|---|---|
| text | string | SSML input text and elements. |
| uri | string | Remote URI to the SSML input text. Not supported in Nuance-hosted NVC. |
| ssml_validation_mode | EnumSSML ValidationMode | SSML validation mode. Default STRICT. |
EnumSSMLValidationMode
SSML validation mode when using SSML input. Included in SSML. Strict by default but can be relaxed.
| Name | Number | Description |
|---|---|---|
| STRICT | 0 | Strict SSL validation. Default. |
| WARN | 1 | Give warning only. |
| NONE | 2 | Do not validate. |
TokenizedSequence
Tokenized sequence
SynthesisRequest(
voice = Voice(
name = "Evan",
model = "enhanced"
),
input = Input(
tokenized_sequence = TokenizedSequence(
tokens = [
Token(control_code = ControlCode(
key = "vol",
value = "10")),
Token(text = "I can speak rather quietly,"),
Token(control_code = ControlCode(
key = "vol",
value = "90")),
Token(text = "but also very loudly.")
]
)
)
)
Input message for synthesizing a sequence of plain text and Nuance control codes.
| Field | Type | Description |
|---|---|---|
| tokens | Token | Repeated. Sequence of text and control codes. |
Token
The unit when using TokenizedSequence for input. Each token can be either plain text or a Nuance control code. See Control codes for a list of supported codes and examples.
| Field | Type | Description |
|---|---|---|
| text | string | Plain input text. |
| control_code | ControlCode | Nuance control code. |
ControlCode
Nuance control code that specifies how text should be spoken, similarly to SSML.
| Field | Type | Description |
|---|---|---|
| key | string | Name of the control code, e.g. pause |
| value | string | Value of the control code. |
SynthesisResource
Inline compiled user dictionary (with body)
SynthesisRequest (
voice = Voice (name = "Evan", model = "enhanced"),
input = Input (
text = Text (text = "Your coffee will be ready in 5 minutes"),
resources = [
SynthesisResource (
type = USER_DICTIONARY,
body = open("/path/to/user_dictionary.dcb", 'rb').read()
)
]
)
)
External user dictionary
SynthesisRequest (
voice = Voice (name = "Evan", model = "enhanced"),
input = Input (
text = Text (text = "Your coffee will be ready in 5 minutes"),
resources = [
SynthesisResource (
type = USER_DICTIONARY,
uri = "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_dict/en-us/mix.tts"
)
]
)
)
ActivePrompt database
SynthesisRequest (
voice = Voice (name = "Evan", model = "enhanced"),
input = Input (
text = Text (text = "Your coffee will be ready in 5 minutes"),
resources = [
SynthesisResource (
type = ACTIVEPROMPT_DB,
uri = "urn:nuance-mix:tag:tuning:voice/coffee_app/coffee_prompts/Evan/mix.tts"
)
]
)
)
User ruleset
SynthesisRequest (
voice = Voice (name = "Evan", model = "enhanced"),
input = Input (
text = Text (text = "Your coffee will be ready in 5 minutes"),
resources = [
SynthesisResource (
type = TEXT_USER_RULESET,
uri = "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_rules/en-us/mix.tts"
)
]
)
)
Input message specifying the type of file to tune the synthesized output and its location or contents. Included in Input. See Synthesis resources.
| Field | Type | Description |
|---|---|---|
| type | EnumResourceType | Resource type, e.g. user dictionary, etc. Default USER_DICTIONARY. |
| uri | string | The URN of a resource previously uploaded to cloud storage with the storage API. See URNs for the format. |
| body | bytes | For EnumResourceType USER_DICTIONARY, the contents of the file. See Reference topics - Inline dictionary for an example. |
EnumResourceType
The type of synthesis resource to tune the output. Included in SynthesisResource. User dictionaries provide custom pronunciations, rulesets apply search-and-replace rules to input text, and ActivePrompt databases help tune synthesized audio under certain conditions, using Nuance Vocalizer Studio.
| Name | Number | Description |
|---|---|---|
| USER_DICTIONARY | 0 | User dictionary (application/edct-bin-dictionary). Default. |
| TEXT_USER_RULESET | 1 | Text user ruleset (application/x-vocalizer-rettt+text). |
| BINARY_USER_RULESET | 2 | Not supported. Binary user ruleset (application/x-vocalizer-rettt+bin). |
| ACTIVEPROMPT_DB | 3 | ActivePrompt database (application/x-vocalizer-activeprompt-db). |
| ACTIVEPROMPT_DB_AUTO | 4 | ActivePrompt database with automatic insertion (application/x-vocalizer-activeprompt-db;mode=automatic). This keyword specifies any ActivePrompt database but changes the behavior. |
| SYSTEM_DICTIONARY | 5 | Nuance system dictionary (application/sdct-bin-dictionary). Not supported. |
URNs
Examples of URNs
User dictionary:
urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_dict/en-us/mix.tts
Text ruleset:
urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_rules/en-us/mix.tts
ActivePrompt database:
urn:nuance-mix:tag:tuning:voice/coffee_app/coffee_prompts/Evan/mix.tts
Audio file:
urn:nuance-mix:tag:tuning:audio/coffee_app/thanks/mix.tts
The uri field in SynthesisResource defines the location of a synthesis resource as a URN in the Mix cloud storage area. In Reference topics - SSML tags and Control codes, the audio tag or code defines a wav file as a URN. The format depends on the object type:
User dictionaries and text rulesets:
urn:nuance-mix:tag:tuning:lang/context_tag/name/language/mix.ttsActivePrompt databases:
urn:nuance-mix:tag:tuning:voice/context_tag/name/voice/mix.ttsAudio files:
urn:nuance-mix:tag:tuning:audio/context_tag/name/mix.tts
When you upload these resources using the Storage API, you provide only the context tag and name in UploadRequest - UploadInitMessage. The UploadResponse message confirms the complete URN for the object.
The URN returned by UploadResponse includes an additional type field that identifies the type of resource, for example:
uri: "urn:nuance-mix:tag:tuning:lang/coffee_app/coffee_dict/en-us/mix.tts?type=userdict"
This type field is purely informational. It is not required when using the URN in a SynthesisRequest, although it may be included without error.
| Syntax | |
|---|---|
urn:nuance-mix:tag:tuning |
The prefix for all synthesis resources. |
lang and language |
The scope keyword, lang, for dictionaries and rulesets, plus the language in the format xx-xx. |
voice and voice |
The scope keyword, voice, for ActivePrompt databases, plus the voice name. |
audio |
The scope keyword, audio, for audio files. |
context_tag |
A name for the collection of objects being stored. This can be a Context Tag from a Mix project or another collective name. If the context tag does not exist, it will be created. |
name |
An identifier for the content being uploaded, using 1 to 64 alphanumeric characters or underscore (a-z, A-Z, 0-9, _). |
mix.tts |
The suffix for all synthesis resources. |
?type=resource_type |
An informational field returned by UploadRequest that identifies the type of resource. This field is not required when using the URN in a Synthesis request, although it may be included without error. |
LanguageIdentificationParameters
LID parameters in Input message
SynthesisRequest(
voice = Voice(
name = "Evan",
model = "enhanced"
),
input = Input(
tokenized_sequence = TokenizedSequence(
tokens = [
Token(text = "The name of the song is. "),
Token(control_code = ControlCode(
key = "lang",
value = "unknown")),
Token(text = "Au clair de la lune."),
Token(control_code = ControlCode(
key = "lang",
value = "normal")),
Token(text = "It's a folk song meaning, in the light of the moon.")
]
),
lid_params = LanguageIdentificationParameters(
languages = (["frc", "enu"])
)
)
)
Input message controlling the language identifier. Included in Input. The language identifier runs on input blocks labeled with the control code lang unknown or the SSML attribute xml:lang="unknown". The language identifier automatically restricts the matched languages to the installed voices. This limits the permissible languages, and also sets the order of precedence (first to last) when they have equal confidence scores.
| Field | Type | Description |
|---|---|---|
| disable | bool | Whether to disable language identification. Turned on by default. |
| languages | string | Repeated. List of three-letter language codes (e.g. enu, frc, spm) to restrict language identification results, in order of precedence. Use GetVoicesRequest to obtain the three-letter codes, returned in GetVoicesResponse - language_tlw. Default blank. |
| always_use_ highest_confidence | bool | If enabled, language identification always chooses the language with the highest confidence score, even if the score is low. Default false, meaning use language with any confidence. |
DownloadParameters
Input message containing parameters for remote file download, whether for input text (Input.uri) or a SynthesisResource (SynthesisResource.uri). Included in Input.
| Field | Type | Description |
|---|---|---|
| headers | map<string,string> | Map of HTTP header name,value pairs to include in outgoing requests. Supported headers: max_age, max_stale. |
| request_timeout_ms | uint32 | Request timeout in ms. Default (0) means server default, usually 30000 (30 seconds). |
| refuse_cookies | bool | Whether to disable cookies. By default, HTTP requests accept cookies. |
EventParameters
Event parameters in SynthesisRequest
SynthesisRequest(
voice = Voice(
name = "Evan",
model = "enhanced"
),
input = Input(
text = Text(
text = "Your coffee will be ready in 5 minutes.")
),
event_params = EventParameters(
send_sentence_marker_events = True,
send_paragraph_marker_events = True,
send_log_events = True,
suppress_input = True
)
)
Input message that defines event subscription parameters. Included in SynthesisRequest. Events that are requested are sent throughout the SynthesisResponse stream, when generated. Marker events can send events as certain parts of the synthesized audio are reached, for example, at the end of a word, sentence, or user-defined bookmark.
Log events are produced throughout a synthesis request for events such as a voice loaded by the server or an audio chunk being ready to send.
| Field | Type | Description |
|---|---|---|
| send_sentence_marker_events | bool | Sentence marker. Default: do not send. |
| send_word_marker_events | bool | Word marker. Default: do not send. |
| send_phoneme_marker_events | bool | Phoneme marker. Default: do not send. |
| send_bookmark_marker_events | bool | Bookmark marker. Default: do not send. |
| send_paragraph_marker_events | bool | Paragraph marker. Default: do not send. |
| send_visemes | bool | Lipsync information. Default: do not send. |
| send_log_events | bool | Whether to log events during synthesis. By default, logging is turned off. |
| suppress_input | bool | Whether to omit input text and URIs from log events. By default, these items are included. |
SynthesisResponse
Response to synthesis request
try:
if args.output_audio_file:
audio_file = open(args.output_audio_file, "wb")
for response in stream_in:
if response.HasField("audio"):
print("Received audio: %d bytes" % len(response.audio))
if(audio_file):
audio_file.write(response.audio)
elif response.HasField("events"):
print("Received events")
print(text_format.MessageToString(response.events))
else:
if response.status.code == 200:
print("Received status response: SUCCESS")
else:
print("Received status response: FAILED")
print("Code: {}, Message: {}".format(response.status.code, response.status.message))
print('Error: {}'.format(response.status.details))
except Exception as e:
print(e)
if audio_file:
print("Saved audio to {}".format(args.output_audio_file))
audio_file.close()
The Synthesizer - Synthesize method returns a stream of SynthesisResponse messages. (See UnarySynthesisResponse for a non-streamed response.) Each response contains one of:
- A status response, indicating completion or failure of the request. This is received only once and signifies the end of a Synthesize call.
- A list of events the client has requested. This can be received many times. See EventParameters for details.
- An audio buffer. This may be received many times.
| Field | Type | Description |
|---|---|---|
| status | Status | A status response, indicating completion or failure of the request. |
| events | Events | A list of events. See EventParameters for details. |
| audio | bytes | The latest audio buffer. |
Status
Output message containing a status response, indicating completion or failure of a Synthesize call. Included in SynthesisResponse and UnarySynthesisResponse.
| Field | Type | Description |
|---|---|---|
| code | uint32 | HTTP-style return code: 200, 4xx, or 5xx as appropriate. See Status codes. |
| message | string | Brief description of the status. |
| details | string | Longer description if available. |
Events
Output message defining a container for a list of events. This container is needed because oneof does not allow repeated parameters in Protobuf. Included in SynthesisResponse and UnarySynthesisResponse.
| Field | Type | Description |
|---|---|---|
| events | Event | Repeated. One or more events. |
Event
Output message defining an event message. Included in Events. See EventParameters for details.
| Field | Type | Description |
|---|---|---|
| name | string | Either "Markers" or the name of the event in the case of a Log Event. |
| values | map<string,string> | Map of key:value data relevant to the current event. |
UnarySynthesisResponse
The Synthesizer - UnarySynthesize method returns a single UnarySynthesisResponse message. It is similar to SynthesisResponse but includes all the information at once instead of a streaming response. The response contains:
- A status response, indicating completion or failure of the request.
- A list of events the client has requested. See EventParameters for details.
- The complete audio buffer of the synthesized text.
| Field | Type | Description |
|---|---|---|
| status | Status | A status response, indicating completion or failure of the request. |
| events | Events | A list of events. See EventParameters for details. |
| audio | bytes | Audio buffer of the synthesized text, capped if necessary to a configured audio response size. |
Storage API
Proto and stub files for storage service
└── nuance
├── rpc
│ ├── error_details_pb2.py
│ ├── error_details.proto
│ ├── status_code_pb2.py
│ ├── status_code.proto
│ ├── status_pb2.py
│ └── status.proto
└── tts
├── storage
│ └── v1beta1
│ ├── storage_pb2_grpc.py
│ ├── storage_pb2.py
│ └── storage.proto
└── v1 (Synthesizer files)
The storage API defines RPC methods to upload synthesis resources to a central cloud location managed by MinIO. It assigns the resources URN identifiers starting with urn:nuance-mix, which you may reference in the synthesis API.
Storage
Storage is the upload service API, consisting of two methods: Upload and Delete.
| Method | Request type | Response type | Description |
|---|---|---|---|
| Upload | UploadRequest stream | UploadResponse | Uploads a synthesis resource to cloud storage and returns a URN to refer to it. |
| Delete | DeleteRequest | DeleteResponse | Deletes the synthesis resource in storage. |
These are the general steps for uploading or deleting synthesis resources to cloud storage:
Send an UploadRequest with the content to upload and other parameters. The request is streamed to the service and UploadResponse returns a URN to identify the resource.
To remove content from storage, send DeleteRequest with the URN of the resource to remove. If the resource exists in storage, it is removed, and DeleteResponse returns the status of the delete process.
UploadRequest
Upload request
data = file_handle.read(max_chunk_size_bytes)
if not data:
log.info("Done reading data")
break
upload_request = UploadRequest()
upload_request.data_chunk = data
yield upload_request
Requests to upload (stream) content to central cloud storage, sent one at a time in order. First send upload_init_message then the data to upload. This request returns UploadResponse.
| Field | Type | Description |
|---|---|---|
| One of: | ||
| upload_init_message | UploadInitMessage | Mandatory. First message in the RPC input stream, to define the content that will follow. |
| data_chunk | bytes | Mandatory. Data to upload, in chunks lower than the allowed maximum gRPC message size. If uploading an ActivePrompt, a zipped stream is required. |
UploadInitMessage
Upload init messaage
upload_request = UploadRequest()
upload_init_message = UploadInitMessage()
upload_init_message.context_tag = args.context_tag
upload_init_message.name = args.name
The required first message sent by the client. It defines the type of the content as well as the output URN. There are three types of URNs:
- Language-scoped:
urn:nuance-mix:tag:tuning:lang/context_tag/name/language/mix.tts - Voice-scoped:
urn:nuance-mix:tag:tuning:voice/context_tag/name/voice/mix.tts - Audio-scoped:
urn:nuance-mix:tag:tuning:audio/context_tag/name/mix.tts
| Field | Type | Description |
|---|---|---|
| context_tag | string | Mandatory. Context tag of the current application. A context tag can contain many resources. Will be included in the URN. |
| name | string | Mandatory. Name of the uploaded content. Should be unique within a context tag. Will be included in the URN. |
| metadata | map<string,string> | Map of client-supplied metadata key, value pairs. |
| One of: | Mandatory. Resource type to upload. | |
| active_prompt_db | ActivePromptDB | ActivePrompt database (application/x-vocalizer-activeprompt-db). Voice-scoped. |
| dictionary | UserDictionary | User dictionary (application/edct-bin-dictionary). Language-scoped. |
| text_ruleset | TextUserRuleset | Text user ruleset (application/x-vocalizer-rettt+text). Language-scoped. |
| binary_ruleset | BinaryUserRuleset | Not supported. Binary user ruleset (application/x-vocalizer-rettt+bin). |
| wav | Wav | Wav audio file, for insertion into synthesis via SSML or Nuance control codes. |
ActivePromptDB
Parameters for ActivePrompt databases are collected from the user
options.add_argument("--file", metavar="file", nargs="?",
help="File to upload. If an ActivePrompt Database, must be packaged as a zip.", required=True)
options.add_argument("--context_tag", metavar="tag", nargs="?",
help="Context tag", default='', required=True)
options.add_argument("--name", metavar="name", nargs="?",
help="Resource name", default='', required=True)
options.add_argument("--type", metavar="type", nargs="?",
help="Resource type. Must be one of: [activeprompt,
user_dictionary, text_ruleset]", required=True)
options.add_argument("--voice", metavar="type", nargs="?",
help="ActivePrompt voice", default='')
options.add_argument("--voice_model", metavar="type", nargs="?",
help="ActivePrompt voice model", default='')
options.add_argument("--voice_version", metavar="type", nargs="?",
help="ActivePrompt voice version", default='')
options.add_argument("--vocalizer_studio_version", metavar="type", nargs="?",
help="ActivePrompt Vocalier Studio version", default='')
. . .
upload_request = UploadRequest()
upload_init_message = UploadInitMessage()
upload_init_message.context_tag = args.context_tag
upload_init_message.name = args.name
if type == 'activeprompt':
log.info('Type is ActivePromptDB')
active_prompt_db = ActivePromptDB()
active_prompt_db.voice = voice
active_prompt_db.voice_model = voice_model
active_prompt_db.voice_version = voice_version
active_prompt_db.vocalizer_studio_version = vocalizer_studio_version
upload_init_message.active_prompt_db.CopyFrom(active_prompt_db)
Parameters for uploading an ActivePrompt database. See Reference topics - ActivePrompt database.
An ActivePrompt database is a voice-scoped tuning resource, to control the output audio and dynamically insert recordings during synthesis. These databases must be created through Nuance Vocalizer Studio. When uploading an ActivePrompt database:
- The database file itself must be renamed to index.dat before upload.
- A zip file containing both the .dat file and all recordings is required. The zip file can have a maximum of two directory levels.
- The database and audio must be zipped together without a root folder.
| Field | Type | Description |
|---|---|---|
| voice | string | Mandatory. Voice name. |
| voice_version | string | Mandatory. Voice version. |
| voice_model | string | Mandatory. Voice model. |
| vocalizer_studio_version | string | Mandatory. Vocalizer Studio version used to build the ActivePrompt. |
UserDictionary
Parameters for user dictionaries
options.add_argument("--file", metavar="file", nargs="?",
help="File to upload...", required=True)
options.add_argument("--context_tag", metavar="tag", nargs="?",
help="Context tag", default='', required=True)
options.add_argument("--name", metavar="name", nargs="?",
help="Resource name", default='', required=True)
options.add_argument("--type", metavar="type", nargs="?",
help="Resource type. Must be one of: [activeprompt,
user_dictionary, text_ruleset]", required=True)
options.add_argument("--type", metavar="type", nargs="?",
help="Resource type. Must be one of: [activeprompt,
user_dictionary, text_ruleset]", required=True)
options.add_argument("--language", metavar="type", nargs="?",
help="IETF language code. Required if type is [user_dictionary,
text_ruleset])", default='')
. . .
upload_request = UploadRequest()
upload_init_message = UploadInitMessage()
upload_init_message.context_tag = args.context_tag
upload_init_message.name = args.name
. . .
elif type == "user_dictionary":
log.info('Type is User Dictionary')
user_dictionary = UserDictionary()
user_dictionary.language = language
upload_init_message.dictionary.CopyFrom(user_dictionary)
Parameters for uploading a user dictionary. See Reference topics - User dictionary.
A user dictionary is a language-scoped tuning resource, to control pronunciation and acronym expansion.
| Field | Type | Description |
|---|---|---|
| language | string | Mandatory. IETF language of the dictionary. |
TextUserRuleset
Parameters for text rulesets
options.add_argument("--file", metavar="file", nargs="?",
help="File to upload...", required=True)
options.add_argument("--context_tag", metavar="tag", nargs="?",
help="Context tag", default='', required=True)
options.add_argument("--name", metavar="name", nargs="?",
help="Resource name", default='', required=True)
options.add_argument("--type", metavar="type", nargs="?",
help="Resource type. Must be one of: [activeprompt,
user_dictionary, text_ruleset]", required=True)
options.add_argument("--language", metavar="type", nargs="?",
help="IETF language code. Required if type is [user_dictionary,
text_ruleset])", default='')
. . .
upload_request = UploadRequest()
upload_init_message = UploadInitMessage()
upload_init_message.context_tag = args.context_tag
upload_init_message.name = args.name
. . .
elif type == "text_ruleset":
log.info('Type is Text User Ruleset')
text_ruleset = TextUserRuleset()
text_ruleset.language = language
upload_init_message.text_ruleset.CopyFrom(text_ruleset)
Parameters for uploading a text user ruleset. See Reference topics - Ruleset.
A user ruleset is a language-scoped tuning resource, to apply find+replace and regular expression rules on the input text.
| Field | Type | Description |
|---|---|---|
| language | string | Mandatory. IETF language of the ruleset. |
BinaryUserRuleset
Binary (encrypted) rulesets are not supported.
Wav
Parameter for uploading an audio wave file.
After uploading, an audio wave recording can be inserted into the synthesis using the SSML <audio> tag or the Nuance control code, audio. See SSML tags - audio and Control codes - audio.
UploadResponse
Upload request and response
with create_channel() as channel:
storage_stub = StorageStub(channel)
request_iterator = read_file(file=args.file, context_tag=args.context_tag, name=args.name, type=args.type, voice=args.voice, voice_model=args.voice_model, voice_version=args.voice_version, vocalizer_studio_version=args.vocalizer_studio_version, language=args.language, max_chunk_size_bytes=args.max_chunk_size_bytes)
upload_response = storage_stub.Upload(request_iterator)
log.info(text_format.MessageToString(upload_response))
Response to uploading an ActivePrompt database for a coffee application
$ ./run-ap-storage-client.sh
2021-05-18 11:27:33,610 INFO Type is ActivePromptDB
2021-05-18 11:27:33,928 INFO Done reading data
2021-05-18 11:27:34,427 INFO status {
status_code: OK
}
uri: "urn:nuance-mix:tag:tuning:voice/coffee_app/coffee_prompts/evan/mix.tts?type=activeprompt"
Response to UploadRequest, indicating whether the upload was successful.
| Field | Type | Description |
|---|---|---|
| status | nuance.rpc.Status | Any error response means the data was not stored. If no response at all is received (e.g. due to a communication issue), data may have been stored. Another UploadRequest can be sent to restart; any existing files will be overwritten. |
| uri | string | Output URN, to refer to the content at runtime. This is for informational purposes: the URN format is predictable based on the input parameters in the UploadInitMessage. The URN includes a type field to identify the type of request. This field is not required when using the URN in other requests. |
DeleteRequest
Request to remove an item from storage. This request returns DeleteResponse.
| Field | Type | Description |
|---|---|---|
| uri | string | Mandatory. URN of the uploaded content, using one of these formats: urn:nuance-mix:tag:tuning:lang/context_tag/name/language/mix.ttsurn:nuance-mix:tag:tuning:voice/context_tag/name/voice/mix.ttsurn:nuance-mix:tag:tuning:audio/context_tag/name/mix.tts |
DeleteResponse
Response to DeleteRequest, indicating whether the deletion was successful.
| Field | Type | Description |
|---|---|---|
| status | nuance.rpc.Status | Success means the data is not in the system anymore; either because it was deleted by the request or was never there (idempotency). |
RPC status API
These messages are part of the nuance.rpc package referenced by other Nuance methods. They provide additional information about the requests.

nuance.rpc.Status
This reports an ongoing job, combining job status with request status
2021-04-05 16:41:28,369 INFO : Received response: job_status_update {
job_id: "c21b0be0-964e-11eb-9e4a-5fb8e278d1ad"
status: JOB_STATUS_PROCESSING
}
request_status {
status_code: OK
http_trans_code: 200
}
2021-04-05 16:41:28,896 INFO : new server stream count 2
2021-04-05 16:41:28,896 INFO : Received response: job_status_update {
job_id: "c21b0be0-964e-11eb-9e4a-5fb8e278d1ad"
status: JOB_STATUS_COMPLETE
}
request_status {
status_code: OK
http_trans_code: 200
}
This reports an error in a JSON file
2021-04-05 16:34:55,874 INFO : Received response: request_status {
status_code: BAD_REQUEST
status_sub_code: 7
http_trans_code: 400
status_message {
locale: "en-US"
message: "Invalid wordset content Unexpected token c in JSON at position 5"
message_resource_id: "7"
}
}
This reports an existing object
2021-04-05 17:37:41,977 INFO : Received response: request_status {
status_code: ALREADY_EXISTS
status_sub_code: 10
http_trans_code: 200
status_message {
locale: "en-US"
message: "Compiled wordset already available for artifact reference urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
message_resource_id: "10"
}
}
Status messages for requests used by Nuance APIs. The status_code field is mandatory, all others are optional.
| Field | Type | Description |
|---|---|---|
| status_code | StatusCode | Mandatory. Status code, an enum value. |
| status_sub_code | int32 | Application-specific status sub-code. |
| http_trans_code | int32 | HTTP status code for the transcoder, if applicable. |
| request_info | RequestInfo | Information about the original request. |
| status_message | LocalizedMessage | Message providing the details of this status in a language other than English. |
| help_info | HelpInfo | Help message providing possible user actions. |
| field_violations | FieldViolation | Repeated. Set of request field violations. |
| retry_info | RetryInfo | Retry information. |
| status_details | StatusDetail | Repeated. Detailed status messages. |
nuance.rpc.StatusCode
Status codes related to requests used by Nuance APIs.
| Name | Number | Description |
|---|---|---|
| UNSPECIFIED | 0 | Unspecified status. |
| OK | 1 | Success. |
| BAD_REQUEST | 2 | Invalid message type: the server cannot understand the request. |
| INVALID_REQUEST | 3 | The request has an invalid value, is missing a mandatory field, etc. |
| CANCELLED_CLIENT | 4 | Operation terminated by client. The remote system may have changed. |
| CANCELLED_SERVER | 5 | Operation terminated by server. The remote system may have changed. |
| DEADLINE_EXCEEDED | 6 | The deadline set for the operation has expired. |
| NOT_AUTHORIZED | 7 | The client does not have authorization to perform the operation. |
| PERMISSION_DENIED | 8 | The client does not have authorization to perform the operation on the requested entities. |
| NOT_FOUND | 9 | The requested entity was not found. |
| ALREADY_EXISTS | 10 | Cannot create entity as it already exists. |
| NOT_IMPLEMENTED | 11 | Unsupported operation or parameter, e.g. an unsupported media type. |
| UNKNOWN | 15 | Result does not map to any defined status. Other response values may provide request-specific additional information. |
| The following status codes are less frequently used. | ||
| TOO_LARGE | 51 | A field is too large to be processed due to technical limitations e.g. a large audio or other binary block. For arbitrary limitations (e.g. name must be n characters or less), use INVALID_REQUEST. |
| BUSY | 52 | The server understood the request but could not process it due to lack of resources. Retry the request as is later. |
| OBSOLETE | 53 | A message type in the request is no longer supported. |
| RATE_EXCEEDED | 54 | Similar to BUSY. The client has exceeded the limit of operations per time unit. Retry request as is later. |
| QUOTA_EXCEEDED | 55 | The client has exceeded quotas related to licensing or payment. See your client representative for additional quotas. |
| INTERNAL_ERROR | 56 | An internal system error occurred while processing the request. |
nuance.rpc.RequestInfo
Information about the request that resulted in an error. This message is particularly useful in streaming scenarios where the correlation between the request and response is not so obvious.
| Field | Type | Description |
|---|---|---|
| request_id | string | Identifier of the original request, for example, its OpenTracing id. |
| request_data | string | Relevant free format data from the original request, for troubleshooting. |
| additional_request_data | map<string,string> | Map of key,value pairs of free format data from the request. |
nuance.rpc.LocalizedMessage
A help message in a language other than American English. The default locale is provided by the server, for example the browser's preferred language or a user-specific locale.
All Nuance gRPC APIs that want the server to provide localized errors must accept the HTTP "Accept-Language" header or application-specific language settings, if supported.
| Field | Type | Description |
|---|---|---|
| locale | string | The locale as xx-XX, e.g. en-US, fr-CH, es-MX, per the specification bcp47.txt Default is provided by the server. |
| message | string | The message text in the local specified. |
| message_resource_id | string | A message identifier, allowing related messages to be provided if needed. |
nuance.rpc.HelpInfo
A reference to a help document that may be shown to end users to allow them to take action based on the error or status response. For example, if the request contained a numerical value that is out of range, this message may point to the documentation that states the valid range.
| Field | Type | Description |
|---|---|---|
| links | Hyperlink | Repeated. Set of hypertext links related to the context of the enclosing message. |
nuance.rpc.Hyperlink
Details about the hypertext link containing information related to the message.
| Field | Type | Description |
|---|---|---|
| description | LocalizedMessage | A description of the link in a specific language (locale). By default, the server handling the URL manages language selection and detection. |
| url | string | The URL to offer to the client, containing help information. If a description is present, this URL should use (or offer) the same locale. |
nuance.rpc.FieldViolation
Information about a request field or fields containing errors.
| Field | Type | Description |
|---|---|---|
| field | string | The name of the request field in violation as package.type[.type].field. |
| rel_field | string | Repeated. Repeated. The names of related fields in violation as package.type[.type].field. |
| user_message | LocalizedMessage | An error message in a language other than English. |
| message | string | An error message in American English. |
| invalid_value | string | The invalid value of the field in violation. (Convert non-string data types to string.) |
| violation | ViolationType | The reason (enum) a field is invalid. Can be used for automated error handling by the client. |
nuance.rpc.ViolationType
The error type of the request field, as a keyword.
| Name | Number | Description |
|---|---|---|
| MANDATORY_FIELD_MISSING | 0 | A required field was not provided. |
| FIELD_CONFLICT | 1 | A field is invalid due to the value of another field. |
| OUT_OF_RANGE | 2 | A field value is outside the specified range. |
| INVALID_FORMAT | 3 | A field value is not in the correct format. |
| TOO_SHORT | 4 | A text field value is too short. |
| TOO_LONG | 5 | A text field value is too long. |
| OTHER | 64 | Violation type is not otherwise listed. |
| UNSPECIFIED | 99 | Violation type was not set. |
nuance.rpc.RetryInfo
How quickly clients may retry the request for requests that allow retries. Failure to respect this delay may indicate a misbehaving client.
| Field | Type | Description |
|---|---|---|
| retry_delay_ms | int32 | Clients must wait at least this long between retrying the same request. |
nuance.rpc.StatusDetail
A status message may have additional details, usually a list of underlying causes of an error. In contrast to field violations, which point to the fields in the original request, status details are not usually directly connected with the request parameters.
| Field | Type | Description |
|---|---|---|
| message | string | The message text in American English. |
| user_message | LocalizedMessage | The message text in a language other than English. |
| extras | map<string,string> | Map of key,value pairs of additional application-specific information. |
Scalar value types
The data types in the proto files are mapped to equivalent types in the generated client stub files.
Synthesizer HTTP API
NVC includes an HTTP API for requesting voices and synthesis operations. It is based on the Synthesizer gRPC API and offers two commands: voices and synthesis.
This API is a transcoded version of the main gRPC API, so it respects the JSON mapping detailed here.
Base URL and authorization
Shell script, get-token.sh, generates and exports token
CLIENT_ID=<Mix client ID>
SECRET=<Mix client secret>
CLIENT_ID=${CLIENT_ID//:/%3A}
export MY_TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" \
https://auth.crt.nuance.co.uk/oauth2/token \
-d "grant_type=client_credentials" -d "scope=tts" \
| jq -j .access_token`"
The URL for NVC HTTP commands in the Mix environment is:
https://tts.api.nuance.co.uk/api/v1/
This service requires an authorization token. To generate the token, you can use the shell script, get-token.sh, shown at the right, replacing the CLIENT_ID and SECRET values with your credentials from Mix. See Prerequisites from Mix. (The script changes the colons in your client ID to their percent-encoded form, so you may enter your client ID as is.) The OAuth scope for the NVC service, tts, is provided in the shell script.
"Source" this script to generate an authorization token and make it available in the current shell. Then test the URL with a simple voices request using cURL:
$ source get-token.sh
$ curl -H "Authorization: Bearer $MY_TOKEN" \
https://tts.api.nuance.co.uk/api/v1/voices \
-d '{ "voice": { "name": "Evan" } }'
{
"voices": [
{
"name": "Evan",
"model": "enhanced",
"language": "en-us",
"ageGroup": "ADULT",
"gender": "MALE",
"sampleRateHz": 22050,
"languageTlw": "enu",
"restricted": false,
"version": "1.1.1",
"foreignLanguages": []
}
]
}
You must provide the token when calling the service. For example:
- In a cURL command:
$ curl -H "Authorization: Bearer $MY_TOKEN" https://tts.api.nuance.co.uk/api/v1/voices
- In a REST client, you may either generate a token manually and enter it in your request, or have your development environment generate it for you.
Authorization: Bearer <token>
- In a Python client:
http_headers['Authorization'] = "Bearer {}".format(token)
Your authorization token expires after a short period of time. Source get-token.sh again when you get a 401 error, meaning status Unauthorized: The request could not be authorized.
/api/v1/voices
Get all available voices (cURL example)
$ curl -H "Authorization: Bearer $MY_TOKEN" https://tts.api.nuance.co.uk/api/v1/voices
{
"voices": [
{
"name": "Allison",
"model": "standard",
"language": "en-us",
"ageGroup": "ADULT",
"gender": "FEMALE",
"sampleRateHz": 22050,
"languageTlw": "enu",
"restricted": false,
"version": "5.2.3.12283",
"foreignLanguages": []
},
{
"name": "Allison",
"model": "standard",
"language": "en-us",
"ageGroup": "ADULT",
"gender": "FEMALE",
"sampleRateHz": 8000,
"languageTlw": "enu",
"restricted": false,
"version": "5.2.3.12283",
"foreignLanguages": []
},
{
"name": "Ava-Ml",
"model": "enhanced",
"language": "en-us",
"ageGroup": "ADULT",
"gender": "FEMALE",
"sampleRateHz": 22050,
"languageTlw": "enu",
"restricted": false,
"version": "3.0.1",
"foreignLanguages": [
"es-mx"
]
},
{
"name": "Chloe",
"model": "standard",
"language": "en-us",
"ageGroup": "ADULT",
"gender": "FEMALE",
"sampleRateHz": 22050,
"languageTlw": "enu",
"restricted": false,
"version": "5.2.3.15315",
"foreignLanguages": []
},
. . .
GET https://tts.api.nuance.co.uk/api/v1/voices
Queries the voice packs to learn which voices are available. Optionally include parameters to filter the results.
The parameters for the voices command are:
| Name | In | Type | Description |
|---|---|---|---|
| Authorization | header | object | Mandatory. Authorization token as Bearer: token |
| voice | body | voice | Optional. Filter the voices to retrieve, e.g. set language to en-US to return only American English voices. |
A successful response details the available voices, filtered when requested. See Status codes for other responses.
voice (in voices)
Filter results to retrieve voice name Evan
$ curl -H "Authorization: Bearer $MY_TOKEN" \
https://tts.api.nuance.co.uk/api/v1/voices -d '{ "voice": { "name": "evan" } }'
{
"voices": [
{
"name": "Evan",
"model": "enhanced",
"language": "en-us",
"ageGroup": "ADULT",
"gender": "MALE",
"sampleRateHz": 22050,
"languageTlw": "enu",
"restricted": false,
"version": "1.1.1",
"foreignLanguages": []
}
]
}
Filter results to retrieve all French Canadian voices
$ curl -H "Authorization: Bearer $MY_TOKEN" \
https://tts.api.nuance.co.uk/api/v1/voices -d '{ "voice": { "language": "fr-ca" } }'
{
"voices": [
{
"name": "Amelie-Ml",
"model": "enhanced",
"language": "fr-ca",
"ageGroup": "ADULT",
"gender": "FEMALE",
"sampleRateHz": 22050,
"languageTlw": "frc",
"restricted": false,
"version": "2.1.1",
"foreignLanguages": [
"en-us",
"en-gb",
"es-mx"
]
},
{
"name": "Chantal",
"model": "standard",
"language": "fr-ca",
"ageGroup": "ADULT",
"gender": "FEMALE",
"sampleRateHz": 22050,
"languageTlw": "frc",
"restricted": false,
"version": "2.1.0",
"foreignLanguages": []
},
{
"name": "Nicolas",
"model": "standard",
"language": "fr-ca",
"ageGroup": "ADULT",
"gender": "MALE",
"sampleRateHz": 22050,
"languageTlw": "frc",
"restricted": false,
"version": "2.0.0",
"foreignLanguages": []
}
]
}
Filters the requested voices in the voices command. It contains one of the following:
| Name | Type | Description |
|---|---|---|
| name | string | The voice's name, e.g. Evan. |
| model | string | The voice's quality model, e.g. enhanced or standard. (For backward compatibility, xpremium-high or xpremium are also accepted.) |
| language | string | IETF language code, e.g. en-US. Search for voices with a specific language. Some voices support multiple languages. |
| age_group | string | Search for adult or child voices, using a keyword: ADULT (default) or CHILD. |
| gender | string | Search for voices with a certain gender, using a keyword: ANY (default), MALE, FEMALE, NEUTRAL. |
| sample_rate_hz | integer | Search for a certain native sample rate. |
| language_tlw | string | Three-letter language code (e.g. enu for American English) for configuring language identification. |
/api/v1/synthesize
Synthesize plain text (cURL example)
$ curl -H "Authorization: Bearer $MY_TOKEN" \
https://tts.api.nuance.co.uk/api/v1/synthesize \
-d '{ "voice": { "name": "Evan", "model": "enhanced" }, \
"input": { "text": { "text": "This is a test. A very simple test."} } }'
For results, see Response to synthesize below.
POST https://tts.api.nuance.co.uk/api/v1/synthesize
Sends a synthesis request and returns a (unary) synthesis response. The request specifies a mandatory voice and input text, as well as optional audio parameters and so on.
The parameters for the synthesize command are:
| Name | In | Type | Description |
|---|---|---|---|
| Authorization | header | object | Mandatory. Authorization token as Bearer: token |
| voice | body | voice | Mandatory. The voice to perform the synthesis. |
| audio_params | body | audio_params | Output audio parameters, such as encoding and volume. Default is PCM audio at 22050 Hz. |
| input | body | input | Mandatory. Input text to synthesize, tuning data, etc. |
| event_params | body | event_params | Markers and other info to include in server events returned during synthesis. |
| client_data | body | map |
Map of client-supplied key:value pairs to inject into the call log. |
| user_id | body | string | Identifies a specific user within the application. |
For examples of the results, see Response to synthesize below.
voice (in synthesize)
Mandatory voice parameters identify the voice to perform the synthesis
{
"voice":{
"name":"Evan",
"model":"enhanced"
},
"input":{
"text":{
"text":"This is a test. A very simple test."
}
}
}
In the synthesize command, this mandatory parameter specifies the voice to use for the synthesis operation. The other entries in the voice parameter are not used for synthesis.
| Name | Type | Description |
|---|---|---|
| name | string | Mandatory. The voice's name, e.g. Evan. |
| model | string | Mandatory. The voice's quality model, e.g. enhanced or standard. (For backward compatibility, xpremium-high or xpremium are also accepted.) |
audio_params
Optional audio parameters set audio to Ogg Opus and include three other options
{
"voice":{
"name":"Evan",
"model":"enhanced"
},
"input":{
"text":{
"text":"This is a test. A very simple test."
}
},
"audio_params":{
"audio_format":{
"ogg_opus":{
"sample_rate_hz":16000
}
},
"volume_percentage": 100,
"speaking_rate_factor": 1.2,
"target_audio_length_ms": 10
}
}
Audio-related parameters for synthesis, including encoding, volume, and audio length. Included in synthesize. The default is PCM audio at 22050 Hz.
| Name | Type | Description |
|---|---|---|
| audio_format | audio_format | Audio encoding. Default PCM 22050 Hz. |
| volume_percentage | integer | Volume amplitude, from 0 to 100. Default 80. |
| speaking_rate_factor | number | Speaking rate, from 0 to 2.0. Default 1.0. |
| audio_chunk_ duration_ms | integer | Maximum duration, in ms, of an audio chunk delivered to the client, from 1 to 60000. Default is 20000 (20 seconds). When this parameter is large enough (for example, 20 or 30 seconds), each audio chunk contains an audible segment surrounded by silence. |
| target_audio_length_ms | integer | Maximum duration, in ms, of synthesized audio. When greater than 0, the server stops ongoing synthesis at the first sentence end, or silence, closest to the value. |
| disable_early_emission | boolean | By default, audio segments are emitted as soon as possible, even if they are not audible. This behavior may be disabled. |
audio_format
Audio encoding of synthesize text. Included in audio_params.
| Name | Type | Description |
|---|---|---|
| pcm | pcm | Signed 16-bit little endian PCM. |
| alaw | alaw | G.711 A-law, 8kHz. |
| ulaw | ulaw | G.711 Mu-law, 8kHz. |
| ogg_opus | ogg_opus | Ogg Opus, 8kHz,16kHz, or 24 kHz. |
| opus | opus | Opus, 8kHz, 16kHz, or 24kHz. The audio will be sent one Opus packet at a time. |
pcm
PCM sample rate changed to 16000 (from default 22050)
{
"voice":{
"name":"Evan",
"model":"enhanced"
},
"input":{
"text":{
"text":"This is a test. A very simple test."
}
},
"audio_params":{
"audio_format":{
"pcm":{
"sample_rate_hz": 16000
}
}
}
}
The PCM sample rate. Included in audio_format.
| Name | Type | Description |
|---|---|---|
| sample_rate_hz | integer | Output sample rate in Hz. Supported values: 8000, 11025, 16000, 22050, 24000. |
alaw
Audio format changed to A-law
{
"voice":{
"name":"Evan",
"model":"enhanced"
},
"input":{
"text":{
"text":"This is a test. A very simple test."
}
},
"audio_params":{
"audio_format":{
"alaw":{}
}
}
}
The A-law audio format. Included in audio_format. G.711 audio formats are set to 8 kHz.
ulaw
Audio format changed to Mu-law
{
"voice":{
"name":"Evan",
"model":"enhanced"
},
"input":{
"text":{
"text":"This is a test. A very simple test."
}
},
"audio_params":{
"audio_format":{
"ulaw":{}
}
}
}
The Mu-law audio format. Included in audio_format. G.711 audio formats are set to 8 kHz.
ogg_opus
Audio format changed to Ogg Opus
{
"voice":{
"name":"Evan",
"model":"enhanced"
},
"input":{
"text":{
"text":"This is a test. A very simple test."
}
},
"audio_params":{
"audio_format":{
"ogg_opus":{
"sample_rate_hz":16000
}
}
}
}
The Ogg Opus output rate. Included in audio_format.
| Name | Type | Description |
|---|---|---|
| sample_rate_hz | integer | Output sample rate in Hz. Supported values: 8000, 16000, 24000. |
| bit_rate_bps | integer | Valid range is 500 to 256000 bps. Default 28000. |
| max_frame_ duration_ms | number | Opus frame size in ms: 2.5, 5, 10, 20, 40, 60. Default 20. |
| complexity | integer | Computational complexity. A complexity of 0 means the codec default. |
| vbr | vbr | Variable bitrate. On by default. |
opus
Opus output rate. Included in audio_format.
| Name | Type | Description |
|---|---|---|
| sample_rate_hz | integer | Output sample rate in Hz. Supported values: 8000, 16000, 24000. |
| bit_rate_bps | integer | Valid range is 500 to 256000 bps. Default 28000. |
| max_frame_ duration_ms | number | Opus frame size in ms: 2.5, 5, 10, 20, 40, 60. Default 20. |
| complexity | integer | Computational complexity. A complexity of 0 means the codec default. |
| vbr | vbr | Variable bitrate. On by default. |
vbr
Settings for variable bitrate. Included in ogg_opus and opus. Turned on by default.
| Name | Number | Description |
|---|---|---|
| VARIABLE_BITRATE_ON | 0 | Use variable bitrate. Default. |
| VARIABLE_BITRATE_OFF | 1 | Do not use variable bitrate. |
| VARIABLE_BITRATE_ CONSTRAINED | 2 | Use constrained variable bitrate. |
input
Miminal mandatory input
{
"voice":{
"name":"Evan",
"model":"enhanced"
},
"input":{
"text":{
"text":"This is a test. A very simple test."
}
}
}
Text to synthesize and synthesis parameters, including tuning data, etc. Included in synthesize. The type of input may be plain text, SSML, or a sequence of plain text and Nuance control codes.
| Name | Type | Description |
|---|---|---|
| text | text | Plain text input. |
| ssml | ssml | SSML input, including text and SSML elements. |
| tokenized_sequence | tokenized_sequence | Sequence of text and Nuance control codes. |
| resources | resources | Repeated. Synthesis resources (user dictionaries, rulesets, etc.) to tune synthesized audio. Default empty. |
| lid_params | lid_params | LID parameters. |
| download_params | download_params | Remote file download parameters. |
text
Input for synthesizing plain text. The encoding must be UTF-8. Included in input.
| Name | Type | Description |
|---|---|---|
| text | string | Plain input text in UTF-8 encoding. |
| uri | string | Remote URI to the plain input text. Not supported in Nuance-hosted NVC. |
ssml
Minimal SSML input
{
"voice": {
"name": "Evan",
"model": "enhanced"
},
"input": {
"ssml": {
"text": "<speak>This is an SSML test. A super simple test.</speak>"
}
}
}
Input for synthesizing SSML. Included in input. See SSML tags for a list of supported elements.
| Name | Type | Description |
|---|---|---|
| text | string | SSML input text and elements. |
| uri | string | Remote URI to the SSML input text. Not supported in Nuance-hosted NVC. |
| ssml_validation_mode | ssml_validation_mode | SSML validation mode. Default STRICT. |
ssml_validation_mode
SSML validation mode when using SSML input. Included in ssml. Strict by default but can be relaxed.
| Name | Number | Description |
|---|---|---|
| STRICT | 0 | Strict SSL validation. Default. |
| WARN | 1 | Give warning only. |
| NONE | 2 | Do not validate. |
tokenized_sequence
Input for synthesizing a sequence of plain text and Nuance control codes. Included in input.
| Name | Type | Description |
|---|---|---|
| tokens | tokens | Repeated. Sequence of text and control codes. |
tokens
The unit when using tokenized_sequence for input. Included in tokenized_sequence. Each token can be either plain text or a Nuance control code. See Control codes for supported codes.
| Name | Type | Description |
|---|---|---|
| text | string | Plain input text. |
| control_code | control_code | Nuance control code. |
control_code
Nuance control code that specifies how text should be spoken, similarly to SSML. Included in tokens.
| Name | Type | Description |
|---|---|---|
| key | string | Name of the control code, e.g. 'pause' |
| value | string | Value of the control code. |
resources
A resource for tuning the synthesized output. Included in input.
| Name | Type | Description |
|---|---|---|
| type | type | Resource type, e.g. user dictionary, etc. Default USER_DICTIONARY. |
| uri | string | URI to the remote resource. Either a URL or local file reference, or the URN of a resource previously uploaded to cloud storage with the Storage API. See URNs for the format. |
| body | bytes | For resource type USER_DICTIONARY, the contents of the file. |
type
The type of synthesis resource to tune the output. Included in resources. User dictionaries provide custom pronunciations, rulesets apply search-and-replace rules to input text, and ActivePrompt databases help tune synthesized audio under certain conditions, using Nuance Vocalizer Studio.
| Name | Number | Description |
|---|---|---|
| USER_DICTIONARY | 0 | User dictionary (application/edct-bin-dictionary). Default. |
| TEXT_USER_RULESET | 1 | Text user ruleset (application/x-vocalizer-rettt+text). |
| BINARY_USER_RULESET | 2 | Not supported. Binary user ruleset (application/x-vocalizer-rettt+bin). |
| ACTIVEPROMPT_DB | 3 | ActivePrompt database (application/x-vocalizer-activeprompt-db). |
| ACTIVEPROMPT_DB_AUTO | 4 | ActivePrompt database with automatic insertion (application/x-vocalizer-activeprompt-db;mode=automatic). |
| SYSTEM_DICTIONARY | 5 | Nuance system dictionary (application/sdct-bin-dictionary). |
lid_params
Parameters for controlling the language identifier. Included in input. The language identifier runs on input blocks labeled with the control code lang unknown or the SSML attribute xml:lang="unknown". The language identifier automatically restricts the matched languages to the installed voices. This limits the permissible languages, and also sets the order of precedence (first to last) when they have equal confidence scores.
| Name | Type | Description |
|---|---|---|
| disable | boolean | Whether to disable language identification. Turned on by default. |
| languages | string | Repeated. List of three-letter language codes (e.g. enu, frc, spm) to restrict language identification results, in order of precedence. Use voices to obtain the three-letter codes, returned in language_tlw. Default empty. |
| always_use_ highest_confidence | boolean | If enabled, language identification always chooses the language with the highest confidence score, even if the score is low. Default false, meaning use language with any confidence. |
download_params
Parameters for remote file download, whether for input text (input.uri) or a synthesis resource (resource.uri). Included in input.
| Name | Type | Description |
|---|---|---|
| headers | map<string,string> | Map of HTTP header name,value pairs to include in outgoing requests. Supported headers: max_age, max_stale. |
| request_timeout_ms | integer | Request timeout in ms. Default (0) means server default, usually 30000 (30 seconds). |
| refuse_cookies | boolean | Whether to disable cookies. By default, HTTP requests accept cookies. |
event_params
Event parameters
{
"voice": {
"name": "Evan",
"model": "enhanced"
},
"input": {
"text": {
"text": "This is a test. A very simple test."
}
},
"event_params": {
"send_log_events" true,
"send_sentence_marker_events": true,
"send_word_marker_events": true
}
}
Event subscription parameters. Included in synthesize. Requested events are reported in the response.
| Name | Type | Description |
|---|---|---|
| send_sentence_marker_events | boolean | Sentence marker. Default: do not send. |
| send_word_marker_events | boolean | Word marker. Default: do not send. |
| send_phoneme_marker_events | boolean | Phoneme marker. Default: do not send. |
| send_bookmark_marker_events | boolean | Bookmark marker. Default: do not send. |
| send_paragraph_marker_events | boolean | Paragraph marker. Default: do not send. |
| send_visemes | boolean | Lipsync information. Default: do not send. |
| send_log_events | boolean | Whether to log events during synthesis. By default, logging is turned off. |
| suppress_input | boolean | Whether to omit input text and URIs from log events. By default, these items are included. |
Response to synthesize
Basic response returns base64 audio
$ curl -H "Authorization: Bearer $MY_TOKEN" \
https://tts.api.nuance.co.uk/api/v1/synthesize \
-d '{ "voice": { "name": "Evan", "model": "enhanced" },
"input": { "text": { "text": "This is a test. A very simple test."} } }'
{
"status": {
"code": 200,
"message": "OK",
"details": ""
},
"audio": "AAAAAAAAA..."
}
Python processing in http-wav-client.py converts base64 audio to wav format
#!/usr/bin/env python3
import requests as req
import base64
import os
import argparse
global args
# Generates the .wav file header for a given set of parameters
def generate_wav_header(sampleRate, bitsPerSample, channels, datasize, formattype):
# (4byte) Marks file as RIFF
o = bytes("RIFF", 'ascii')
# (4byte) File size in bytes excluding this and RIFF marker
o += (datasize + 36).to_bytes(4, 'little')
# (4byte) File type
o += bytes("WAVE", 'ascii')
# (4byte) Format Chunk Marker
o += bytes("fmt ", 'ascii')
# (4byte) Length of above format data
o += (16).to_bytes(4, 'little')
# (2byte) Format type (1 - PCM)
o += (formattype).to_bytes(2, 'little')
# (2byte) Will always be 1 for TTS
o += (channels).to_bytes(2, 'little')
# (4byte)
o += (sampleRate).to_bytes(4, 'little')
o += (sampleRate * channels * bitsPerSample // 8).to_bytes(4, 'little') # (4byte)
o += (channels * bitsPerSample // 8).to_bytes(2,'little') # (2byte)
# (2byte)
o += (bitsPerSample).to_bytes(2, 'little')
# (4byte) Data Chunk Marker
o += bytes("data", 'ascii')
# (4byte) Data size in bytes
o += (datasize).to_bytes(4, 'little')
return o
token = os.getenv('MY_TOKEN')
parser = argparse.ArgumentParser(description='TTS HTTP Client')
options = parser.add_argument_group("options")
options.add_argument("--wav", action="store_true",
help="Save audio file in WAVE format")
options.add_argument("--voice", nargs="?",
help="Voice name (default=Evan)", default="Evan")
options.add_argument("--model", nargs="?",
help="Voice model type (default=enhanced)", default="enhanced")
options.add_argument("--type", nargs="?",
help="Input type: text or ssml (default=text)", default="text")
options.add_argument("--input", nargs="?",
help="Input text (default=This is a test)", default="This is a test.")
args = parser.parse_args()
http_headers = {}
http_headers['Authorization'] = "Bearer {}".format(token)
formatted_data = '{{ "voice": {{ "name": "{voice_name}", "model": "{model_name}" }}, "input": {{ "{input_type}": {{ "text": "{input_text}"}} }} }}'.format(voice_name=args.voice, model_name=args.model, input_type=args.type, input_text=args.input)
response = req.post('https://tts.api.nuance.co.uk/api/v1/synthesize', data=formatted_data, headers=http_headers)
if response.status_code != 200:
raise Exception("Failed to synthesize. Status: {}".format(response.status_code))
json_response = response.json()
if json_response["status"]["code"] != 200:
print("Failed to synthesize. Message: {}. Status: {}".format(json_response["status"]["message"], json_response["status"]["code"]))
else:
decoded_audio_response = base64.b64decode(json_response["audio"])
waveheader = generate_wav_header(22050, 16, 1, len(decoded_audio_response), 1)
if response.status_code == 200:
if args.wav:
with open("output.wav","wb") as output_file:
output_file.seek(0, 0)
output_file.write(waveheader)
output_file.seek(0, 2)
output_file.write(decoded_audio_response)
print("Audio successfully written to", output_file.name)
else:
with open("output.raw", "wb") as output_file:
output_file.write(decoded_audio_response)
print("Audio successfully written to", output_file.name)
The synthesize command returns a unary (non-streamed) message containing:
- A status code, indicating completion or failure of the request. See Status codes.
- A list of events the client has requested. See event_params for details.
- The complete audio buffer of the synthesized text, in base64 format.
A successful response returns the synthesized audio in base64 format. Additional processing is required to convert this audio to a playable audio format. See the Python example at the right.
Source the get-token.sh script (see Base URL and authorization to generate and export an authorization token, then call the Python client. This client accepts the following options:
$ ./http-wav-client.py --help
usage: http-wav-client.py [-h] [--wav] [--voice [VOICE]] [--model [MODEL]]
[--type [TYPE]] [--input [INPUT]]
TTS HTTP Client
optional arguments:
-h, --help show this help message and exit
options:
--wav Save audio file in WAVE format
--voice [VOICE] Voice name (default=Evan)
--model [MODEL] Voice model type (default=enhanced)
--type [TYPE] Input type: text or ssml (default=text)
--input [INPUT] Input text (default=This is a test)
This example uses the default voice and input but sets the output file to wav format:
$ source get-token.sh $ ./http-wav-client.py --wav Audio successfully written to output.wav
Optionally use a different voice and specify your own input:
$ ./http-wav-client.py --wav --voice "Zoe-Ml" --input "Shall I compare thee to a summers day" Audio successfully written to output.wav
Or change to SSML input:
$ ./http-wav-client.py --wav --voice "Zoe-Ml" --type "ssml" --input "<speak>Thou art more lovely and more temperate.</speak>"
Your authorization token expires after a short period of time. Re-run get-token.sh when you get a 401 status error: Failed to synthesize. Status: 401.See Status codes for other codes.
Known issues
These issues have been reported in NVC.
Different alphabet gives no audio, no error
Sending input characters outside of a voice's writing system (for example, Chinese characters to an English or German voice) usually fails to create output audio, but no error is reported: the synthesis request returns a successful response.
A few voices can accept input in a writing system other than its own and create output audio, although the synthesis may not be correct. In all other cases, no audio is produced and no error is reported. Note that when the non-Latin text contains punctuation marks, these are spelled out.
Chinese writing systems
- Korean voices produce correct audio synthesis from Chinese input, as Korean input often contains Chinese characters.
Cyrillic alphabet
- Croatian, Australian English, UK English, US English, and Korean voices produce audio from Cyrillic input, but the synthesis may not be correct.
- Some Japanese voices spell out Cyrillic input.
Greek alphabet
- Croatian, Australian English, UK English, US English, and Korean voices produce audio from Greek input, but the synthesis may not be correct.
- Some Japanese voices spell out Greek input.
Japanese writing systems
- Korean voices produce audio from Japanese input, but the synthesis may not be correct.
Multiple writing systems
- Some “-Ml" (multilingual) voices can accept input in multiple writing systems and create correct audio synthesis. For example Lili-Ml, a Mandarin voice, accepts input in Chinese characters as well as Latin characters for its additional languages, US and UK English. To learn about the supported voices in your environment, send a GetVoicesRequest, for example using the Sample synthesis client - Run client for voices.
See also the list of supported voices in the Mix documentation: Text-to-Speech (TTS) voices - Additional languages.
Change log
2022-07-04
These new features were added:
Audio WAV files can be referenced through a secure URL, using SSML or Nuance tokenized sequences. See Audio file, SSML tags - audio, and Control codes - audio. In previous versions, audio files were available only via URN.
Alternative text is supported in SSML audio elements. If the audio file is unavailable or the wrong format, NVC synthesizes this alternative text.
2022-03-16
An issue with voices was reported in Known issues.
2021-12-07
New features in this release include:
- An HTTP API for Synthesizer uses a transcoder to the gRPC API. This feature lets you use a REST API to get voices and request synthesis. See Synthesizer HTTP API.
- A new control code, tn=scope, activates a user dictionary for a specific scope. See Control codes.
2021-10-06
An argument of the synthesis client was renamed from saveAudioinWave to saveAudioAsWav.
2021-07-21
The gRPC protocol was updated with the following:
- A new field was added to GetVoicesResponse - Voice: foreign_languages, to return the additional languages available for multilingual ("Ml") voices. To use this feature, download the updated proto files from gRPC setup.
- For security reasons, binary (encrypted) rulesets are no longer supported.
2021 -07-07
In SSML input, the <xml> element and the attributes of the <speak> element are optional in NVC. See SSML tags.
2021-06-23
The documentation was updated with these changes:
- The SSML tag and control code, name, was updated to reflect its handling of proper names with roman numerals.
- The SSML tag and control code, number, was removed from the documentation as it is not supported. The digits code was corrected to be an alias of spell:alphanumeric.
2021-06-09
The SSML tag and Nuance control code, pitch, was added to the documentation. See Reference topics - SSML tags and Control codes.
2021-06-02
These changes were made:
- A new API for uploading resources to cloud storage is provided in the Storage gRPC proto file. See Storage API. These files include storage.proto plus a set of RPC message proto files, all arranged in a specific path structure. See gRPC setup for details.
- The simple Mix client now saves the synthesized speech as a wav file instead of a headerless PCM file, meaning you can play it directly using any audio player. See Client app development - Try it out.
2020-12-21
Updated CLIENT_ID example to show new Mix syntax.
2020-10-27
A unary synthesis scenario was added to the Sample Python app section.
2020-09-30
These changes were made:
- The proto file was updated to include new/modified fields. See gRPC setup.
- A new field, version, was added to GetVoicesResponse to identify the voice's version.
- The voice - language field is used only for GetVoicesRequest and GetVoicesResponse. It is ignored for SynthesisRequest.
- The sample Python app was updated and made available for download. See Sample synthesis client.
- A new scenario, Multiple requests, was added to the Sample Python app section.
- The documentation for the v1beta1 protocol was removed as that protocol is obsolete.
2020-08-19
These changes were made:
- The proto file was renamed from nuance_tts.proto to synthesizer.proto.
- The sample Python application was updated to use the new proto file and for other small changes. See Sample synthesis client.
- Two status codes were added. See Status codes.
- The v1beta1 protocol is obsolete and is no longer supported.
- An SSML tag and control code, style, was added. See Input to synthesize.
2020-06-24
The TTS v1beta1 protocol is deprecated: it is currently being monitored and may be removed in the near future. If you are using v1beta1, we recommend that you upgrade to v1.
2020-05-31
These changes were made to the API and documentation:
- A new field, user_id, was added to the nuance_tts.proto file.
- A new field, restricted, was added to the proto file to identify custom voices.
2020-04-30
These changes were made to the documentation:
- Supported SSML elements were added in a new topic, SSML tags.
- The timbre control item was added to the Control codes and SSML tags.
2020-03-31
These changes were made to the API and documentation:
The protocol was updated from version v1beta1 to v1 and a new proto file was added to gRPC setup.
The Input message was reworked as follows. See Input to synthesize and Control codes.
| v1beta1 | v1 |
|---|---|
| message Input { string type = 1; oneof input_data { string uri = 2; string body = 3; bytes body_as_bytes = 4; } string escape_sequence = 5; } |
message Input { oneof input_data { Text text = 1; SSML ssml = 2; TokenizedSequence tokenized_sequence = 3; } } message Text {} message SSML {} message TokenizedSequence {} message Token {} message ControlCode {} |
Field renamed: EnumSSMLValidation → EnumSSMLValidationMode.
Fields renamed and type changed: speaking_rate_percentage (uint32) → speaking_rate_factor (float), values from 0 to 2.0.
Download parameters, max_age and max_stale → headers (map<string,string).
The AudioFormat - opus field (representing Ogg Opus) was replaced with opus (for raw Opus) and ogg_opus for Ogg-encapsulated Opus audio.
Field removed: escape_sequence. This field is no longer required as TTS assembles the text and control codes rather than the user.
An example of an inline user dictionary was added. See Inline dictionary.
2020-02-19
These changes were made to the API and documentation:
- Updated a new proto file to download in gRPC setup. This proto file includes new Opus fields.
- Support for raw Opus as well as Ogg-encapsulated Opus. See AudioFormat.
- Images illustrating the structure of the proto file were added to the API section. See Proto file structure.
2020-01-22
These changes were made to the API and documentation:
- UnarySynthesisResponse was added to the API, allowing synthesized audio to be returned in one package. In the standard SynthesisResponse, audio is streamed to the client in cumulative buffers.
- Examples were added in the Go programming language.
2019-12-18
The voice model names have changed, from xpremium to standard and xpremium-high to enhanced, etc. The old names are supported but deprecated and may be removed in a later version.
2019-12-02
Updated a new proto file to download in gRPC setup. This proto file disables Input - body_as_bytes.
2019-11-15
Below are changes made to the TTSaaS gRPC API documentation since the initial Beta release:
- Changed the documentation structure to include the API version in the URL.
- Added Prerequisites from Mix section.
- Added sequence flow diagram in Client app development.
- Added more information on how to generate a token, in Client app development.
- Added a new proto file field, language_tlw, in Voice.
- Updated the proto file to download in gRPC setup.