
NLU as a Service gRPC API
Nuance NLU extracts meaning from what your users say or write
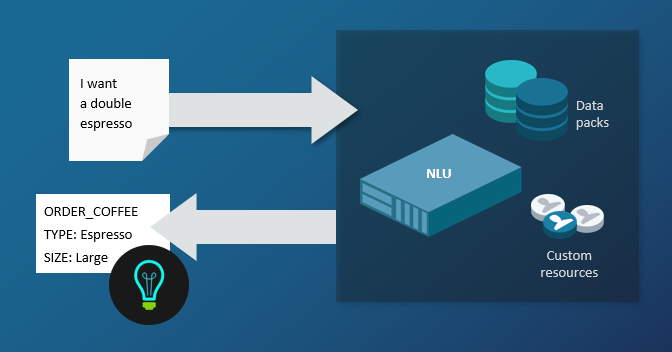
The Nuance NLU (Natural Language Understanding) service turns text into meaning, extracting the underlying meaning of what your users say or write, in a form that an application can understand. NLU as a Service provides a semantic interpretation of the user’s input.
NLU works with a data pack for your language and locale, and a semantic language model customized for your application. It can also use interpretation aids such as additional language models, dictionaries, and wordsets to improve understanding in specific environments or businesses.
The gRPC protocol provided by NLU allows a client application to request interpretation services in all the programming languages supported by gRPC.
gRPC is an open source RPC (remote procedure call) software used to create services. It uses HTTP/2 for transport, and protocol buffers to define the structure of the application. NLU supports Protocol Buffers version 3, also know as proto3.
Version: v1
This release supports the v1 version of the gRPC protocol.
- The v1 protocol is the supported version. See gRPC setup to download the proto files and get started.
- The v1beta1 protocol is now obsolete. It is no longer supported and will generate errors if used in an application. If you have not already done so, you need to migrate your applications from v1beta1 to v1.
Upgrading to v1
To upgrade to the v1 protocol from v1beta1, you need to regenerate your programming-language stub files from the new proto files, then make small adjustments to your client application.
First regenerate your client stubs from the new proto files, as described in gRPC setup.
- Download zip files containing the gRPC proto files for the Runtime service and the Wordset service. We recommend you make a new directory for the v1 files.
- Use gRPC tools to generate the client stubs from the proto file.
- Notice the new client stub files.
Then adjust your client application for the changes made to the protocol in v1. See gRPC API for details of each item.
Rename the main service Nlu → Runtime, and rename the client stub:
NluStub → RuntimeStub (Python)
NewNluClient → NewRuntimeClient (Go)
NluGrpc.NluBlockingStub → RuntimeGrpc.RuntimeBlockingStub (Java)In InterpretRequest, rename client_tags → client_data.
In EnumInterpretationInputLoggingMode, rename OFF → SUPPRESSED.
Remove ENCRYPTED as this value is not supported.In ResourceReference, replace max_age, max_stale, min_fresh, and cookies with headers (map<string,string>) of header name-value pairs.
In InterpretResponse, cookies (map<string,string>) has been removed.
In MultiIntentInterpretation - InterpretationNode -
IntentNode: EntityNode → InterpretationNode.
EntityNode: EntityNode → InterpretationNode.In InterpretResult - Interpretation, the misspelled multi_intent_intepretation → multi_intent_interpretation.
A new field, literal, is in SingleIntentEntity, OperatorNode, IntentNode, and EntityNode.
Update the format of the URN that references your models: from
urn:nuance:mix/<language>/<context_tag>/mix.nlu→
urn:nuance-mix:tag:model/<context_tag>/mix.nlu?=language=<language>For example:
urn:nuance-mix:tag:model/A77_C1/mix.nlu?=language=eng-USAThe original URN format is supported but deprecated.
NLU essentials
Natural language understanding (NLU) is one of the components of a rich conversational voice experience for your end users. NLUaaS uses engines hosted by Nuance and is accessible from a single gRPC interface.
How it works
NLUaaS accepts input from the user. This input can be text written by the user or the result of user speech transcribed into text by automatic speech recognition (ASR).
NLU applies transformation rules to the text of user input and performs formatting of output for display or further processing.
It derives domain-specific meaning from text using speech technology based on artificial intelligence (AI) and machine learning.
It interprets the text of the input with the aid of a Nuance data pack and a semantic model created in Mix.nlu, returning a semantic interpretation.
Your client application can use this result to drive the next human-machine turn.
Intents and entities
NLUaaS interpretation results consist of one or more hypotheses of the meaning of the user input. Each hypothesis contains intents and entities, along with NLU's confidence in the hypothesis.
An intent is the overall meaning of the user input in a form an application can understand, for example PAY_BILL, PLACE_ORDER, BOOK_FLIGHT, or GET_INFO. See Interpretation results: Intents for some examples.
Entities (also known as concepts) define the meaning of individual words within the input. They represent categories of things that are important to the intent. For example, the PLACE_ORDER intent might have entities such as PRODUCT, FLAVOR, and QTY. Each entity contains a set of values, so the FLAVOR entity could have values such as Chocolate, Strawberry, Blueberry, Vanilla, and so on.
At runtime, NLU interprets the sentence I’d like to order a dozen blueberry pies as:
- Intent: PLACE_ORDER
- Entities:
- dozen = QTY: 12
- blueberry = FLAVOR: Blueberry
- pie = PRODUCT: Pie
List entities have specific values, while other types of entity have values defined in a grammar file and/or regular expression. See Interpretation results: Entities for examples.
Extending the model
For more flexibility, you can extend your semantic model with wordsets containing additional terms for dynamic list entities. For entities with small numbers of terms (less than 100), an inline wordset can be included with the interpretation request at runtime. The wordset gets compiled at runtime and used as a resource to improve interpretation. This is convenient and simple, but for large wordsets (hundreds of items and above), this can lead to issues with latency.
As an alternative for larger wordsets, wordset files can be uploaded to Mix ahead of time to be compiled using a separate Wordset API. The compiled wordsets are saved in Mix and can later be accessed at runtime as an external reference. For large wordsets, this can significantly reduce latency in interpretation requests. If in doubt about which approach to take, test the latency with inline wordsets.
Prerequisites from Mix
Before developing your gRPC application, you need a Mix project that provides an NLU model as well as authorization credentials.
Create a Mix project and model: see Mix.nlu workflow to:
Create a Mix project.
Create, train, and build a model in the project.
Create and deploy an application configuration for the project.
Learn how to reference the semantic model in your application. You may only reference models created in your Mix project. See Mix.dashboard URN.
Generate a "secret" and client ID of your Mix project: see Mix.dashboard Authorize your client application. Later you will use these credentials to request an access token to run your application.
Learn the URL to call the NLU service: see Mix.dashboard Accessing a runtime service.
gRPC setup
Download and unzip Runtime proto files
├── nuance
│ └── nlu
│ └── v1
│ ├── runtime.proto
│ ├── result.proto
│ ├── interpretation-common.proto
│ ├── single-intent-interpretation.proto
│ └── multi-intent-interpretation.proto
│
└── nuance_runtime_proto_files.zip
Download and unzip Wordset proto files
├── nuance
│ ├── nlu
│ │ ├── wordset
│ │ │ └── v1beta1
│ │ │ └── wordset.proto
│ │ └── common
│ │ └── v1beta1
│ │ ├── job.proto
│ │ └── resource.proto
│ └── rpc
│ ├── error_details.proto
│ ├── status_code.proto
│ └── status.proto
└── nuance_wordset_proto_files.zip
Install gRPC for Python
$ python3 -m venv env
$ source env/bin/activate
$ pip install grpcio
$ pip install grpcio-tools
$ mkdir -p google/api
$ curl https://raw.githubusercontent.com/googleapis/googleapis/master/google/api/annotations.proto \
google/api/annotations.proto
$ curl https://raw.githubusercontent.com/googleapis/googleapis/master/google/api/http.proto \
google/api/http.proto
Generate client stubs from proto files
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
--grpc_python_out=./ nuance/nlu/v1/runtime.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/result.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/interpretation-common.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/single-intent-interpretation.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/multi-intent-interpretation.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
--grpc_python_out=./ nuance/nlu/wordset/v1beta1/wordset.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/common/v1beta1/job.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/common/v1beta1/resource.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/rpc/status.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/rpc/status_code.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/rpc/error_details.proto
Final structure of stub files
├── nuance
├── nlu
│ ├── v1
│ │ ├── runtime_pb2.py
│ │ ├── runtime_pb2_grpc.py
│ │ ├── result_pb2.py
│ │ ├── interpretation-common_pb2.py
│ │ ├── single-intent-interpretation_pb2.py
│ │ └── multi-intent-interpretation_pb2.py
│ ├── wordset
│ │ └── v1beta1
│ │ ├── wordset_pb2.py
│ │ └── wordset_grpc_pb2.py
│ └── common
│ └── v1beta1
│ ├── job_pb2.py
│ └── resource_pb2.py
└── rpc
├── error_details_pb2.py
├── status_code_pb2.py
└── status_pb2.py
The basic steps in using the NLUaaS gRPC API are:
Install gRPC for the programming language of your choice, including C++, Java, Python, Go, Ruby, C#, Node.js, and others. See gRPC Documentation for a complete list and instructions on using gRPC with each language.
Download the zip files containing the gRPC proto files for the Runtime service and the Wordset service and related messages. Together, these zip files contain several sets of proto files:
- nuance/nlu/v1/ contains protos related to runtime NLU interpretation: runtime.proto, result.proto, interpretation-common.proto, single-intent-interpretation.proto, and multi-intent-interpretation.proto.
- nuance/nlu/wordset/v1beta1/ contains wordset.proto with RPCs and messages related to working with compiled wordsets.
- nuance/nlu/common/v1beta1/ contains generic classes for referencing external resources and for job status updates: job.proto and resource.proto
- nuance/rpc/ contains generic classes for status and error codes: status.proto, status_code.proto, and error_details.proto.
- nuance/nlu/v1/ contains protos related to runtime NLU interpretation: runtime.proto, result.proto, interpretation-common.proto, single-intent-interpretation.proto, and multi-intent-interpretation.proto.
Unzip the files in a location that your applications can access, for example in a directory containing your client apps. If you have proto files and applications from an earlier version of NLUaaS, we recommend you create a new directory to hold the new files. This will make it easier to identify the Runtime and Wordset files in their new path structure.
Generate client stub files in your programming language from the proto files using gRPC protoc. Depending on your programming language, the stubs may consist of one file or multiple files per proto file. These stub files contain the methods and fields from the proto files as implemented in your programming language. You will consult the stubs with the proto files.
Write your client application, referencing the functions or classes in the client stub files. See Client runtime app development for details.
Run your client app to request text interpretation, optionally passing in NLU models and wordsets.
Runtime app development
The gRPC protocol for NLU lets you create a client application for requesting and receiving semantic interpretation from input text. This section describes how to implement the basic functionality of NLU in the context of a Python application. For the complete application, see Sample Python runtime client.
The essential tasks are shown in the following high-level sequence flow:
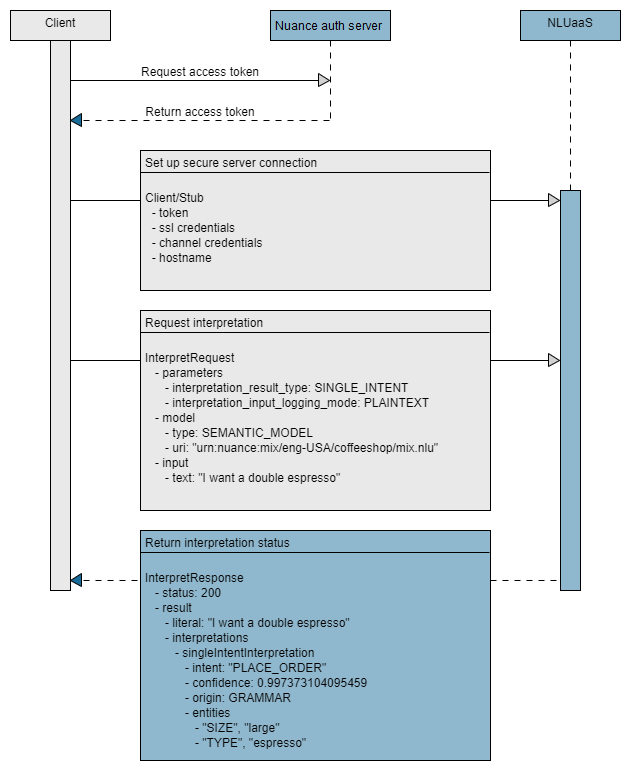
Step 1: Generate token
The run-nlu-client.sh script requests the token then runs the application
#!/bin/bash
CLIENT_ID=“appID%3ANMDPTRIAL_your_name_company_com_20201102T144327123022%3Ageo%3Aus%3AclientName%3Adefault”
SECRET="5JEAu0YSAjV97oV3BWy2PRofy6V8FGmywiUbc0UfkGE"
export TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" "https://auth.crt.nuance.com/oauth2/token" \
-d "grant_type=client_credentials" -d "scope=tts nlu asr" \
| python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`"
./nlu_client.py --serverUrl nlu.api.nuance.com:443 --secure --token $TOKEN
--modelUrn "urn:nuance-mix:tag:model/bakery/mix.nlu?=language=eng-USA"
--textInput "$1" --wordsetUrn "urn:nuance-mix:tag:wordset:lang/bakery/item_names/eng-USA/mix.nlu"
Nuance Mix uses the OAuth 2.0 protocol for authorization. Your client application must provide an access token to be able to access the NLU runtime service. The token expires after a short period of time so must be regenerated frequently.
Your client application uses the client ID and secret from the Mix Dashboard (see Prerequisites from Mix) to generate an access token from the Nuance authorization server.
The client ID starts with appID: followed by a unique identifier. If you are using the curl command, replace the colon with %3A so the value can be parsed correctly:
appID:NMDPTRIAL_your_name_company_com_2020... --> appID%3ANMDPTRIAL_your_name_company_com_2020...
You can generate the token in one of several ways, either as part of the client application or as a script file. This Python sample uses a Linux script to generate a token and store it in an environment variable. The token is then passed as an argument to the application, where it is used to create a secure connection to the NLU service.
Note that the same token should be reused until it expires rather than requested for each interpretation. Generating a new token every time adds to latency. Also, token request has more strict rate limits in place.
Step 2: Import functions
Import functions from stubs
from nuance.nlu.v1.runtime_pb2 import *
from nuance.nlu.v1.runtime_pb2_grpc import *
from nuance.nlu.v1.result_pb2 import *
In your client application, import all functions from the client stubs that you generated in gRPC setup.
Do not edit these stub files.
Step 3: Authorize and connect
The Python app uses the token as it creates the secure connection to the NLU service
def create_channel(args):
channel = None
call_credentials = None
if args.token:
log.debug("Adding CallCredentials with token %s" % args.token)
call_credentials = grpc.access_token_call_credentials(args.token)
log.debug("Creating secure gRPC channel")
channel_credentials = grpc.ssl_channel_credentials()
channel_credentials = grpc.composite_channel_credentials(channel_credentials, call_credentials)
channel = grpc.secure_channel(args.serverUrl, credentials=channel_credentials)
return channel
You create a secure gRPC channel and authorize your application to the NLU service by providing the URL of the hosted NLU service and an access token.
In the Python example, the URL of the NLU service is passed to the application as a command line argument. The URL is passed as the first argument: nlu.api.nuance.co.uk:443
Step 4: Configure interpret request
Configure interpret request
# Single intent, plain text logging
params = InterpretationParameters(
Interpretation_result_type=EnumInterpretationResultType.SINGLE_INTENT, interpretation_input_logging_mode=EnumInterpretationInputLoggingMode.PLAINTEXT)
# Reference the model
model = ResourceReference(
type=EnumResourceType.SEMANTIC_MODEL,
uri=args.modelUrn)
# Reference compiled wordset
wordset_reference = ResourceReference(
type=EnumResourceType.COMPILED_WORDSET,
uri = args.wordsetUrn,
request_timeout_ms = 5000)
resource = InterpretationResource(external_reference = wordset_reference)
resources = [resource]
# Describe the text to perform interpretation on
input = InterpretationInput(
text=args.textInput)
# Build the request
interpret_req = InterpretRequest(
parameters=params,
model=model,
resources = resources,
input=input)
An interpretation request includes InterpretationParameters that define the type of interpretation you want. Consult your generated stubs for the precise parameter names. Some parameters are:
- Interpretation result type: Single or multi-intent interpretation.
- Logging mode: Format for log input.
It also includes resources referenced to help with the interpretation. This includes:
Model (mandatory): The semantic model created in Mix.nlu.
Resources: A list of wordsets, either inline or compiled.
The input to interpret must also be provided, either plain text or the result from a call to ASRaaS.
For more details, see InterpretRequest.
Step 5: Call Runtime client stub
Call Runtime client stub
with create_channel(args) as channel:
stub = RuntimeStub(channel)
response = stub.Interpret(construct_interpret_request(args))
print(MessageToJson(response))
print("Done")
With a communication channel established, the app calls a client stub function or class, which makes use of the channel. This stub is based on the main service name and is defined in the generated client files. In Python it is named RuntimeStub.
Step 6: Request interpretation
Request interpretation
def main():
args = parse_args()
log_level = logging.DEBUG
logging.basicConfig(
format='%(lineno)d %(asctime)s %(levelname)-5s: %(message)s', level=log_level)
with create_channel(args) as channel:
stub = RuntimeStub(channel)
response = stub.Interpret(construct_interpret_request(args))
print(MessageToJson(response))
print("Done")
After configuring the InterpretRequest and calling the client stub, you can send the InterpretRequest.
Step 7: Process results
Receive results
def process_result(response):
print(MessageToJson(response))
Finally the app returns the results received from the NLU engine. These applications format the interpretation result as a JSON object, similar to the Try panel in Mix.nlu.
For details about the structure of the result, see InterpretResult.
Wordset app development
The previous section gives high-level guidance on how to develop a basic NLU client application that can interpret intents and entities from text inputs. Accuracy on interpretation of values for some types of entities can often be greatly improved by providing wordsets that define values to expect.
With the gRPC Wordset API for NLU, you can create a client application to perform requested wordset operations:
- Compile wordsets
- Retrieve wordset metadata
- Delete wordsets.
This section describes how to implement the basic wordsets functionality in the context of a Python application. For the complete application, see Sample Python wordsets client.
Step 1: Generate token
This is similar to what is done for the client runtime app. Note that when generating the token, you must specify the nlu.wordset scope.
export TOKEN="... -d "scope=tts nlu asr nlu.wordset" ..."
Step 2: Import functions
Import functions from stubs
from nuance.nlu.wordset.v1beta1.wordset_pb2 import *
from nuance.nlu.wordset.v1beta1.wordset_pb2_grpc import *
from nuance.nlu.common.v1beta1.resource_pb2 import *
In your client application, import all functions from the wordset client stubs that you generated in gRPC setup.
Do not edit these stub files.
Step 3: Authorize and connect
This is the same as for the client runtime app.
Step 4: Configure wordset request
Configure compile wordset request
def create_compile_wordset_request(args):
target_artifact_reference = ResourceReference(uri=args.artifactUrn)
companion_artifact_reference = ResourceReference(uri=args.modelUrn)
wordset = json.dumps(json.load(args.wordsetFile))
return CompileWordsetRequest(
target_artifact_reference=target_artifact_reference,
companion_artifact_reference=companion_artifact_reference,
wordset=wordset,
metadata=list_to_dict(args.metadata),
client_data=list_to_dict(args.clientData))
Configure get metadata request
def create_get_wordset_metadata_request(artifactUrn):
artifact_reference = ResourceReference(uri=artifactUrn)
return GetWordsetMetadataRequest(artifact_reference=artifact_reference)
Configure delete wordset request
def create_delete_wordset_request(artifactUrn):
artifact_reference = ResourceReference(uri=artifactUrn)
return DeleteWordsetRequest(artifact_reference=artifact_reference)
With authorization complete, you can configure your request to:
- Compile a wordset: You need to provide a URN reference for the companion DLM, a URN reference to use for the compiled wordset, and a JSON wordset
- Get metadata for a compiled wordset: Provide the URN reference for the wordset
- Delete a compiled wordset: provide the URN reference for the wordset
Step 5: Call Wordset client stub
Call Wordset client stub
with create_channel(args) as channel:
stub = WordsetStub(channel)
With a communication channel established, the app calls a client stub function or class, which makes use of the channel. This stub is based on the main service name and is defined in the generated client files. In Python it is named WordsetStub.
Step 6: Perform wordset operation
Compile a wordset
def compile_wordset(args):
with create_channel(args) as channel:
stub = WordsetStub(channel)
compiled_wordset_request = create_compile_wordset_request(args)
for message in stub.CompileWordsetAndWatch(compiled_wordset_request):
print(MessageToJson(message))
Retrieve wordset metadata
def get_wordset_metadata(args):
with create_channel(args) as channel:
stub = WordsetStub(channel)
response = stub.GetWordsetMetadata(create_get_wordset_metadata_request(args.artifactUrn))
print(MessageToJson(response))
Delete a wordset
def delete_wordset(args):
with create_channel(args) as channel:
stub = WordsetStub(channel)
response = stub.DeleteWordset(create_delete_wordset_request(args.artifactUrn))
print(MessageToJson(response))
After configuring the wordset request and calling the client stub, you can access the appropriate Wordset API method through the client stub, sending the request.
Sample Python runtime client
Runtime client overview
This basic Python app, nlu_client.py, requests and receives an NLU interpretation.
import argparse
import sys
import logging
import os
import grpc
import wave
from time import sleep
from google.protobuf.json_format import MessageToJson
from nuance.nlu.v1.runtime_pb2 import *
from nuance.nlu.v1.runtime_pb2_grpc import *
from nuance.nlu.v1.result_pb2 import *
log = logging.getLogger(__name__)
def parse_args():
parser = argparse.ArgumentParser(
prog="nlu_client.py",
usage="%(prog)s [-options]",
add_help=False,
formatter_class=lambda prog: argparse.HelpFormatter(
prog, max_help_position=45, width=100)
)
options = parser.add_argument_group("options")
options.add_argument("-h", "--help", action="help",
help="Show this help message and exit")
options.add_argument("--nmaid", nargs="?", help=argparse.SUPPRESS)
options.add_argument("--token", nargs="?", help=argparse.SUPPRESS)
options.add_argument("-s", "--serverUrl", metavar="url", nargs="?",
help="NLU server URL, default=localhost:8080", default='localhost:8080')
options.add_argument('--modelUrn', nargs="?",
help="NLU Model URN")
options.add_argument('--wordsetUrn', nargs="?",
help="compiled wordset URN")
options.add_argument("--textInput", metavar="file", nargs="?",
help="Text to perform interpretation on")
return parser.parse_args()
def create_channel(args):
channel = None
call_credentials = None
if args.token:
log.debug("Adding CallCredentials with token %s" % args.token)
call_credentials = grpc.access_token_call_credentials(args.token)
log.debug("Creating secure gRPC channel")
channel_credentials = grpc.ssl_channel_credentials()
channel_credentials = grpc.composite_channel_credentials(channel_credentials, call_credentials)
channel = grpc.secure_channel(args.serverUrl, credentials=channel_credentials)
return channel
def construct_interpret_request(args):
# Single intent, plain text logging
params = InterpretationParameters(interpretation_result_type=EnumInterpretationResultType.SINGLE_INTENT, interpretation_input_logging_mode=EnumInterpretationInputLoggingMode.PLAINTEXT)
# Reference the model via the app config
model = ResourceReference(type=EnumResourceType.SEMANTIC_MODEL, uri=args.modelUrn)
# Reference compiled wordset
wordset_reference = ResourceReference(type=EnumResourceType.COMPILED_WORDSET, uri = args.wordsetUrn)
resource = InterpretationResource(external_reference = wordset_reference)
resources = [resource]
# Describe the text to perform interpretation on
input = InterpretationInput(text=args.textInput)
# Build the request
interpret_req = InterpretRequest(parameters=params, model=model, resources = resources, input=input)
return interpret_req
def main():
args = parse_args()
log_level = logging.DEBUG
logging.basicConfig(
format='%(lineno)d %(asctime)s %(levelname)-5s: %(message)s', level=log_level)
with create_channel(args) as channel:
stub = RuntimeStub(channel)
response = stub.Interpret(construct_interpret_request(args))
print(MessageToJson(response))
print("Done")
if __name__ == '__main__':
main()
This section contains a fully-functional sample Python client application consisting of the following files:
- nlu_client.py: The main client application file.
- run-nlu-client.sh: A script file that generates an access token and runs the application.
This Python client requests and receives an NLU interpretation, and also performs these tasks:
- Imports the the contents of the generated client stub files in nuance/nlu/v1/.
- Collects parameters from the command line: server URL, token variable, semantic model, and the text to interpret.
- Sets interpretation parameters such as result type and logging mode.
- Calls NLU on a secure channel (authorized by the token), sending it the parameters, resource, and input text.
- Prints the results to JSON format.
Runtime client requirements
To run this sample app, you need:
- Python 3.6 or later. Use
python3 --versionto check which version you have. - Credentials from Mix (client ID and secret) to generate the access token. See Prerequisites from Mix.
Runtime client procedure
To run this simple application:
Step 1. Download the sample runtime app here and unzip it in a working directory (for example, /home/userA/nlu-runtime-sample-python-app).
Step 2. Download the gRPC .proto files here and unzip the files in the sample app working directory.
Step 3. Navigate to the sample app working directory and install the required dependencies:
$ python3 -m venv env
$ source env/bin/activate
$ pip install --upgrade pip
$ pip install grpcio
$ pip install grpcio-tools
$ mkdir -p google/api
$ curl https://raw.githubusercontent.com/googleapis/googleapis/master/google/api/annotations.proto \
google/api/annotations.proto
$ curl https://raw.githubusercontent.com/googleapis/googleapis/master/google/api/http.proto \
google/api/http.proto
Step 4. Generate the client stubs:
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
--grpc_python_out=./ nuance/nlu/v1/runtime.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/result.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/interpretation-common.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/single-intent-interpretation.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/multi-intent-interpretation.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
--grpc_python_out=./ nuance/nlu/wordset/v1beta1/wordset.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/common/v1beta1/job.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/common/v1beta1/resource.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/rpc/status.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/rpc/status_code.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/rpc/error_details.proto
Step 5. Edit the script run-nlu-client.sh, to add your CLIENT_ID and SECRET. These are your Mix credentials as described in Generate token.
#!/bin/bash
# Remember to change the colon (:) in your CLIENT_ID to code %3A
CLIENT_ID="appID%3A...ENTER MIX CLIENT_ID..."
SECRET="...ENTER MIX SECRET..."
export TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" "https://auth.crt.nuance.co.uk/oauth2/token" \
-d "grant_type=client_credentials" -d "scope=tts nlu asr" \
| python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`"
./nlu_client.py --serverUrl nlu.api.nuance.co.uk:443 --token $TOKEN
--modelUrn "$1" \
--textInput "$2" \
--wordsetUrn "$3"
Step 6. Run the application using the script file, passing it the URN and a text to interpret:
./run-nlu-client.sh modelUrn textInput wordsetUrn
Where:
- modelUrn: Is the URN of the application configuration for the NLU model you created in Mix
- textInput: Is the text to interpret
- wordsetUrn: Is the URN of a wordset (optional)
For example:
$ ./run-nlu-client.sh "urn:nuance-mix:tag:model/bakery/mix.nlu?=language=eng-USA" "I'd like to order a strawberry latte" "mix:tag:wordset:lang/bakery/item_names/eng-USA/mix.nlu"
The NLU engine returns the results:
$ ./run-nlu-client.sh "I'd like to order a strawberry latte"
{
"status": {
"code": 200,
"message": "OK"
},
"result": {
"literal": "I'd like to order a strawberry latte",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "PLACE_ORDER",
"confidence": 0.9961925148963928,
"origin": "STATISTICAL",
"entities": {
"PRODUCT": {
"entities": [
{
"text_range": {
"start_index": 31,
"end_index": 36
},
"confidence": 0.9177429676055908,
"origin": "STATISTICAL",
"string_value": "latte"
}
]
},
"FLAVOR": {
"entities": [
{
"text_range": {
"start_index": 20,
"end_index": 30
},
"confidence": 0.9367110133171082,
"origin": "STATISTICAL",
"string_value": "strawberry"
}
]
}
}
}
}
]
}
}
Sample Python wordsets client
Wordset client overview
This basic Python app, wordset_client.py allows you to compile wordsets, retrieve wordset metadata, and delete wordsets. The operation to perform is selected with a command line argument.
import argparse
import grpc
import json
import logging
from nuance.nlu.wordset.v1beta1.wordset_pb2 import *
from nuance.nlu.wordset.v1beta1.wordset_pb2_grpc import *
from nuance.nlu.common.v1beta1.resource_pb2 import *
from google.protobuf.json_format import MessageToJson
log = logging.getLogger(__name__)
def parse_args():
parser = argparse.ArgumentParser(
prog="client.py",
usage="%(prog)s <command> [-options]",
add_help=False,
formatter_class=lambda prog: argparse.HelpFormatter(
prog, max_help_position=45, width=100)
)
parser.add_argument('command', metavar='command', nargs='?',
choices=['compile', 'get-metadata', 'delete'], default='compile',
help="Command to execute [values: compile, get-metadata, delete] (default: compile)")
options = parser.add_argument_group("options")
options.add_argument("-h", "--help", action="help",
help="Show this help message and exit.")
options.add_argument("--token", nargs="?", help=argparse.SUPPRESS)
options.add_argument("-s", "--serverUrl", metavar="url", nargs="?",
help="NLU server URL, default=localhost:9090.", default='localhost:9090')
options.add_argument("--wordsetFile", type=argparse.FileType("r"), metavar="file",
nargs="?", help="Wordset JSON file.")
options.add_argument("--artifactUrn", nargs="?", metavar="urn", help="Compiled Wordset URN.")
options.add_argument("--modelUrn", nargs="?", metavar="urn", help="NLU Model URN.")
options.add_argument("--metadata", metavar="metadata", nargs="+", default=[],
help="Wordset metadata defined as one or more key:value pairs.")
options.add_argument("--clientData", metavar="clientData", nargs="+", default=[],
help="Client data defined as one or more key=value pairs.")
return parser.parse_args()
def create_channel(args):
channel = None
call_credentials = None
if args.token:
log.debug("Adding CallCredentials with token %s" % args.token)
call_credentials = grpc.access_token_call_credentials(args.token)
log.debug("Creating secure gRPC channel")
channel_credentials = grpc.ssl_channel_credentials()
channel_credentials = grpc.composite_channel_credentials(channel_credentials, call_credentials)
channel = grpc.secure_channel(args.serverUrl, credentials=channel_credentials)
return channel
def create_get_wordset_metadata_request(artifactUrn):
artifact_reference = ResourceReference(uri=artifactUrn)
return GetWordsetMetadataRequest(artifact_reference=artifact_reference)
def create_delete_wordset_request(artifactUrn):
artifact_reference = ResourceReference(uri=artifactUrn)
return DeleteWordsetRequest(artifact_reference=artifact_reference)
def list_to_dict(list, separator = ':'):
return dict(entry.split(separator) for entry in list)
def create_compile_wordset_request(args):
target_artifact_reference = ResourceReference(uri=args.artifactUrn)
companion_artifact_reference = ResourceReference(uri=args.modelUrn)
wordset = json.dumps(json.load(args.wordsetFile))
return CompileWordsetRequest(
target_artifact_reference=target_artifact_reference,
companion_artifact_reference=companion_artifact_reference,
wordset=wordset,
metadata=list_to_dict(args.metadata),
client_data=list_to_dict(args.clientData))
def compile_wordset(args):
with create_channel(args) as channel:
stub = WordsetStub(channel)
compiled_wordset_request = create_compile_wordset_request(args)
for message in stub.CompileWordsetAndWatch(compiled_wordset_request):
print(MessageToJson(message))
def get_wordset_metadata(args):
with create_channel(args) as channel:
stub = WordsetStub(channel)
response = stub.GetWordsetMetadata(create_get_wordset_metadata_request(args.artifactUrn))
print(MessageToJson(response))
def delete_wordset(args):
with create_channel(args) as channel:
stub = WordsetStub(channel)
response = stub.DeleteWordset(create_delete_wordset_request(args.artifactUrn))
print(MessageToJson(response))
def main():
args = parse_args()
log_level = logging.DEBUG
logging.basicConfig(
format='%(lineno)d %(asctime)s %(levelname)-5s: %(message)s', level=log_level)
switcher = {
'compile' : compile_wordset,
'get-metadata' : get_wordset_metadata,
'delete' : delete_wordset
}
switcher.get(args.command)(args)
print("Done")
if __name__ == '__main__':
main()
This section contains a fully-functional sample Python client application consisting of the following files:
- wordset_client.py: The main client application file.
wordset-nlu-client.sh: A script file that generates an access token and runs the application. This sample Python wordsets app performs the following tasks:
Imports the the contents of the generated client stub files.
Collects parameters from the command line: wordset operation to perform (by default, compile), the server URL, a token variable, a wordset file, URN for a semantic model, URN for the wordset, and wordset metadata.
Sets parameters such as logging mode.
Calls NLUaaS Wordset service on a secure channel (authorized by the token), sending the specified request.
Prints the results to JSON format.
This sample Python wordsets app performs the following tasks:
- Imports the the contents of the generated client stub files.
- Collects parameters from the command line: wordset operation to perform, the server URL, a token variable, URN for a semantic model, URN for the wordset, wordset file, and wordset metadata.
- Sets parameters such as logging mode.
- Calls NLUaaS Wordset service on a secure channel (authorized by the token), sending the specified request.
- Prints the results to JSON format.
Wordset client requirements
To run this sample app, you need:
- Python 3.6 or later. Use
python3 --versionto check which version you have. - Credentials from Mix (client ID and secret) to generate the access token. See Prerequisites from Mix.
Wordset client procedure
Note: Steps 2-4 are the same as for the runtime client, so if you have already carried this out for the runtime client, you can skip.
To run this simple application:
Step 1. Download the sample app here and unzip it in a working directory (for example, /home/userA/nlu-wordset-sample-python-app).
Step 2. Download the gRPC .proto files here and unzip the files in the sample app working directory.
Step 3. Navigate to the sample app working directory and install the required dependencies:
$ python3 -m venv env
$ source env/bin/activate
$ pip install --upgrade pip
$ pip install grpcio
$ pip install grpcio-tools
$ mkdir -p google/api
$ curl https://raw.githubusercontent.com/googleapis/googleapis/master/google/api/annotations.proto \
google/api/annotations.proto
$ curl https://raw.githubusercontent.com/googleapis/googleapis/master/google/api/http.proto \
google/api/http.proto
Step 4. (If not done previously) Generate the client stubs:
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
--grpc_python_out=./ nuance/nlu/v1/runtime.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/result.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/interpretation-common.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/single-intent-interpretation.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/v1/multi-intent-interpretation.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
--grpc_python_out=./ nuance/nlu/wordset/v1beta1/wordset.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/common/v1beta1/job.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/nlu/common/v1beta1/resource.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/rpc/status.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/rpc/status_code.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ \
nuance/rpc/error_details.proto
Step 5. Edit the script wordset-nlu-client.sh, to add your CLIENT_ID and SECRET. These are your Mix credentials as described in Generate token.
#!/bin/bash
# Remember to change the colon (:) in your CLIENT_ID to code %3A
CLIENT_ID="appID%3A...ENTER MIX CLIENT_ID..."
SECRET="...ENTER MIX SECRET..."
export TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" "https://auth.crt.nuance.co.uk/oauth2/token" \
-d "grant_type=client_credentials" -d "scope=tts nlu asr nlu.wordset" \
| python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`"
python ./wordset_client.py compile \
--serverUrl nlu.api.nuance.co.uk:443 --token $TOKEN \
--wordsetFile "$1" \
--artifactUrn "$2" \
--modelUrn "$3" \
--metadata "$4"
Step 6. Run the application using the script file, passing it:
- The wordset file name
- The URN to use for the compiled wordset
- The NLU model URN
- (Optionally) Wordset metadata:
./wordset-nlu-client.sh wordsetFile artifactUrn modelUrn wordsetUrn
Where:
- wordsetFile: Is the wordset json file name
- artifactUrn: Is the URN you want to use for the compiled wordset
- modelUrn: Is the URN of the application configuration for the NLU model you created in Mix
- metadata: (Optional) Is metadata about the wordset
For example:
$ ./wordset-nlu-client.sh "wordset.json" "mix:tag:wordset:lang/bakery/item_names/eng-USA/mix.nlu" "urn:nuance-mix:tag:model/bakery/mix.nlu?=language=eng-USA"
Here is an example of the script output:
55 2021-03-30 14:18:18,855 DEBUG: Adding CallCredentials with token $TOKEN
59 2021-03-30 14:18:18,857 DEBUG: Creating secure gRPC channel
{
"job_status_update": {
"status": "JOB_STATUS_PROCESSING"
},
"request_status": {
"status_code": "OK"
}
}
{
"job_status_update": {
"status": "JOB_STATUS_COMPLETE"
},
"request_status": {
"status_code": "OK"
}
}
Reference topics
This section provides more information about topics in the gRPC API.
Status messages and codes
gRPC includes error and exception handling facilities. Use these gRPC features to confirm the success or failure of a request.
NLU also returns a status message confirming the outcome of an InterpretRequest call. The status field in InterpretResponse contains an HTTP status code, a brief description of this status, and, possibly, a longer description.
An HTTP status code of 200 means that NLU successfully interpreted the input. Values in the 400 range indicate an error in the request that your client app sent. Values in the 500 range indicate an internal error with NLUaaS.
| Code | Indicates |
|---|---|
| 200 | Success |
| 400 | Bad request. Your client app sent a malformed or unsupported request. |
| 401 | Unauthorized. Your client has not authorized properly. |
| 403 | Forbidden. Permission was denied. |
| 404 | Not found. A resource, such as a model or word list, does not exist or could not be accessed. |
| 415 | Unsupported resource type. |
| 500-511 | Error: Internal error. |
Wordsets
A wordset is a collection of words and short phrases that extends vocabulary by providing additional values for dynamic list entities in a model. For example, a wordset might provide the names in a user’s contact list or local place names. Like models, wordsets are declared with InterpretRequest - resources.
Defining wordsets
The wordset is defined in JSON format as one or more arrays. Each array is named after a dynamic list entity defined within a semantic model. Wordsets allow you to add values and literals to such entities at runtime.
For example, you might have an entity, CONTACTS, containing personal names, or CITY, with place names used by the application. The wordset adds to the existing terms in the entity, but applies only to the current session. The terms in the wordset are not added permanently to the entity.
All entities must be defined in the semantic model, which are loaded and activated along with the wordset.
The wordset includes additional values for one or more entities. The syntax is:
{
"entity-1" : [
{ "canonical": "value"
"literal": "written form"
},
{ "canonical": "value"
"literal": "written form"
},
...
],
"entity-n": [ ... ]
}
Syntax
| Field | Type | Description |
|---|---|---|
| entity | String | The name of a dynamic list entity defined in a model. The name is case-sensitive. Consult the model for entity names. |
| canonical | String | (Optional) The canonical value for the entity to be returned by interpretation by NLU. If not provided, the literal is used. |
| literal | String | A written form by which a user could realistically refer to the value. |
For ASR purposes, wordsets can also include a field "spoken" to indicate pronunciations of the value. If you happen to reuse the same wordset for both ASR and NLU, this field is ignored by NLU.
You can provide the wordset either inline in the request or reference a compiled wordset using its URN in the Mix environment.
Inline wordsets
Wordset defined inline
# Define semantic model
semantic_model = ResourceReference(
type = 'SEMANTIC_MODEL',
uri = 'urn:nuance-mix:tag:model/bank-app/mix.nlu?=language=eng-USA'
)
# Define the wordset inline
payees_wordset = InterpretationResource(
inline_wordset = '{"PAYEE":[{"canonical": AMEX","literal":"amex"},{"canonical":"AMEX","literal":"american express"},{"canonical":"VISA","literal":"visa"},{"canonical":"SOCALGAS","literal":"southern california gas"},{"canonical":"SOCALGAS","literal":"southern california gas company"},{"canonical":"SOCALGAS","literal":"the gas company"},{"canonical":"SOCALGAS","literal":"socal gas"}]}')
# Include the semantic model and wordset in InterpretRequest
interpret_request = InterpretRequest(
parameters = InterpretationParameters(...),
model = semantic_model
resources = [ payees_wordset ]
)
Wordset read from a local file using Python function
# Define semantic model
semantic_model = ResourceReference(
type = 'SEMANTIC_MODEL',
uri = 'urn:nuance-mix:tag:model/bank-app/mix.nlu?=language=eng-USA'
)
# Read wordset from local file
payees_wordset_content = None
with open('payees-wordset.json', 'r') as f:
payees_wordset_content = f.read()
payees_wordset = InterpretationResource(
inline_wordset = payees_wordset_content)
# Include the semantic model and wordset in InterpretRequest
interpret_request = InterpretRequest(
parameters = InterpretationParameters(...),
model = semantic_model
resources = [ payees_wordset ]
)
For inline wordsets, the contents are provided as a string as part of the request object. You can either include the string literal directly in the request or read the string in from a local file programmatically.
The example wordset below extends a PAYEE entity in the model with additional payees.
{
"PAYEE" : [
{
"canonical" : "AMEX",
"literal" : "amex"
},
{
"canonical" : "AMEX",
"literal" : "american express"
},
{
"canonical" : "VISA",
"literal" : "visa"
},
{
"canonical" : "SOCALGAS",
"literal" : "southern california gas"
},
{
"canonical" : "SOCALGAS",
"literal" : "southern california gas company"
},
{
"canonical" : "SOCALGAS",
"literal" : "the gas company"
},
{
"canonical" : "SOCALGAS",
"literal" : "socal gas"
},
…
]
}
To use a source wordset, specify it as inline_wordset in InterpretationResource:
You may include the JSON definition directly in the
inline_wordsetfield, compressed (without spaces) and enclosed in single quotation marks, as shown in the first example at the right.You may instead store the source wordset in a local JSON file and read the file (payees-wordset.json) with a programming-language function, as shown in the second example.
Compiled wordsets
Compiled wordset
# Define semantic model as before
semantic_model = ResourceReference(
type = 'SEMANTIC_MODEL',
uri = 'urn:nuance-mix:tag:model/bank-app/mix.nlu?=language=eng-USA'
)
# Define a compiled wordset (here its context is the same as the semantic model)
payees_compiled_ws = InterpretationResource(
external_reference = ResourceReference(
type = 'COMPILED_WORDSET',
uri = 'urn:nuance-mix:tag:wordset:lang/bank-app/payees-compiled-ws/eng-USA/mix.nlu')
)
# Include the semantic model and wordset in InterpretRequest
interpret_request = InterpretRequest(
parameters = InterpretationParameters(...),
model = semantic_model
resources = [ payees_compiled_ws ]
)
Alternatively, you may reference a compiled wordset that was created with the Wordset API. To use a compiled wordset, specify it in ResourceReference as COMPILED_WORDSET and provide its URN in the Mix environment.
This wordset extends the PAYEE entity in the model with travel locations.
Inline or compiled?
Wordsets can be brought in to aid in interpretation in one of two ways depending on the size of the wordset:
- Small wordsets (less than 100 terms in an entity): You can include these inline along with each interpretation request at runtime. The wordset is compiled and applied as a resource.
- Larger wordsets: You can compile these once ahead of time using the NLUaaS Wordset API. The compiled wordset is stored in Mix and can then be referenced and loaded as an external interpretation resource at runtime. This improves latency significantly for large wordsets.
If you are unsure of which approach to take, test the latency when using wordsets inline.
Wordset URNs
To compile a wordset, the following need to be provided:
- A URN for the wordset. This is the location in URN format where the compiled wordset will be created. You will use the URN afterward to reference the wordset to assist in interpretation.
- A URN for the companion NLU semantic model. This is the model containing the entity that the wordset extends.
- The wordset JSON source
Wordsets can be either:
- Application-level: Wordsets that are applicable to any user of the application. For example, a list of names of employees in a company
- User-level: Wordsets that are applicable to a single user. For example, a list of contact names for a particular user
The URN for the wordset needs to have one of the following structures, depending on the level of the wordset:
- Application-level wordset: urn:nuance-mix:tag:wordset:lang/contextTag/resourceName/lang/mix.nlu
- User-level wordset: urn:nuance-mix:tag:wordset:lang/contextTag/resourceName/lang/mix.nlu?=user_id=userId
Where:
- contextTag is an application context tag from Mix
- resourceName is a name for the wordset
- lang is the six-letter language and country code for which the wordset applies. For example,
eng-USA. - userId is a unique identifier for the user
Once the wordset is compiled, it is stored on Mix and can be referenced at runtime by a client application using the same model and wordset URNs.
Scope of compiled wordsets
Wordsets are specific to a Mix App ID and can be used by any Mix applications under the same App ID.
The context tag used for the wordset does not have to match the context tag of the companion model but it is good practice to do so for easier wordset management.
The wordset must be compatible with the companion model. The companion model needs to contain the dynamic list entity that the wordset relates to.
Note that while the Mix ASRaaS provides a similar API for wordsets, wordsets are nevertheless compiled and stored separately for NLUaaS and ASRaaS. If your application uses both services and requires large wordsets for both, the compilation step must be done for each service.
Wordset lifecycle
Wordsets are available for 28 days after compilation, after which they will automatically be deleted and will need to be compiled again.
After a wordset is compiled, the compiled wordset can later be updated.
Compiling a wordset using an existing wordset URN will replace the existing wordset with the newer version if:
- The wordset payload is different
- The time to live (TTL) for the wordset is almost expired, meaning it is nearing the end of its 28-day lifecycle
- The model URN is different
- The model has been updated with new content or its underlying data pack has been updated to a new version
Otherwise, the wordset compilation request may return a status ALREADY_EXISTS. In this case, the wordset remains usable at runtime.
Wordsets can also be manually deleted if no longer needed. Once deleted, a wordset is completely removed and can not be restored.
A compiled wordset can only be accessed at runtime within the AppId under which it was compiled. It must be used with a compatible model, ideally the one used at compilation time.
If an NLUaaS runtime request references an incompatible or missing wordset, the request will still succeed, but an error message will be included to indicate that the wordset was incompatible or not found.
For more details about managing compiled wordsets, see the Wordset API documentation.
Wordset metadata
Wordsets have associated metadata. Some metadata keys are available by default. Optionally, you can provide a list of custom metadata to associate with the compiled wordset. One or more metadata entries can be provided as key-value pairs along with the CompileWordsetRequest.
Both default and custom metadata can be retrieved using the Wordset API.
Note: key names must be lower case.
Interpretation results: Intents
This input exactly matches a training sentence for the ASK_JOB intent (note "origin": GRAMMAR). An alternative intent is proposed but with much lower confidence.
"result": {
"literal": "Do you have any openings for a pastry chef ?",
"formatted_literal": "Do you have any openings for a pastry chef ?",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "ASK_JOB",
"confidence": 1.0,
"origin": "GRAMMAR"
}
},
{
"single_intent_interpretation": {
"intent": "PLACE_ORDER",
"confidence": 0.00010213560017291456,
"origin": "STATISTICAL"
}
}
]
}
This input is similar to the PLACE_ORDER training sentences (note "origin": STATISTICAL)
"result": {
"literal": "I'd like to make an order please",
"formatted_literal": "I'd like to make an order please",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "PLACE_ORDER",
"confidence": 0.9779196381568909,
"origin": "STATISTICAL"
}
}
]
}
This result returns the intent PLACE_ORDER along with several entities. See Interpretation results: Entities for more results with entities
"result": {
"literal": "I'd like to order a blueberry pie",
"formatted_literal": "I'd like to order a blueberry pie",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "PLACE_ORDER",
"confidence": 0.9913266897201538,
"origin": "STATISTICAL",
"entities": {
"FLAVOR": {
"entities": [
{
"text_range": {
"start_index": 20,
"end_index": 29
},
"formatted_text_range": {
"start_index": 20,
"end_index": 29
},
"confidence": 0.8997141718864441,
"origin": "STATISTICAL",
"string_value": "blueberry",
"literal": "blueberry",
"formatted_literal": "blueberry"
}
]
},
"PRODUCT": {
"entities": [
{
"text_range": {
"start_index": 30,
"end_index": 33
},
"formatted_text_range": {
"start_index": 30,
"end_index": 33
},
"confidence": 0.8770073652267456,
"origin": "STATISTICAL",
"string_value": "pie",
"literal": "pie",
"formatted_literal": "pie"
}
]
}
}
}
}
]
}
NLU returns two alternative intents for this input: GET_INFO or PLACE_ORDER, both with medium confidence
"result": {
"literal": "Can I see a price list and place an order",
"formatted_literal":"Can I see a price list and place an order"
"interpretations": [
{
"single_intent_interpretation": {
"intent": "GET_INFO",
"confidence": 0.563047468662262,
"origin": "STATISTICAL"
}
},
{
"single_intent_interpretation": {
"intent": "PLACE_ORDER",
"confidence": 0.40654945373535156,
"origin": "STATISTICAL"
}
}
]
}
Multi-intent interpretation currently returns information similar to single-intent
"result": {
"literal": "Can I see a price list and place an order",
"formatted_literal": "Can I see a price list and place an order",
"interpretations": [
{
"multi_intent_intepretation": {
"root": {
"intent": {
"name": "GET_INFO",
"text_range": {
"end_index": 41
},
"formatted_text_range": {
"end_index": 41
},
"confidence": 0.563047468662262,
"origin": "STATISTICAL"
}
}
}
},
{
"multi_intent_intepretation": {
"root": {
"intent": {
"name": "PLACE_ORDER",
"text_range": {
"end_index": 41
},
"formatted_text_range": {
"end_index": 41
},
"confidence": 0.40654945373535156,
"origin": "STATISTICAL"
}
}
}
}
]
}
The results returned by NLU include one or more candidate intents that identify the underlying meaning of the user's input. (They can also include entities and values, described in Interpretation results: Entities.) You may request either single-intent interpretation or multi-intent interpretation with InterpretationParameters - interpretation_result_type: SINGLE_INTENT or MULTI_INTENT
Single-intent interpretation means that NLU returns one intent for the user's input: the intent that best describes the user's underlying meaning. NLU may return several candidate intents, but they are listed as alternatives rather than as complementary intents.
Multi-intent interpretation requires that your semantic model support this type of interpretation. Currently you cannot create these models in Mix, so the feature is not fully supported, but you may still request multi-interpretation without error. Like single-intent results, multi-intent results contain one best candidate for the user's input, optionally with alternatives.
True multi-intent results show all the intents contained within the user's input. These results will be available in an upcoming release.
Interpretation results: Entities
List: The FLAVOR and PRODUCT entities identify what the user wants to order
"result": {
"literal": "I'd like to order a butterscotch cake",
"formatted_literal": "I'd like to order a butterscotch cake",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "PLACE_ORDER",
"confidence": 0.9917341470718384,
"origin": "STATISTICAL",
"entities": {
"FLAVOR": {
"entities": [
{
"text_range": {
"start_index": 20,
"end_index": 32
},
"formatted_text_range": {
"start_index": 20,
"end_index": 32
},
"confidence": 0.9559149146080017,
"origin": "STATISTICAL",
"string_value": "caramel"
"literal": "caramel",
"formatted_literal": "caramel",
}
]
},
"PRODUCT": {
"entities": [
{
"text_range": {
"start_index": 33,
"end_index": 37
},
"formatted_text_range": {
"start_index": 33,
"end_index": 37
},
"confidence": 0.9386003613471985,
"origin": "STATISTICAL",
"string_value": "cake",
"literal": "cake",
"formatted_literal": "cake"
}
]
}
}
}
}
]
}
Freeform: The MESSAGE entity matches anything prefixed with "Call someone" or "Ask someone" or "Send this message to someone." An additional list entity, NAMES, captures the "someone."
"result": {
"literal": "Ask Jenny When should we arrive",
"formatted_literal": "Ask Jenny When should we arrive",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "ASK_RANDOM",
"confidence": 1.0,
"origin": "GRAMMAR",
"entities": {
"NAMES": {
"entities": [
{
"text_range": {
"start_index": 4,
"end_index": 9
},
"formatted_text_range": {
"start_index": 4,
"end_index": 9
},
"confidence": 1.0,
"origin": "GRAMMAR",
"string_value": "Jenny",
"literal": "Jenny",
"formatted_literal": "Jenny"
}
]
},
"MESSAGE": {
"entities": [
{
"text_range": {
"start_index": 10,
"end_index": 31
},
"formatted_text_range": {
"start_index": 10,
"end_index": 31
},
"confidence": 1.0,
"origin": "GRAMMAR",
"string_value": "",
"literal": "when should we arrive",
"formatted_literal": "when should we arrive"
}
]
}
}
}
}
]
}
"result": {
"literal": "Send this message to Chris Can you pick me up from the five forty train",
"formatted_literal": "Send this message to Chris Can you pick me up from the 5:40 train",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "ASK_RANDOM",
"confidence": 1.0,
"origin": "GRAMMAR",
"entities": {
"MESSAGE": {
"entities": [
{
"text_range": {
"start_index": 27,
"end_index": 65
},
"formatted_text_range": {
"start_index": 27,
"end_index": 59
},
"confidence": 1.0,
"origin": "GRAMMAR",
"string_value": "",
"literal": "can you pick me up from the five forty train",
"formatted_literal": "can you pick me up from the 5:40 train"
}
]
},
"NAMES": {
"entities": [
{
"text_range": {
"start_index": 21,
"end_index": 26
},
"formatted_text_range": {
"start_index": 21,
"end_index": 26
},
"confidence": 1.0,
"origin": "GRAMMAR",
"string_value": "Chris",
"literal": "Chris",
"formatted_literal": "Chris"
}
]
}
}
}
}
]
}
Relationship: DATE is an isA entity that wraps nuance_CALENDARX
"result": {
"literal": "I want to pay my Visa bill on February twenty eight",
"formatted_literal": "I want to pay my Visa bill on February 28",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "PAY_BILL",
"confidence": 1.0,
"origin": "GRAMMAR",
"entities": {
"DATE": {
"entities": [
{
"text_range": {
"start_index": 30,
"end_index": 51
},
"formatted_text_range": {
"start_index": 30,
"end_index": 41
},
"confidence": 1.0,
"origin": "GRAMMAR",
"entities": {
"nuance_CALENDARX": {
"entities": [
{
"text_range": {
"start_index": 30,
"end_index": 51
},
"formatted_text_range": {
"start_index": 30,
"end_index": 41
},
"confidence": 1.0,
"origin": "GRAMMAR",
"struct_value": {
"nuance_CALENDAR": {
"nuance_DATE": {
"nuance_DATE_ABS": {
"nuance_MONTH": 2.0,
"nuance_DAY": 28.0
}
}
}
}
}
]
}
}
}
]
},
"BILL_TYPE": {
"entities": [
{
"text_range": {
"start_index": 17,
"end_index": 21
},
"formatted_text_range": {
"start_index": 17,
"end_index": 21
},
"confidence": 1.0,
"origin": "GRAMMAR",
"string_value": "Visa",
"literal": "Visa",
"formatted_literal": "Visa"
}
]
}
}
}
}
]
}
nuance_CALENDARX is a hasA entity containing several date and time entities
"result": {
"literal": "I want to pay my AMEX bill on February twenty eight",
"formatted_literal": "I want to pay my AMEX bill on February 28",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "PAY_BILL",
"confidence": 1.0,
"origin": "GRAMMAR",
"entities": {
"nuance_CALENDARX": {
"entities": [
{
"text_range": {
"start_index": 30,
"end_index": 51
},
"formatted_text_range": {
"start_index": 30,
"end_index": 41
},
"confidence": 1.0,
"origin": "GRAMMAR",
"struct_value": {
"nuance_CALENDAR": {
"nuance_DATE": {
"nuance_DATE_ABS": {
"nuance_MONTH": 2.0,
"nuance_DAY": 28.0
}
}
}
}
}
]
},
"BILL_TYPE": {
"entities": [
{
"text_range": {
"start_index": 17,
"end_index": 21
},
"formatted_text_range": {
"start_index": 17,
"end_index": 21
},
"confidence": 1.0,
"origin": "GRAMMAR",
"string_value": "American Express",
"literal": "AMEX",
"formatted_literal": "AMEX"
}
]
}
}
}
}
]
}
nuance_AMOUNT is another hasA entity containing multiple entities
"result": {
"literal": "i'd like to pay six hundred and twenty five dollars on my hydro bill",
"formatted_literal": "i'd like to pay $625 on my hydro bill"
"interpretations": [
{
"single_intent_interpretation": {
"intent": "PAY_BILL",
"confidence": 1.0,
"origin": "GRAMMAR",
"entities": {
"BILL_TYPE": {
"entities": [
{
"text_range": {
"start_index": 58,
"end_index": 63
},
"formatted_text_range": {
"start_index": 27,
"end_index": 32
},
"confidence": 1.0,
"origin": "GRAMMAR",
"string_value": "Hydro"
"literal": "Hydro",
"formatted_literal": "Hydro"
}
]
},
"nuance_AMOUNT": {
"entities": [
{
"text_range": {
"start_index": 16,
"end_index": 51
},
"formatted_text_range": {
"start_index": 16,
"end_index": 20
},
"confidence": 1.0,
"origin": "GRAMMAR",
"struct_value": {
"nuance_UNIT": "USD",
"nuance_NUMBER": 625.0
}
}
]
}
}
}
}
]
}
NLU results may also include individual words and phrases in the user's input, mapped to entities and values. The results differ depending on the type of entity that is interpreted. Entity creation and annotation is done in Mix.nlu or in Mix.dialog, where the entity types include: List, Freeform, and Relationship (isA and/or hasA).
List entity
A list entity is an entity with named values. For example, FLAVOR is a list entity that might contain values such as caramel, blueberry, strawberry, chocolate, and so on. Or BILL_TYPE might contain values such as Visa, American Express, Telephone, and Hydro.
Each value has one or more user literals, or ways that users might express this canonical value. For example, the FLAVOR entity matches sentences containing phrases such as:
- "I'd like to order a butterscotch cake" (butterscotch is a literal meaning caramel)
- "I want a dozen fudge cupcakes." (fudge is a literal meaning chocolate)
And the BILL_TYPE entity matches sentences such as:
- "I want to pay my phone bill" (phone bill is a literal meaning Telephone)
- "Can I pay down my AMEX for this month." (AMEX is a literal meaning American Express)
Freeform entity
A freeform entity has values that are only vaguely defined. Freeform entities can match lengthy user input, but they do not give precise information about the contents of the input. For example, MESSAGE is a freeform entity that occurs after keywords in the user input such as:
"Call Fred to say..."
"Ask Jenny..."
"Send a message to Chris."
Relationship entity
Relationship entities are isA and/or hasA entities.
An isA entity is a simple wrapping of another entity. For example, DATE is a relationship entity with an isA connection to nuance_CALENDARX, a Nuance predefined entity.
A hasA entity includes one or more entities. Many of the Nuance predefined entities (nuance_CALENDARX, nuance_AMOUNT, and so on) are hasA entities, meaning they are collections of other entities.
Interpretation results: Confidence
Interpretation results report confidence levels for both intent and entity interpretations.
Confidence levels can range from 0.0 to 1.0, and give an estimate of the probability that the candidate interpretation is correct.
Exact matches
The highest confidence levels will be for input that is detected as an exact match to the structure and entities of one of the training samples for one of the intents. For example, suppose you have defined an intent named CHECK_ACCOUNT_BALANCE, and that this intent has a training sample "Check my [ACCOUNT_TYPE]savings[/] account balance." Suppose as well that the entity ACCOUNT_TYPE has other values defined—"checking," "mortgage," "joint," and so on. A user input of "Check my mortgage account balance" would come back as an exact match.
Exact matches for text input come back with a confidence = 1.0 and an origin = "GRAMMAR." Exact matches for recognition text coming from an ASR input will also come back with origin = "GRAMMAR" and with a confidence that is high, but somewhat less than 1.0. The reduced confidence reflects the statistical uncertainty inherent to the speech recognition process.
Statistical matches
The other type of match is a statistical match. A statistical match will always have a confidence less than 1.0, and will be indicated with origin = "STATISTICAL". If multiple statistical intent-level matches come back for a user input, the individual confidence values will be normalized so that the confidence values for the interpretation intents add up to 1.0.
For multiple exact matches, this normalization will not take place, whether the match comes from ASR input or text input.
Interpretation results: Literals
Interpretation results, whether single-intent or multi-intent, include string literals at different levels corresponding to the full user input used for interpretation as well as the meaningful portions thereof, for example, the text corresponding to a detected SingleIntentEntity. There are two types of literals that can be returned, literal and formatted_literal.
literal
For literals returned with field name literal, the contents depend on the origin of the user input.
For text input, this just contains the raw input text.
For input coming from ASR results, the literal is a concatenation of audio tokens, separated by spaces, in minimally formatted text format.
For example, "Call five one four nine zero four seven eight zero zero," or "Pay five hundred dollars to my phone bill."
formatted_literal
The field formatted_literal is a formatted version of the literal for user inputs coming from ASR results.
For inputs from ASR results, this field gives a text string representing the ASR result, but with formatted text that attempts to render the text as it would be written in text input for special types of content such as:
- Numbers and digits
- Addresses
- Dates
- Times
- Prices and currencies
- Common units of measure
- URLs and email addresses
- Phone numbers
For example, a formatted_literal could look like "Call (514) 904-7800" or "Pay $500 to my phone bill."
In the case of text inputs, the contents of this field will be identical to those of literal.
The formatting performed depends on the language.
For more information on formatted text, see Formatted text in the ASRaaS documentation.
Defaults
The proto files provide the following default values for InterpretRequest sent to NLU. Mandatory fields are in bold.
| Fields in InterpretRequest | Default value |
|---|---|
| InterpretRequest | |
| parameters | |
| interpretation_result_type | SINGLE_INTENT |
| interpretation_input_logging_mode | PLAINTEXT |
| post_processing_script_parameters | Blank |
| max_interpretations | 0: Use the configured setting in the NLU instance. |
| model | |
| type | UNDEFINED_RESOURCE_TYPE: NLU will use the resource provided by the content server. |
| uri | Mandatory |
| request_timeout_ms | 0: Use the configured setting in the NLU instance. |
| headers | Blank |
| resources | |
| inline_wordset |
Blank |
| client_data | Blank |
| user_id | Blank |
| input | Mandatory |
Runtime gRPC API
NLU as a Service provides these protocol buffer (.proto) files to define the Runtime NLU service for gRPC. These files contain the building blocks for the runtime of your NLU applications:
- runtime.proto defines the main services and messages to request interpretation.
- result.proto defines the result.
- multi-intent-interpretation.proto defines multi-intent interpretations.
- single-intent-interpretation.proto defines single-intent interpretations.
- interpretation-common.proto defines additional items.
Once you have transformed the proto files into functions and classes in your programming language using gRPC tools, you can call these functions from your client application to start interpreting plain text or results from ASR as a Service.
See Client app development for a samples using Python, Go, and Java. For other languages, consult the gRPC and Protocol Buffer documentation:
Proto file structure
The proto files define an RPC service with an Interpret method containing an InterpretRequest and InterpretResponse. Details about each component are referenced by name within the proto file.
This is the structure of InterpretRequest:

And this shows InterpretResponse:
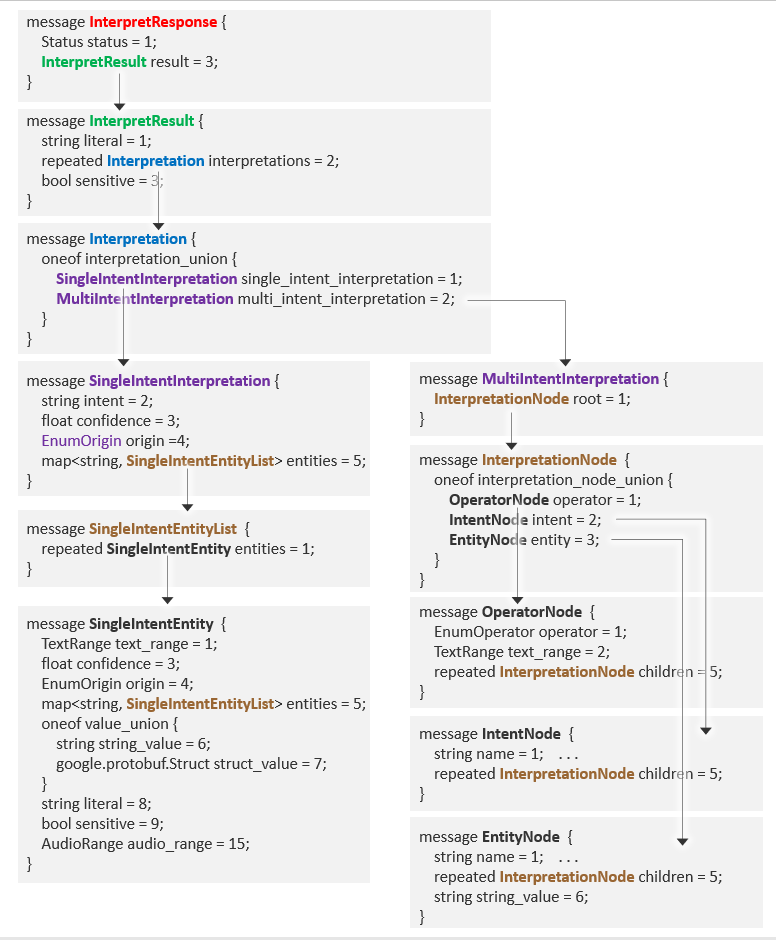
Runtime service
Runtime interpretation service. Use the Interpret method to request an interpretation.
| Name | Request Type | Response Type | Description |
|---|---|---|---|
| Interpret | InterpretRequest | InterpretResponse | Starts an interpretation request and returns a response. |
InterpretRequest
InterpretRequest example
interpret_req = InterpretRequest(
parameters=params,
model=model,
input=input)
The input to interpret, with parameters, model, extra resources, and client tags to customize the interpretation. Included in Runtime service.
| Field | Type | Description |
|---|---|---|
| parameters | InterpretationParameters | Parameters for the interpretation. |
| model | ResourceReference | Mandatory. Semantic model to perform the interpretation. |
| resources | InterpretationResource | Repeated. Resources to customize the interpretation. |
| client_data | string,string | Key-value pairs to log. |
| user_id | string | Identifies a particular user within an application. |
| input | InterpretationInput | Mandatory. Input to interpret. |
This message includes:
InterpretRequest
parameters InterpretationParameters
interpretation_result_type (EnumInterpretationResultType)
interpretation_input_logging_mode (EnumInterpretationInputLoggingMode)
post_processing_script_parameters
max_interpretations
model (ResourceReference)
resources (InterpretationResource)
client_data
user_id
input (InterpretationInput)
InterpretationParameters
InterpretationParameters example
params = InterpretationParameters(
interpretation_result_type=EnumInterpretationResultType.SINGLE_INTENT,
interpretation_input_logging_mode=EnumInterpretationInputLoggingMode.PLAINTEXT)
Optional parameters controlling the interpretation. Included in InterpretRequest.
| Field | Type | Description |
|---|---|---|
| interpretation_result_type | EnumInterpretation ResultType | Format of interpretation result. Default is SINGLE_INTENT. |
| interpretation_input_logging_mode | EnumInterpretation InputLoggingMode | Format for input in the call logs. Default is PLAINTEXT. |
| max_interpretations | uint32 | Maximum interpretations for the result. Default is 0 for the NLU server's configured setting. |
This message includes:
InterpretRequest
InterpretationParameters
interpretation_result_type (EnumInterpretationResultType)
interpretation_input_logging_mode (EnumInterpretationInputLoggingMode)
max_interpretations
EnumInterpretationResultType
Format of interpretations result. Included in InterpretationParameters.
| Name | Number | Description |
|---|---|---|
| UNKNOWN | 0 | Default. Same as SINGLE_INTENT. |
| SINGLE_INTENT | 1 | Always return a single-intent interpretation. |
| MULTI_INTENT | 2 | Always return multi-intent interpretation. |
EnumInterpretationInputLoggingMode
Format for input in the diagnostic logs. Included in InterpretationParameters.
| Name | Number | Description |
|---|---|---|
| PLAINTEXT | 0 | Default. Log the literal text of the input. |
| SUPPRESSED | 9 | Input is replaced with "value suppressed." |
ResourceReference
ResourceReference example
options.add_argument('--modelUrn', nargs="?",
help="NLU Model URN")
. . .
# Reference the model via the app config
model = ResourceReference(
type=EnumResourceType.SEMANTIC_MODEL,
uri=args.modelUrn)
Parameters to fetch an external resource. Included in InterpretRequest and InterpretationResource.
| Field | Type | Description |
|---|---|---|
| type | EnumResourceType | Resource type. |
| uri | string | URN for the resource. |
| request_timeout_ms | uint32 | Time, in ms, to wait for a response from the hosting server. Default is 0 for the NLU server's configured setting. |
| headers | string,string | Map of headers to transmit to the server hosting the resource. May include max_age, max_stale, max_fresh, cookies. |
This message includes:
InterpretRequest | InterpretationResource
ResourceReference
type (EnumResourceType)
uri
request_timeout_ms
headers
EnumResourceType
Specifies a semantic model or wordset. Included in ResourceReference. Use the default, UNDEFINED_RESOURCE_TYPE, to determine the type from the content-type header returned by the resource's server.
| Name | Number | Description |
|---|---|---|
| UNDEFINED_RESOURCE_TYPE | 0 | Default. Use the content-type header from the resource's server to determine the type. |
| SEMANTIC_MODEL | 1 | A semantic model from Mix.nlu. |
| WORDSET | 2 | Currently unsupported. Use InterpretationResource - inline_wordset. |
| COMPILED_WORDSET | 3 | A compiled wordset associated to a specific semantic model. |
InterpretationResource
A resource to customize the interpretation. Included in InterpretRequest.
| Field | Type | Description |
|---|---|---|
| external_reference | ResourceReference | External resource. |
| inline_wordset | string | Inline wordset, in JSON. See Wordsets. |
This message includes:
InterpretRequest
InterpretationResource
external_reference (ResourceReference)
inline_wordset
InterpretationInput
InterpretationInput example
def parse_args():
options.add_argument("--textInput", metavar="file", nargs="?",
help="Text to perform interpretation on")
. . .
input = InterpretationInput(
text=args.textInput)
Input to interpret. Included in InterpretRequest. Use either text or the result from ASR as a Service.
| Field | Type | Description |
|---|---|---|
| text | string | Text input. |
| asr_result | nuance.asr.v1.RecognitionResponse | RecognitionResponse from ASR as a Service. |
This message includes:
InterpretRequest
InterpretationInput
text
or
asr_result
InterpretResponse
The interpretation result. Included in Runtime service.
| Field | Type | Description |
|---|---|---|
| status | Status | Whether the request was successful. The 200 code means success, other values indicate an error. |
| result | InterpretResult | The result of the interpretation. |
This message includes:
InterpretResponse
status (Status)
result (InterpretResult)
literal
interpretations (Interpretation)
Status
A Status message indicates whether the request was successful or reports errors that occurred during the request. Included in InterpretResponse.
| Field | Type | Description |
|---|---|---|
| code | uint32 | HTTP status code. The 200 code means success, other values indicate an error. |
| message | string | Brief description of the status. |
| details | string | Longer description if available. |
InterpretResult
For examples, see Interpretation results: Intents and Interpretation results: Entities.
Result of interpretation. Contains the input literal and one or more interpretations. Included in InterpretResponse.
| Field | Type | Description |
|---|---|---|
| literal | string | Input used for interpretation. For text input, this is always the raw input text. For input coming from ASR as a Service results, this gives a concatenation of the audio tokens, separated by spaces, in minimally formatted text format. For example, "Pay five hundred dollars." |
| formatted_literal | string | The formatted input literal. For input coming from ASR as a Service results, this is the text representation of the ASR result, but with formatted text. For example, "Pay $500." When the input for interpretation is text, this is the same as literal. |
| interpretations | Interpretation | Repeated. Candidate interpretations of the input. |
| sensitive | bool | Indicates whether the literal contains entities flagged as sensitive. Sensitive entities are masked in call logs. |
This message includes:
InterpretResponse
InterpretResult
literal
formatted_literal
interpretations (Interpretation)
sensitive
Interpretation
Candidate interpretation of the input. Included in InterpretResult.
The interpret request specifies the type of interpretation: either single-intent or multi-intent (see InterpretRequest - InterpretationParameters - interpretation_result_type). Multi-intent interpretation requires a semantic model that is enabled for multi-intent (not currently supported in Mix.nlu). See Interpretation results for details and more examples.
| Field | Type | Description |
|---|---|---|
| single_intent_interpretation | SingleIntentInterpretation | The result contains one intent. |
| multi_intent_interpretation | MultiIntentInterpretation | The result contains multiple intents. This choice requires a multi-intent semantic model, which is not currently supported in Nuance-hosted NLUaaS. |
This message includes:
InterpretResult
Interpretation
single_intent_interpretation (SingleIntentInterpretation)
or
multi_intent_interpretation (MultiIntentInterpretation)
SingleIntentInterpretation
Single intent interpretation returns the most likely intent, PLACE_ORDER, and an alternative, PAY_BILL, with a much lower confidence rate
"result": {
"literal": "I'd like to place an order",
"formatted_literal": "I'd like to place an order",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "PLACE_ORDER",
"confidence": 0.9941431283950806,
"origin": "STATISTICAL"
}
},
{
"single_intent_interpretation": {
"intent": "PAY_BILL",
"confidence": 0.0019808802753686905,
"origin": "STATISTICAL"
}
}
]
}
}
Single-intent interpretation results. Included in Interpretation. Theses results include one or more alternative intents, complete with entities if they occur in the text. Each intent is shown with a confidence score and whether the match was done from a grammar file or an SSM (statistical) file.
| Field | Type | Description |
|---|---|---|
| intent | string | Intent name as specified in the semantic model. |
| confidence | float | Confidence score (between 0.0 and 1.0 inclusive). The higher the score, the likelier the detected intent is correct. |
| origin | EnumOrigin | How the intent was detected. |
| entities | string,SingleIntentEntityList | Map of entity names to lists of entities: key, entity list. |
This message includes:
InterpretResponse
InterpretResult
SingleIntentInterpretation
intent
confidence
origin (EnumOrigin)
entities (key,SingleIntentEntityList)
entity (SingleIntentEntity)
EnumOrigin
Origin of an intent or entity. Included in SingleIntentInterpretation, SingleIntentEntity, IntentNode, and EntityNode.
| Name | Number | Description |
|---|---|---|
| UNKNOWN | 0 | |
| GRAMMAR | 1 | Determined from an exact match with a grammar file in the model. |
| STATISTICAL | 2 | Determined statistically from the SSM file in the model. |
SingleIntentEntityList
List of entities. Included in SingleIntentInterpretation.
| Field | Type | Description |
|---|---|---|
| entities | SingleIntentEntity | Repeated. An entity match in the intent, for single-intent interpretation. |
SingleIntentEntity
Single intent, PLACE_ORDER, with entity FLAVOR: strawberry and PRODUCT: cheesecake
"result": {
"literal": "I want to order a strawberry cheesecake",
"formatted_literal": "I want to order a strawberry cheesecake",
"interpretations": [
{
"single_intent_interpretation": {
"intent": "PLACE_ORDER",
"confidence": 0.9987062215805054,
"origin": "STATISTICAL",
"entities": {
"FLAVOR": {
"entities": [
{
"text_range": {
"start_index": 18,
"end_index": 28
},
"formatted_text_range": {
"start_index": 18,
"end_index": 28
},
"confidence": 0.9648909568786621,
"origin": "STATISTICAL",
"string_value": "strawberry",
"literal": "strawberry",
"formatted_literal": "strawberry"
}
]
},
"PRODUCT": {
"entities": [
{
"text_range": {
"start_index": 29,
"end_index": 39
},
"formatted_text_range": {
"start_index": 29,
"end_index": 39
},
"confidence": 0.9585300087928772,
"origin": "STATISTICAL",
"string_value": "cheesecake",
"literal": "cheesecake",
"formatted_literal": "cheesecake",
}
]
}
}
}
}
]
}
}
Entity in the intent. Included in SingleIntentEntityList.
| Field | Type | Description |
|---|---|---|
| text_range | TextRange | Range of literal text for which this entity applies. |
| formatted_text_range | TextRange | Range of the formatted literal text for which this entity applies. When the input for interpretation comes from an ASR result, this may be absent if there is misalignment. |
| confidence | float | Confidence score between 0.0 and 1.0 inclusive. The higher the score, the likelier the entity detection is correct. |
| origin | EnumOrigin | How the entity was detected. |
| entities | string, SingleIntentEntityList | For hierarchical entities, the child entities of the entity: key, entity list. |
| string_value | string | The canonical value as a string. |
| struct_value | google.protobuf. Struct | The entity value as an object. This object may be directly converted to a JSON representation. |
| literal | string | The input literal associated with this entity. For text input, this is the raw input text. For input coming from ASR results, this is in minimally formatted text format. |
| formatted_literal | string | The formatted input literal associated with the entity. When the input for interpretation is text, this is the same as literal. |
| sensitive | bool | Indicates whether the entity has been flagged as sensitive. Sensitive entities are masked in call logs. |
| audio_range | AudioRange | Range of audio input this operator applies to. Available only when interpreting a recognition result from ASR as a Service. |
This message includes:
InterpretResponse
InterpretResult
SingleIntentInterpretation
SingleIntentEntityList
SingleIntentEntity
text_range (TextRange)
formatted_text_range (TextRange)
confidence
origin (EnumOrigin)
entities (key, SingleIntentEntityList)
string_value
struct_value
literal
formatted_literal
sensitive
audio_range (AudioRange)
TextRange
Range of text in the input literal. Included in SingleIntentEntity, OperatorNode, IntentNode, and EntityNode.
| Field | Type | Description |
|---|---|---|
| start_index | uint32 | Inclusive, 0-based character position, in relation to literal text. |
| end_index | uint32 | Exclusive, 0-based character position, in relation to literal text. |
AudioRange
Range of time in the input audio. Included in and SingleIntentEntity, OperatorNode, IntentNode, and EntityNode. Available only when interpreting a recognition result from ASR as a Service.
| Field | Type | Description |
|---|---|---|
| start_time_ms | uint32 | Inclusive start time in milliseconds. |
| end_time_ms | uint32 | Exclusive end time in milliseconds. |
MultiIntentInterpretation
Multi-intent interpretation against a standard semantic model returns just one intent for each candidate in the "root" object
"result": {
"literal": "Price list and place order",
"formatted_literal": "Price list and place order",
"interpretations": [
{
"multi_intent_intepretation": {
"root": {
"intent": {
"name": "GET_INFO",
"text_range": {
"end_index": 26
},
"formatted_text_range": {
"end_index": 26
},
"confidence": 0.8738054037094116,
"origin": "STATISTICAL"
}
}
}
},
{
"multi_intent_intepretation": {
"root": {
"intent": {
"name": "PLACE_ORDER",
"text_range": {
"end_index": 26
},
"formatted_text_range": {
"end_index": 26
},
"confidence": 0.08993412554264069,
"origin": "STATISTICAL"
}
}
}
}
]
}
Multi-intent interpretation. Contains a tree of nodes representing the detected operators, intents, and entities and their associations. Included in Interpretation.
Multi-intent interpretation may be requested without error, but it is not currently supported as it requires a multi-intent semantic model, not yet available in Mix. When requesting multi-intent interpretation against a single-intent model, the results contain the same information as a single-intent interpretation, but formatted slightly differently: the root of the multi-intent interpretation contains the intent.
| Field | Type | Description |
|---|---|---|
| root | InterpretationNode | Root node of the interpretation tree. Can be either OperatorNode or IntentNode. |
This message includes:
InterpretResponse
InterpretResult
MultiIntentInterpretation
root (InterpretationNode)
InterpretationNode
Node in the interpretation tree. Included in MultiIntentInterpretation.
| Field | Type | Description |
|---|---|---|
| operator | OperatorNode | The relationship of the intents or entities. |
| intent | IntentNode | The intents detected in the user input. |
| entity | EntityNode | The entities in the intent. |
This message includes:
InterpretResponse
InterpretResult
MultiIntentInterpretation
InterpretationNode
operator (OperatorNode)
intent (IntentNode)
entity (EntityNode)
OperatorNode
Logical operator node. Included in InterpretationNode.
| Field | Type | Description |
|---|---|---|
| operator | EnumOperator | Type of operator. |
| text_range | TextRange | Range of the literal text this operator applies to. |
| formatted_text_range | TextRange | Range of the formatted literal text this operator applies to. When the input for interpretation is an ASR result, this may be absent if there is misalignment. |
| children | InterpretationNode | Repeated. Child nodes for this operator. An operator node always has children. |
| literal | string | The input literal associated with this operator. For text input, this is the raw input text. For input coming from ASR as a Service results, this is in minimally formatted text format. |
| formatted_literal | string | The formatted input literal associated with this operator. When the input for interpretation is text, this is the same as literal. |
| sensitive | bool | Indicates whether a child entity of this operator node has been flagged as sensitive. Sensitive entities are masked in call logs. |
| audio_range | AudioRange | Range of audio input this operator applies to. Available only when interpreting a recognition result from ASR as a Service. |
This message includes:
InterpretResponse
InterpretResult
MultiIntentInterpretation
InterpretationNode
OperatorNode
operator (EnumOperator)
text_range (TextRange)
formatted_text_range (TextRange)
children (InterpretationNode)
literal
formatted_literal
sensitive
audio_range (AudioRange)
EnumOperator
Logical operator type, AND, OR, or NOT. Included in OperatorNode.
| Name | Number | Description |
|---|---|---|
| AND | 0 | The following item is an additional intent or entity. |
| OR | 1 | The following item is an alternative intent or entity. |
| NOT | 2 | The following item is not detected. |
IntentNode
Node representing an intent. Included in InterpretationNode.
| Field | Type | Description |
|---|---|---|
| name | string | Intent name as specified in the semantic model. |
| text_range | TextRange | Range of literal text this intent applies to. |
| formatted_text_range | TextRange | Range of the formatted literal text this operator applies to. When the input for interpretation is an ASR result, this may be absent if there is misalignment. |
| confidence | float | Confidence score between 0.0 and 1.0 inclusive. The higher the score, the likelier the detected intent is correct. |
| origin | EnumOrigin | How the intent was detected. |
| children | InterpretationNode | Repeated. Child nodes for this intent. An intent node has zero or more child nodes. |
| literal | string | The input literal associated with this intent. For text input, this is the raw input text. For input coming from ASR as a Service results, this is in minimally formatted text format. |
| formatted_literal | string | The formatted input literal associated with this intent. When the input for interpretation is text, this is the same as literal. |
| sensitive | bool | Indicates whether a child entity of this intent node has been flagged as sensitive. Sensitive entities are masked in call logs. |
| audio_range | AudioRange | Range of audio input this operator applies to. Available only when interpreting a recognition result from ASR as a Service. |
This message includes:
InterpretResponse
InterpretResult
MultiIntentInterpretation
InterpretationNode
IntentNode
name
text_range (TextRange)
formatted_text_range (TextRange)
confidence
origin (EnumOrigin)
children (InterpretationNode)
literal
formatted_literal
sensitive
audio_range (AudioRange)
EntityNode
Node representing an entity. Included in InterpretationNode.
| Field | Type | Description |
|---|---|---|
| name | string | Entity name as specified in the semantic model. |
| text_range | TextRange | Range of literal text this intent applies to. |
| formatted_text_range | TextRange | Range of the formatted literal text this operator applies to. When the input for interpretation is an ASR result, this may be absent if there is misalignment. |
| confidence | float | Confidence score between 0.0 and 1.0 inclusive. The higher the score, the likelier the detected entity is correct. |
| origin | EnumOrigin | How the intent was detected. |
| children | InterpretationNode | Repeated. Child nodes for this entity. A hierarchical entity node can have child entity and operator nodes. Entity nodes currently never have intent nodes as children. |
| string_value | string | The value of the entity as specified in the semantic model. |
| struct_value | google. protobuf.Struct | Structured data, ready to convert to a JSON representation. |
| literal | string | The input literal associated with this entity. For text input, this is the raw input text. For input coming from ASR results, this is in minimally formatted text format. |
| formatted_literal | string | The formatted input literal associated with this entity. When the input for interpretation is text, this is the same as literal. |
| sensitive | bool | Indicates whether the entity has been flagged as sensitive. Sensitive entities are masked in call logs. |
| audio_range | AudioRange | Range of audio input this operator applies to. Available only when interpreting a recognition result from ASR as a Service. |
This message includes:
InterpretResponse
InterpretResult
MultiIntentInterpretation
InterpretationNode
EntityNode
name
text_range (TextRange)
formatted_text_range (TextRange)
confidence
origin (EnumOrigin)
children (InterpretationNode)
string_value
struct_value
literal
formatted_literal
sensitive
audio_range (AudioRange)
Wordset gRPC API
NLU as a Service provides a set of protocol buffer (.proto) files to define a gRPC Wordset service. These files allow you to use large wordsets with your NLUaaS applications:
- nuance/nlu/wordset/v1beta1/wordset.proto contains the methods and messages needed to work with large wordsets in NLU applications.
- nuance/nlu/common/v1beta1/resource.proto and nuance/nlu/common/v1beta1/job.proto define messages for referencing external resources (NLU models and wordsets) and for job status updates.
- nuance/rpc/status.proto, nuance/rpc/status_code.proto, and nuance/rpc/error_details define messages for rpc status and error codes.
Wordset proto file structure
The file wordset.proto defines a Wordet service with several RPC methods for creating and managing wordsets.

For the nuance.nlu.common.v1beta1 messages, see Common messages.
For the nuance.rpc.Status and related messages, see RPC status messages.
Job status vs. request status
This API includes two types of status:
- Job status refers to the condition of the job that is compiling the wordset. Its values are set in JobStatus and can be JOB_STATUS_PROCESSING, ~ COMPLETE, or ~FAILED.
- Request status refers to the condition of the gRPC request. Its values are set in nuance.rpc.StatusCode and can be OK, INVALID_REQUEST, NOT_FOUND, ALREADY_EXISTS, BAD_REQUEST, and so on.
Wordset service
The Wordset service offers three RPC methods to compile and manage wordsets.
| Name | Request Type | Response Type | Description |
|---|---|---|---|
| CompileWordsetAndWatch | CompileWordset Request | WatchJobStatus Response stream | Submit and watch for job completion (server streaming) |
| GetWordsetMetadata | GetWordset MetadataRequest | GetWordset MetadataResponse | Gets a compiled wordset's metadata (unary) |
| DeleteWordset | DeleteWordset Request | DeleteWordset Response | Delete the compiled wordset (unary). |
CompileWordsetAndWatch
Process flow of CompileWordsetAndWatch method
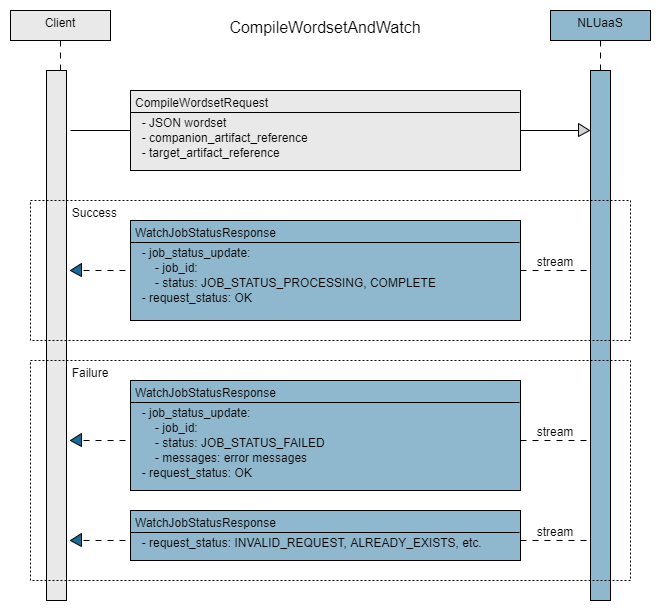
This RPC method submits a request to compile a wordset and returns streaming messages from the server until the job completes. It consists of CompileWordsetRequest and WatchJobStatusResponse.
The method submits a wordset to be compiled and starts a batch compilation job. The response is a server stream of job progress notifications, which stays alive until the end of the compilation job, followed by a final job status.
The WatchJobStatusResponse returns these notifications:
- Job ID (Not used. This will always be empty)
- One or more job status responses with JOB_STATUS_PROCESSING. The same status may be returned multiple times. Repeated notifications also keep the process alive.
- Final job status with JOB_STATUS_COMPLETE or ~FAILED, or with error messages when appropriate.
- Final request status, either OK for successful requests, or INVALID_REQUEST, ALREADY_EXISTS, BAD_REQUEST, and so on for unsuccessful requests. This status refers to the request itself, not the wordset compile job that was created. See Job status vs. request status.
CompileWordsetRequest
Request to compile a wordset related to a dynamic list entity.
| Field | Type | Description |
|---|---|---|
| wordset | string | Mandatory. Inline wordset JSON resource. Note: 4 MB request size limit. |
| companion_artifact_reference | nuance.nlu.common.v1beta1. ResourceReference | Mandatory. URN reference to the NLU model in which the entity is defined. |
| target_artifact_reference | nuance.nlu.common.v1beta1. ResourceReference | Mandatory. URN reference to use with the compiled wordset. The URN will later be used to reference the wordset to use it as an interpretation resource. |
| metadata | string,string | Client-supplied key,value pairs to associate with the artifact. Keys can only contain lower case characters. |
| client_data | string,string | Client-supplied key,value pairs to inject into the logs. |
This message includes:
CompileWordsetRequest
wordset
companion_artifact_reference (nuance.nlu.common.v1beta1.ResourceReference)
target_artifact_reference (nuance.nlu.common.v1beta1.ResourceReference)
metadata
client_data
WatchJobStatusResponse
A series of these are streamed in response to a CompileWordset request. The responses provide status on both the wordset compilation job and the CompileWordsetAndWatch gRPC request.
| Field | Type | Description |
|---|---|---|
| job_status_update | nuance.nlu.common.v1beta1. JobStatusUpdate | Immediate job status |
| request_status | nuance.rpc.Status | Request status. Returned once at the end. |
This message includes:
WatchJobStatusResponse
job_status_update (nuance.nlu.common.v1beta1.JobStatusUpdate)
request_status (nuance.rpc.Status)
GetWordsetMetadata
Process flow for GetWordsetMetadata

This RPC method requests and returns information about a compiled wordset. It does not return the content of the wordset. It provides two types of metadata:
Custom metadata, optionally supplied by the client as metadata in CompileWordsetRequest.
Default metadata (reserved keys):
x_nuance_companion_checksum_sha256: The companion DLM, SHA256 hash in hex format.
x_nuance_wordset_content_checksum_sha256: The source wordset content, SHA256 hash in hex format.
x_nuance_compiled_wordset_checksum_sha256: The compiled wordset, SHA256 hash in hex format.
x_nuance_compiled_wordset_last_update: Date and time of last update as ISO 8601 UTC date.
GetWordsetMetadataRequest
Request for a GetWordsetMetadata request.
| Field | Type | Description |
|---|---|---|
| artifact_reference | nuance.nlu.common.v1beta1. ResourceReference | Reference to the wordset artifact. |
This message includes:
GetWordsetMetadataRequest
artifact_reference (nuance.nlu.common.v1beta1.ResourceReference)
GetWordsetMetadataResponse
Response to a GetWordsetMetadata request.
| Field | Type | Description |
|---|---|---|
| metadata | string,string | Default and client-supplied key,value pairs. |
| request_status | nuance.rpc.Status | Indicates whether fetching of metadata was done successfully. |
This message includes:
GetWordsetMetadataResponse
metadata
request_status (nuance.rpc.Status)
DeleteWordset
Process flow for DeleteWordset
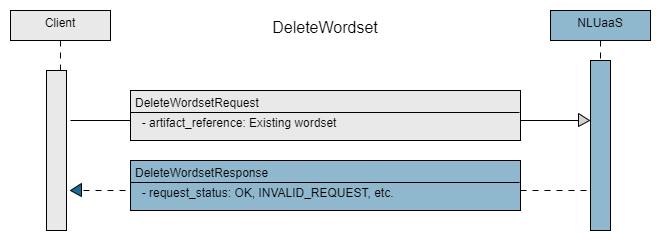
This RPC method deletes a specified wordset.
DeleteWordsetRequest
Request to a DeleteWordset request.
| Field | Type | Description |
|---|---|---|
| artifact_reference | nuance.nlu.common.v1beta1. ResourceReference | Reference to the wordset artifact. |
This message includes:
DeleteWordsetRequest
artifact_reference (nuance.nlu.common.v1beta1.ResourceReference)
DeleteWordsetResponse
Response to a DeleteWordset request.
| Field | Type | Description |
|---|---|---|
| request_status | nuance.rpc.Status | Indicates whether deletion was done successfully. |
This message includes:
DeleteWordsetResponse
request_status (nuance.rpc.Status)
Common messages
These messages are part of the nuance.nlu.common.v1beta1 package and are used to reference external files like NLU models and to report job statuses.
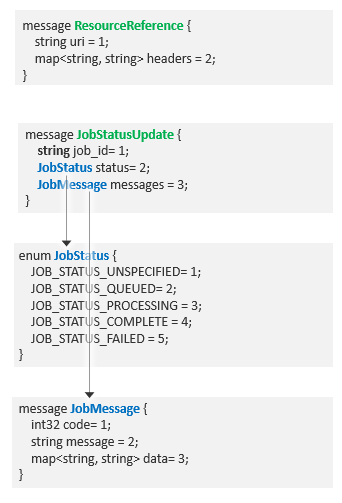
nuance.nlu.common.v1beta1.ResourceReference
Input message for fetching an external resource.
| Field | Type | Description |
|---|---|---|
| uri | string | Location of the resource as a URN reference |
| headers | string, string | Field for internal use |
nuance.nlu.common.v1beta1.JobStatusUpdate
Job status update to a request.
| Field | Type | Description |
|---|---|---|
| job_id | string | Not used. |
| status | JobStatus | Job status |
| messages | JobMessage | Repeated. Messages specifying about the job failure or completion. |
nuance.nlu.common.v1beta1.JobStatus
Job Status Enum
| Name | Number | Description |
|---|---|---|
| JOB_STATUS_UNKNOWN | 0 | Job status not specified or unknown. |
| JOB_STATUS_QUEUED | 1 | Not used. |
| JOB_STATUS_PROCESSING | 2 | Job is processing. |
| JOB_STATUS_COMPLETE | 3 | Job is complete. |
| JOB_STATUS_FAILED | 4 | Job has failed. |
nuance.nlu.common.v1beta1.JobMessage
Job Message
| Field | Type | Description |
|---|---|---|
| code | int32 | Code |
| message | string | Message |
| data | string, string | Additional key/value pairs |
RPC status messages
These messages are part of the nuance.rpc package and are used for RPC status and error information.

nuance.rpc.Status
Common status message.
| Field | Type | Description |
|---|---|---|
| status_code | StatusCode | Mandatory. Status code, an enum value |
| status_sub_code | int32 | Application-specific status sub-code. |
| http_trans_code | int32 | Not used. |
| request_info | RequestInfo | Information about the original request |
| status_message | LocalizedMessage | Message providing the details of this status |
| help_info | HelpInfo | Help message providing the possible user action(s) |
| field_violations | FieldViolation | Repeated. Set of field violations. |
| retry_info | RetryInfo | Retry information |
| status_details | StatusDetail | Repeated. Detailed status messages. |
nuance.rpc.StatusCode
Set of global canonical status codes to be commonly used by compliant Nuance APIs.
| Name | Number | Description |
|---|---|---|
| UNSPECIFIED | 0 | Unspecified status |
| OK | 1 | Success |
| BAD_REQUEST | 2 | Invalid message type: the server cannot understand the request. |
| INVALID_REQUEST | 3 | The request has an invalid value, is missing a mandatory field, and so on. |
| CANCELLED_CLIENT | 4 | Operation terminated by client. The remote system may have changed. |
| CANCELLED_SERVER | 5 | Operation terminated by server. The remote system may have changed. |
| DEADLINE_EXCEEDED | 6 | The deadline set for the operation has expired. |
| NOT_AUTHORIZED | 7 | The client does not have authorization to perform the operation. |
| PERMISSION_DENIED | 8 | The client does not have authorization to perform the operation on the requested entities. |
| NOT_FOUND | 9 | The requested entity was not found. |
| ALREADY_EXISTS | 10 | Cannot create entity as it already exists. |
| NOT_IMPLEMENTED | 11 | Unsupported operation or parameter, for example an unsupported media type. |
| UNKNOWN | 15 | Result does not map to any defined status. Other response values may provide request-specific additional information. |
| The following status codes are less frequently used: | ||
| TOO_LARGE | 51 | A field is too large to be processed due to technical limitations for example a large audio or other binary block. For arbitrary limitations (for example the name must be n characters or less), use INVALID_REQUEST. |
| BUSY | 52 | The server understood the request but could not process it due to lack of resources. Retry the request as is later. |
| OBSOLETE | 53 | A message type in the request is no longer supported. |
| RATE_EXCEEDED | 54 | Similar to BUSY. The client has exceeded the limit of operations per time unit. Retry request as is later. |
| QUOTA_EXCEEDED | 55 | The client has exceeded quotas related to licensing or payment. See your client representative for additional quotas. |
| INTERNAL_ERROR | 56 | An internal system error experienced while processing the request |
nuance.rpc.RequestInfo
A message may use this type to refer to the original request that resulted in an error. This may be particularly useful in the streaming scenarios where the correlation between the request and response may not be so obvious.
| Field | Type | Description |
|---|---|---|
| request_id | string | Identifier of the original request, for example, its OpenTracing id. |
| request_data | string | Relevant free format data from the original request, for troubleshooting. |
| additional_request_data | string,string | Map of key,value pairs of free format data from the request. |
nuance.rpc.LocalizedMessage
A localized message. The choice of the locale is up to the backend. Depending on the use case, it may be the preferred language provided by the browser or the user-specific locale. The server will do its best to determine.
| Field | Type | Description |
|---|---|---|
| locale | string | The locale as xx-XX, for example en-US, fr-CH, es-MX, per the specification bcp47.txt. Default is provided by the server. |
| message | string | The message text in the local specified. |
| message_resource_id | string | A message identifier, allowing related messages to be provided if needed. |
nuance.rpc.HelpInfo
Provides a reference to the help document that may be shown to the end user in order to take an action based on the error/status response. For example, if the original request carried a numerical value that is out of allowed range, this message may be used to point to the documentation that states the valid range.
| Field | Type | Description |
|---|---|---|
| links | Hyperlink | Repeated. Set of links related to the context of the enclosing message |
nuance.rpc.Hyperlink
| Field | Type | Description |
|---|---|---|
| description | LocalizedMessage | A description of the link in a specific language. By default, the server handling the URL manages language selection and detection. |
| url | string | The URL to offer to the client, containing help information. If a description is present, this URL should use (or offer) the same locale. |
nuance.rpc.FieldViolation
Provides the information about a field violating a rule.
| Field | Type | Description |
|---|---|---|
| field | string | The name of the request field in violation as package.type[.type].field. |
| rel_field | string | Repeated. The names of related fields in violation as package.type[.type].field. |
| user_message | LocalizedMessage | An error message in a language other than English. |
| message | string | An error message in American English. |
| invalid_value | string | The invalid value of the field in violation. (Convert non-string data types to string.) |
| violation | ViolationType | The reason (enum) a field is invalid. Can be used for automated error handling by the client. |
nuance.rpc.ViolationType
| Name | Number | Description |
|---|---|---|
| MANDATORY_FIELD_MISSING | 0 | A required field was not provided. |
| FIELD_CONFLICT | 1 | A field is invalid due to the value of another field. |
| OUT_OF_RANGE | 2 | A field value is outside the specified range. |
| INVALID_FORMAT | 3 | A field value is not in the correct format. |
| TOO_SHORT | 4 | A text field value is too short. |
| TOO_LONG | 5 | A text field value is too long. |
| OTHER | 64 | Violation type is not otherwise listed. |
| UNSPECIFIED | 99 | Violation type was not set. |
nuance.rpc.RetryInfo
This message is used to control how quickly the client may retry the request if the request is retriable. Failure to respect this retry info may indicate the misbehaving client.
| Field | Type | Description |
|---|---|---|
| retry_delay_ms | int32 | Clients must wait at least this long between retrying the same request. |
nuance.rpc.StatusDetail
A status message may have additional details, usually a list of underlying causes of an error. In contrast to field violations, which point to the fields in the original request, status details are not usually directly connected with the request parameters.
| Field | Type | Description |
|---|---|---|
| message | string | The message text in American English. |
| user_message | LocalizedMessage | The message text in a language other than English. |
| extras | string, string | Map of key,value pairs of additional application-specific information. |
Scalar value types
The data types in the proto files are changed to equivalent types in the generated client stub files.
Change log
2022-08-17
Some minor updates to Status messages and codes.
2022-07-20
Some minor updates to Wordsets.
2022-05-04
Updates to Sample Python runtime client and Sample Python wordsets client to add downloadable files for the sample apps.
2022-03-30
Updates to Sample Python wordsets client.
2022-03-16
Minor updates to sample app run script in Runtime app development.
2021-09-25
- Removed API documentation for obsolete v1beta1 protocol.
2021-08-04
- Updating various interpretation results to add new formatted_literal field. Formatted literal gives a formatted version of the literal for user inputs coming from ASR results. For more information see Interpretation results: Literals.
To make use of the new wordset features, follow instructions in gRPC setup to:
- Download the latest proto files
- Generate the client stubs from the proto files
2021-06-02
- Changes to treatment of interpretation confidences in the case of exact matches for text coming from ASR recognition results. See Interpretation results: confidence for more details.
2021-05-04
- Version v1beta1 of the NLUaaS API is now obsolete.
- Introducing the new Wordset gRPC API. The Wordset API allows you to compile large wordsets ahead of time and perform operations on those wordsets. The compiled wordsets are stored on the Mix platform and can then be referenced at runtime, improving interpretation performance for dynamic list entities while reducing the latency compared to inline wordsets. The Wordset API depends on new proto files contained in a new downloadable zip file. Referencing compiled wordsets through the runtime API depends on updates to the existing protos. Note that your existing applications will continue to work against the new proto files. For details about the new API see Wordset gRPC API and Sample Python wordsets client.
To make use of the new wordset features, follow instructions in gRPC setup to:
- Download the latest proto files
- Generate the client stubs from the proto files
2021-01-13
- Updated code samples in token generation step to reflect most up to date syntax for client ID.
2020-12-14
- Updated gRPC setup with new gRPC proto files to reflect new ability to mark entities as sensitive personally identifiable information, so that values are masked in call logs.
- A new field, sensitive, was added in multiple messages in result.proto, single-intent-interpretation.proto, and multi-intent-interpretation.proto. See InterpretResult, SingleIntentEntity, OperatorNode, IntentNode, and EntityNode.
2020-06-24
- A new field, user_id, was added to the runtime.proto file. See InterpretRequest.
2020-04-30
- Updated sample Java application for v1 proto files.
2020-03-30
Updated proto files for v1. See gRPC setup. See Upgrading to v1 for details.
URN format changed: urn:nuance:mix/<language>/<context_tag>/mix.nlu → urn:nuance-mix:tag:model/<context_tag>/mix.nlu?=language=<language>
The old format is supported but deprecated.
Edited proto file image and Defaults table, etc. to reflect changes in proto files.
2020-02-19
- Added result examples. See Interpretation results: Intents and Interpretation results: Entities.
- Added examples to API section.
- Added images illustrating the proto file structure. See Proto file structure.
2020-01-22
- Added Status messages and codes.
- Added Wordsets.
- Added Defaults.
2019-12-18
- Updated Client app development: new source code in Python, Go, and Java.
- Replaced Reference with gRPC setup, with clearer organization.
- Updated gRPC setup: Generating stub files in Python, Go, and Java.
- Replaced Prerequisites with Prerequisites from Mix.
Added Field names in proto and stub files.
2019-12-11
- Updated gRPC setup with new gRPC proto files.
- Updated gRPC API with more and better descriptions.
- Updated NLU essentials and InterpretationResource. Only inline wordsets are currently supported.
2019-12-02
- Updated occurrences of the term "concept" with "entity."
2019-11-25
- Added NLU essentials.
- Updated the sequence flow diagram in Client app development.
2019-11-15
Below are changes made to the NLUaaS API documentation since the initial Beta release:
- Updated the documentation structure to include the API version in the URL.
- Updated gRPC setup and Client app development.
- Added Prerequisites.
- Added the sequence flow diagram in Client app development.
- Minor corrections.