
NLU modeling best practices
This document describes best practices for creating high-quality NLU models. This document is not meant to provide details about how to create an NLU model using Mix.nlu, since this process is already documented. The idea here is to give a set of best practices for developing more accurate NLU models more quickly. This document is aimed at developers who already have at least a basic familiarity with the Mix.nlu model development process.
Overview
The best practices in this document are organized around the following steps of NLU model building:
- Designing the model: How to design your ontology to maximize accuracy and minimize effort.
- Generating data and training the initial model: How to generate initial data. You will need to generate initial training data for the model. The training data consists of examples of the kinds of utterances that the model will need to understand, along with their semantic interpretations. Mix.nlu trains the NLU model based on the training data so that whenever it gets an input utterance, it outputs a semantic interpretation that is as similar as possible to what is in the training data. Generation of training data could be from scratch, or if there is existing log data about user requests, it could be a matter of selecting from this data.
- Evaluating NLU accuracy: After Mix.nlu trains the NLU model on the training data, you will also need test data that can be run against the model so you can understand how well the model has learned how to predict the meanings of new utterances.
- Improving NLU accuracy: Once you have a trained NLU model and a have set of test results from that model, the accuracy of the model can be improved via analysis. There are basically two kinds of analysis: error analysis and consistency checking. In error analysis, you start with errors that the model is making and try to improve the model to not make those errors. In consistency checking, you analyze your annotations to make sure that they are consistent. Improving the model (including retesting the improved model) is an ongoing process — as more test and training data become available, additional iterations of accuracy improvement can be performed.
We also include a section of frequently asked questions (FAQ) that are not addressed elsewhere in the document.
Notation convention for NLU annotations
In this document, when we give an example of an annotated utterance, we use a notation that is similar to the notation used by Mix.nlu itself. Word sequences that correspond to entities are preceded by the name of the entity in square brackets (e.g. "[SIZE]"), and are followed by a "[/]". Word sequences that correspond to intents (in most cases, this is the entire utterance) are preceded by the name of the intent in curly braces (e.g. "{ORDER_PIZZA}") and followed by a "{/}". So for example, the utterance "I want to order a large pizza" could be annotated as follows:
{ORDER_PIZZA} I want to order a [SIZE] large [/] pizza {/}
In this example, the intent associated with the entire utterance is ORDER_PIZZA, and the only entity in the utterance is the SIZE entity, which has the literal "large".
Nuance refers to this notation as XMix (eXtended Mix) format.
(Note that Mix supports exporting annotations in a different format called TRSX. However, TRSX uses an XML format that is not easily human-readable, so we don't use it here.)
Designing the model
Designing a model means creating an ontology that captures the meanings of the sorts of requests your users will make.
In the context of Mix.nlu, an ontology re8rs to the schema of intents, entities, and their relationships that you specify and that are used when annotating your samples and interpreting user queries. These represent the things your users will want to do and the things they will mention to specify that intention.
For more details, see see Ontology.
This section looks at several best practices for designing NLU models:
- Don't overuse intents
- Use predefined entities when appropriate
- Use the NO_INTENT predefined intent for fragments
- Use hierarchical entities
- Define intents and entities that are semantically distinct
- Use an out-of-domain intent
- Don't ask your model to try to do too much
- Use a consistent naming convention
Don't overuse intents
In many cases, you have to make an ontology design choice around how to divide the different user requests you want to be able to support. Generally, it's better to use a few relatively broad intents that capture very similar types of requests, with the specific differences captured in entities, rather than using many super-specific intents.
For example, consider the ontology needed to model the following set of utterances:
- Order a pizza
- Order a large pizza
- Order a small pizza
- Order a large coke
- Order chicken wings
So here, you're trying to do one general common thing—placing a food order. The order can consist of one of a set of different menu items, and some of the items can come in different sizes.
Best practice—most general ontology
The best practice in this case is to define a single intent ORDER, and then define an entity SIZE with possible values of "large" and "small," and an entity MENU_ITEM that includes values of "pizza," "coke," and "chicken wings." That would look something like this:
- {ORDER} order a [MENU_ITEM] pizza [/] {/}
- {ORDER} order a [SIZE] large [/] [MENU_ITEM] pizza [/] {/}
- {ORDER} order a [SIZE] small [/] [MENU_ITEM] pizza [/] {/}
- {ORDER} Order a [SIZE] large [/] [MENU_ITEM] coke [/] {/}
- {ORDER} Order [MENU_ITEM] chicken wings [/] {/}
Less general ontology—not recommended
Another approach would be to encode the menu item literals into the intent but keep the SIZE entity only:
- {ORDER_PIZZA} order a pizza {/}
- {ORDER_PIZZA} order a [SIZE] large [/] pizza {/}
- {ORDER_PIZZA} order a small pizza {/}
- {ORDER_COKE} order a [SIZE] large [/] coke {/}
- {ORDER_CHICKEN_WINGS} order chicken wings {/}
Least general ontology—not recommended
And yet another approach would be to encode both the menu item and size entity literals into the intent:
- {ORDER_PIZZA} order a pizza {/}
- {ORDER_LARGE_PIZZA} order a large pizza {/}
- {ORDER_SMALL_PIZZA} order a small pizza {/}
- {ORDER_LARGE_COKE} order a large coke {/}
- {ORDER_CHICKEN_WINGS} order chicken wings {/}
By using a general intent and defining the entities SIZE and MENU_ITEM, the model can learn about these entities across intents, and you don't need examples containing each entity literal for each relevant intent. By contrast, if the size and menu item are part of the intent, then training examples containing each entity literal will need to exist for each intent. The net effect is that less general ontologies will require more training data in order to achieve the same accuracy as the recommended approach.
Another reason to use a more general intent is that once an intent is identified, you usually want to use this information to route your system to some procedure to handle the intent. Since food orders will all be handled in similar ways, regardless of the item or size, it makes sense to define intents that group closely related tasks together, specifying important differences with entities.
Use predefined entities when appropriate
Mix includes a number of predefined entities; see predefined entities.
When possible, use predefined entities. Developing your own entities from scratch can be a time-consuming and potentially error-prone process when those entities are complex, for example for dates, which may be spoken or typed in many different ways. It is much faster and easier to use the predefined entity, when it exists. And since the predefined entities are tried and tested, they will also likely perform more accurately in recognizing the entity than if you tried to create it yourself. There is no point in reinventing the wheel.
You can effectively assign a custom name to a predefined entity by creating an entity with the name you prefer, and then defining that entity to be an instance of ("isA") a predefined entity. For example, say you are creating an application that lets a user book a return ticket for travel. You need to look for two calendar dates in the user sentence: one for the departure date and one for the return date. By defining two custom entities DEPARTURE_DATE isA nuance_CALENDARX and RETURN_DATE is a nuance_CALENDARX, your model will be able to learn to resolve which date corresponds to which role in a sentence, while still taking advantage of the benefits of using the predefined entity nuance_CALENDARX.
Use the NO_INTENT predefined intent for fragments
Users often speak in fragments, that is, speak utterances that consist entirely or almost entirely of entities. For example, in the coffee ordering domain, some likely fragments might be "short latte", "Italian soda", or "hot chocolate with whipped cream". Because fragments are so popular, Mix has a predefined intent called NO_INTENT that is designed to capture them. NO_INTENT automatically includes all of the entities that have been defined in the model, so that any entity or sequence of entities spoken on their NO_INTENT doesn't require its own training data.
Make use of hierarchical entities when appropriate
Making use of hierarchical entities can make your ontology simpler. For example, a BANK_ACCOUNT entity might have ACCOUNT_NUMBER, ACCOUNT_TYPE and ACCOUNT_BALANCE sub-entities. These are defined via "hasA" relationships: "BANK_ACCOUNT hasA (ACCOUNT_NUMBER, ACCOUNT_TYPE, ACCOUNT_BALANCE)."
On the other hand, for a funds transfer utterance such as "transfer $100 from checking to savings", you may want to define FROM_ACCOUNT and TO_ACCOUNT entities. By using the "isA" relationship, you can define the relationships:
- "FROM_ACCOUNT isA BANK_ACCOUNT"
- "TO_ACCOUNT isA BANK_ACCOUNT"
This way, the sub-entities of BANK_ACCOUNT also become sub-entities of FROM_ACCOUNT and TO_ACCOUNT; there is no need to define the sub-entities separately for each parent entity.
For more details, see Relationship entities.
Define intents and entities that are semantically distinct
In your ontology, every element should be semantically distinct; you shouldn't define intents or entities that are semantically similar to or overlap with other intents or entities. There needs to be a clear, clean distinction and separation between the different intents the model seeks to support, and between the different entities seen by the model if you want the model to be able to resolve the distinctions in its inference.
It will be difficult for the trained NLU model to distinguish between semantically similar elements, because the overlap or closeness in meaning will cause ambiguity and uncertainty in interpretation, with low confidence levels. The model will have trouble identifying a clear best interpretation. In choosing a best interpretation, the model will make mistakes, bringing down the accuracy of your model.
The differences in meaning between the different intents should be clearly visible in the words used to express each intent. If possible, each intent should be associated with a distinct set of carrier phrases and entities. A carrier phrase is the part of a sentence for an intent which is not the entities themselves. For example, if your application is trying to distinguish between showing bills (REQUEST_BILL) and paying bills (PAY_BILL), then you might set up (and document via an annotation guide – see below) the following rules:
- "Show bills" → REQUEST_BILL
- "Pay bills" → PAY_BILL
- "What are my bills" → REQUEST_BILL
- "Handle my bills" → PAY_BILL. Here you could argue that the user might first like to see the bills first, rather than pay them directly, so the decision has a UX impact
- "View my bills so I can pay them" → ? This kind of hard-to-annotate utterance will occur in real usage data. Ultimately, a decision (even if arbitrary) must be made and documented.
Use an out-of-domain intent
The end users of an NLU model don't know what the model can and can't understand, so they will sometimes say things that the model isn't designed to understand. For this reason, NLU models should typically include an out-of-domain intent that is designed to catch utterances that it can't handle properly. This intent can be called something like OUT_OF_DOMAIN, and it should be trained on a variety of utterances that the system is expected to encounter but cannot otherwise handle. Then at runtime, when the OUT_OF_DOMAIN intent is returned, the system can accurately reply with "I don't know how to do that".
Many older NLU systems do not use an out-of-domain intent, but instead rely on a rejection threshold to achieve the same effect: NLU interpretations whose confidence values fall below a particular threshold are thrown out, and the system instead replies with "I didn't understand". However, a rejection threshold has two disadvantages compared to an out-of-domain intent:
- The system is not trained on any out-of-domain data, so the model is not trained to explicitly discriminate between in-domain and out-of-domain utterances. Because of this the accuracy of the system will be lower, particularly on utterances that are not clearly in-domain or out-of-domain (that is, utterances that are closer to the decision boundary between in-domain and out-of-domain).
- The confidence threshold needs to be manually tuned, which is difficult to do properly without a test set of usage data that includes a large proportion of out-of-domain utterances.
The data used to train the out-of-domain intent must come from the same sources as all other training data: from usage data if available; from data collection, if possible; or from individuals' best guesses as to what out-of-domain utterances users will say to the production system.
Don't ask your model to try to do too much
Some types of utterances are inherently very difficult to tag accurately. Whenever possible, design your ontology to avoid having to perform any tagging which is inherently very difficult.
For example, it is possible to design an ontology that requires the trained NLU model to use large dictionaries to predict the correct interpretation. This can happen when exactly the same carrier phrase occurs in multiple intents. For example, consider the following utterances:
- {PLAY_MEDIA} play the film [MOVIE] Citizen Kane [/] {/}
- {PLAY_MEDIA} play the track [SONG] Mister Brightside [/] {/}
- {PLAY_MEDIA} play [MOVIE] Citizen Kane [/] {/}
- {PLAY_MEDIA} play [SONG] Mister Brightside [/] {/}
In utterances (1-2), the carrier phrases themselves ("play the film" and "play the track") provide enough information for the model to correctly predict the entity type of the follow words (MOVIE and SONG, respectively).
However in utterances (3-4), the carrier phrases of the two utterances are the same ("play"), even though the entity types are different. So in this case, in order for the NLU to correctly predict the entity types of "Citizen Kane" and "Mister Brightside", these strings must be present in MOVIE and SONG dictionaries, respectively.
This situation is acceptable in domains where all possible literals for an entity can be listed in a dictionary for that entity in a straightforward manner. But for some entity types, the required dictionaries would either be too large (for example, song titles) or change too quickly (for example, news topics) for Mix to effectively model. In this type of case, the best practice solution is to underspecify the entity within NLU, and then let a post-NLU search disambiguate. In the case of utterances (3-4), underspecifying means defining an entity which can consist of either a movie or a song:
- {PLAY_MEDIA} play [QUERY] citizen kane [/] {/}
- {PLAY_MEDIA} play [QUERY] mister brightside [/] {/}
Now, the carrier phrase "play" provides the information necessary to infer that the following words are QUERY entity. (Note that Mix is able to learn that "play" by itself is likely to be followed by a QUERY, while the word sequence "play movie" is likely to be followed by a MOVIE.)
This approach of course requires a post-NLU search to disambiguate the QUERY into a concrete entity type—but this task can be easily solved with standard search algorithms.
Use a consistent naming convention
It is a good idea to use a consistent convention for the names of intents and entities in your ontology. This is particularly helpful if there are multiple developers working on your project.
There is not necessarily one right answer for this; the important thing is to plan ahead, have a systematic logical convention, and be consistent.
Here are some tips that you may find useful:
- Use all caps with underscores separating words. For example, ORDER_COFFEE for an intent, and COFFEE_SIZE and COFFEE_TYPE for entities. All caps makes the entities visually stand out clearly in annotated sentences as distinct from the sentence contents, and the underscores keep the name to a valid format while making the name easily readable.
- Use an ACTION_OBJECT or VERB_OBJECT format for intents. A lot of intents fall into this schema where an action is carried out and involves or applies to some object. Here object is used in the grammatical sense of subject-verb-object. So, for example, PAY_BILL or MESSAGE_RECIPIENT.
- Use a prefix to identify the domain for an intent, with the domain in lower case, as one word. So, for example, personalbanking_PAY_BILL. This can help to visually group related intents in Mix.nlu.
An example of a best practice ontology
The "Order coffee" sample NLU model provided as part of the Mix documentation is an example of a recommended best practice NLU ontology.
Generating data and training the initial model
If you are using a new NLU model to automate an existing application, then real (production) user utterances should be available for that application, and this usage data should be leveraged to create the training data for the initial model.
Otherwise, if the new NLU model is for a new application for which no usage data exists, then artificial data will need to be generated to train the initial model.
The basic process for creating artificial training data is documented at Add samples.
Best practices for each of these two approaches are described in separate sections below.
- Best practices around leveraging deployment usage data
- Best practices around creating artificial data
Training the initial model is documented in Train your model.
Best practices around leveraging deployment usage data
If you have usage data from an existing application, then ideally the training data for the initial model should be drawn from the usage data for that application. This section provides best practices around selecting training data from usage data.
Note that although this section focuses on selecting training data from usage data, the same best practices apply to other use cases for selecting data sets from usage data, in particular the following:
- Selecting test set data (see the section Evaluating NLU accuracy below)
- Selecting additional training data after model deployment for improving accuracy (see the section Improving NLU accuracy below)
Use uniform random sampling to select training data
Typically, the amount of usage data that is available will be larger than what is needed to train (and test) a model. Therefore, a training set is typically generated by sampling utterances from the usage data. Different sampling methods could in principle be used; Nuance recommends using uniform random sampling to select a training set from usage data. Random sampling has the advantage of drawing samples from the head and tail of the distribution in proportions that mirror real-world usage: if an utterance appears more more frequently in the usage data, then it will appear more frequently in the sampled training set. This results in the trained NLU model generally having the best accuracy on the most frequently encountered utterances.
The most obvious alternatives to uniform random sampling involve giving the tail of the distribution more weight in the training data. For example, selecting training data randomly from the list of unique usage data utterances will result in training data where commonly occurring usage data utterances are significantly underrepresented. This results in an NLU model with worse accuracy on the most frequent utterances. This is not desirable, so Nuance does not recommend this approach.
Annotate data using Mix
Obviously, training data must first be annotated with the correct intents and entities. We recommend annotating data within Mix.nlu itself. Mix has the ability to import a text file of unannotated utterances, and the Optimize tab provides a convenient UI for annotating both the intent and entities of utterances in a single view. The Optimize tab is documented at https://docs.mix.nuance.co.uk/mix-nlu/#optimize-model-development.
Before you begin to annotate, you should create an annotation guide that provides instructions on how to annotate: what types of utterances do and don't belong to each intent, and what kinds of words do and don't belong to each entity. An annotation guide provides three concrete benefits:
- It acts as a place to document decisions that are made while annotating. For example, if you have a RELATIVE_LOCATION entity and you encounter an utterance that includes "in the neighborhood", you'll need to decide whether the word "in" should be part of the entity or not. Once you have decided, you can document that decision in the guide to help ensure that future instances of "in the neighborhood(/area/etc.)" will be consistently annotated.
- It makes a single annotator's annotations more self-consistent, because the annotator doesn't need to remember all of the annotation decisions – the guide acts as a reference.
- It makes multiple annotators' annotations more consistent with each other, because all annotators will be annotating according to the same guide.
Best practices around creating artificial data
If you don't have an existing application which you can draw upon to obtain samples from real usage, then you will have to start off with artificially generated data. This section provides best practices around creating artificial data to get started on training your model.
Move as quickly as possible to training on real usage data
For reasons described below, artificial training data is a poor substitute for training data selected from production usage data. In short, prior to collecting usage data, it is simply impossible to know what the distribution of that usage data will be. For this reason, the focus of creating artificial data should be getting an NLU model into production as quickly as possible, so that real usage data can be collected and used as test and train data in the production model as quickly as possible. In other words, the primary focus of an initial system built with artificial training data should not be accuracy per se, since there is no good way to measure accuracy without usage data. Instead, the primary focus should be the speed of getting a "good enough" NLU system into production, so that real accuracy testing on logged usage data can happen as quickly as possible. Obviously the notion of "good enough", that is, meeting minimum quality standards such as happy path coverage tests, is also critical.
Bootstrap data to get started
If you're creating a new application with no earlier version and no previous user data, you will be starting from scratch. To get started, you can bootstrap a small amount of sample data by creating samples you imagine the users might say. It won't be perfect, but it gives you some data to train an initial model. You can then start playing with the initial model, testing it out and seeing how it works.
This very rough initial model can serve as a starting base that you can build on for further artificial data generation internally and for external trials. This is just a rough first effort, so the samples can be created by a single developer. When you were designing your model intents and entities earlier, you would already have been thinking about the sort of things your future users would say. You can leverage your notes from this earlier step to create some initial samples for each intent in your model.
Run data collections rather than rely on a single NLU developer
A single NLU developer thinking of different ways to phrase various utterances can be thought of as a "data collection of one person". However, a data collection from many people is preferred, since this will provide a wider variety of utterances and thus give the model a better chance of performing well in production.
One recommended way to conduct a data collection is to provide source utterances and ask survey-takers to provide variants of these utterances. There are several ways to provide variants of source utterances:
- Variants that don't change the meaning of the utterance
- Vary the carrier phrase: For example, a variant of "I want to (order a coffee)" could be "I'd like to", or possibly "Can I please"
- Replace entity literals with synonyms: For example, a variant of "big" could be "large"; a variant of "nearby" could be "in the area"
- Variants that change the meaning of the utterance
- Replace entity literals with different entity literals with different meanings: For example, the entity literal "latte" in "I'd like a latte please" could be replaced with "mocha", giving "I'd like a mocha please"
Note that even though a data collection is preferred to relying on a single NLU developer data, data collection data is still artificial data, and the emphasis should still be on deploying and getting real usage data as quickly as possible.
Collect enough training data to cover many entity literals and carrier phrases
As a machine learning system, Mix.nlu is more likely to predict the correct NLU annotation for utterances that are similar to the utterances that the system was trained on. Therefore, because you don't know in advance what your users will say to the system, the way to maximize accuracy is to include as many different kinds of utterances in the training data as possible. This means including in your training data as many different entity literals and as many different carrier phrases as possible, in many different combinations. (However, note that you don't need to include all possible entity literals in your training data. You just need enough variation so that the model doesn't begin to "memorize" specific literals. Ten different literals for each entity type is a good rule of thumb.)
Note that if an entity has a known, finite list of values, you should create that entity in Mix.nlu as either a list entity or a dynamic list entity. A regular list entity is used when the list of options is stable and known ahead of time. A dynamic list entity is used when the list of options is only known once loaded at runtime, for example a list of the user's local contacts. With list entities, Mix will know the values to expect at runtime. It is not necessary to include samples of all the entity values in the training set. However, including a few examples with different examples helps the model to effectively learn how to recognize the literal in realistic sentence contexts.
You should also include utterances with different numbers of entities. So if you have an intent which in your ontology has three entities, add training utterances for that intent that contain one entity, two entities, and three entities – at least for all combinations of entities that are likely to spoken by your users.
The amount of training data you need for your model to be good enough to take to production depends on many factors, but as a rule of thumb it makes sense for your initial training data to include at least 20 instances of each intent and each entity, with as many different carrier phrases and different entity literals as possible. So for example, if your ontology contains four intents and three entities, then this suggests an initial training data size of (4 intents * 20) + (3 entities * 20) = 80 + 60 = 140 utterances. More training data will be needed for more complex use cases; at the end of day it will be an empirical question based on how well your specific model is performing on test data (see the section Evaluating NLU accuracy below).
Note that the amount of training data required for a model that is good enough to take to production is much less than the amount of training data required for a mature, highly accurate model. But the additional training data that brings the model from "good enough for initial production" to "highly accurate" should come from production usage data, not additional artificial data.
Keep your training data realistic
There is no point in your trained model being able to understand things that no user will actually ever say. For this reason, don't add training data that is not similar to utterances that users might actually say. For example, in the coffee-ordering scenario, you don't want to add an utterance like "My good man, I would be delighted if you could provide me with a modest latte".
The best practice to add a wide range of entity literals and carrier phrases (above) needs to be balanced with the best practice to keep training data realistic. You need a wide range of training utterances, but those utterances must all be realistic. If you can't think of another realistic way to phrase a particular intent or entity, but you need to add additional training data, then repeat a phrasing that you have already used.
Training data also includes entity lists that you provide to the model; these entity lists should also be as realistic as possible. For example, in cases where you expect the model to encounter utterances that contain OOV (out-of-vocabulary) entity literals (typically entities with large numbers of possible literals, such as song titles), you will want to include training utterances that similarly contain entity literals that are OOV with respect to the entity lists. A data collection is one way of accomplishing this.
Include fragments in your training data
Don't forget to include fragments in your training data, especially because users are likely to frequently speak fragments to your deployed system. Use the predefined intent NO_INTENT for annotating fragment training data. For example:
- {NO_INTENT} [DRINK_TYPE] Italian soda [/] {/}
- {NO_INTENT} [SIZE] short [/] [DRINK_TYPE] latte [/] {/}
Include anaphora references in samples
In conversations between people, participants will often use anaphoras—indirect, generic references to a subject that was mentioned recently in the conversation. This could be a:
- Person (him, her, them)
- Place (there, here, that place)
- Thing (it)
- Moment in time (then, at that time)
For example, if a person was just talking about plans to travel to Boston soon, the person might reasonably say "I want to go there on Wednesday," or "Can you show me hotel rooms available there on Wednesday?" where there is understood implicitly from the recent context to mean Boston. Similarly, a person or people you were just talking about might be referred to with him, her, or them.
If you expect users to do this in conversations built on your model, you should mark the relevant entities as referable using anaphoras, and include some samples in the training set showing anaphora references.
For more information, see Anaphoras in the Mix.nlu documentation.
Include samples using logical modifiers
In conversations you will also see sentences where people combine or modify entities using logical modifiers—and, or, or not.
For example:
- "I would like to activate service for TV, internet, and mobile phone."
- "No, this call is not about my internet connection."
You can tag sample sentences with modifiers to capture these sorts of common logical relations.
For more information see Tag modifiers in the Mix.nlu documentation.
Make sure the distribution of your training data is appropriate
In any production system, the frequency with which different intents and entities appear will vary widely. In particular, there will almost always be a few intents and entities that occur extremely frequently, and then a long tail of much less frequent types of utterances. However, when creating artificial training data for an initial model, it is impossible or at least difficult to know exactly what the distribution of production usage data will be, so it's more important to make sure that all intents and entities have enough training data, rather than trying to guess what the precise distribution should be.
Having said that, in some cases you can be confident that certain intents and entities will be more frequent. For example, in a coffee-ordering NLU model, users will certainly ask to order a drink much more frequently than they will ask to change their order. In these types of cases, it makes sense to create more data for the "order drink" intent than the "change order" intent. But again, it's very difficult to know exactly what the relative frequency of these intents will be in production, so it doesn't make sense to spend much time trying to enforce a precise distribution before you have usage data.
Evaluating NLU accuracy
This section provides best practices around generating test sets and evaluating NLU accuracy at a dataset and intent level..
Information on testing individual utterances can be found in Test it.
There are some principles to keep in mind for evaluating your NLU model accuracy:
- Make sure the test data is of the highest possible quality
- Generate both test sets and validation sets
- Make sure you have enough test data
- Make sure the distribution of your test data is appropriate
- Use the Mix Testing Tool
- Use adjudication rules when appropriate
- Don't cherry pick individual utterances
Make sure the test data is of the highest possible quality
In this context, "high quality" means two things:
- The utterances in the test data are maximally similar to what users would actually say to the production system (ideally, the test data is made up of utterances that users have already spoken to the production system). In general, the possible sources of test data, in descending order of quality, are as follows: a. Usage data from a deployed production system b. Usage data from a pre-production version of the system (for example, a company-internal beta) c. Data collection data (for example, collected by asking people answer survey questions) d. Artificially generated data (for example, by defining grammar templates such as "I'd like a $SIZE $DRINK please" and expanding these with appropriate dictionaries for each template variable)
- The test set utterances are annotated correctly.
Generate both test sets and validation sets
When developing NLU models, you will need two separate types of data sets:
- A training set that is used to train the parameters on each refinement of the model structure.
- An evaluation set is at least partially distinct data that is held out from the training process and used to check the ability of the trained model to generalize to real data.
Whenever possible, it is best practice to divide evaluation data into two distinct sets: a validation set and a test set. The difference between the two sets is as follows:
- The validation set serves as a check of the performance of the current refinement of the model. The model can be improved based on detailed error analysis of the results on the validation set (see the section Improving NLU Accuracy below).
- The test set is only used to test the final selected model following an iterative process of refinement involving cycles of adjusting the model structure, training on the training set and evaluating using the validation set. The test set is sometimes called a "blind" set because the NLU developers may not look at its content. This keeps the data similar to utterances that users will speak to the production system in that what will come is not known ahead of time. To protect the test set as a final test of the model, the test set data may not be used for any error analysis or for improving the training data.
Once you have annotated usage data, you typically want to use it for both training and testing. Typically, the amount of annotated usage data you have will increase over time. Initially, it's most important to have test sets, so that you can properly assess the accuracy of your model. As you get additional data, you can also start adding it to your training data.
Once you have a lot of data, a fairly standard and traditional partitioning of data is an entirely random 80%/10%/10% (or 70%/20%/10%) train/validate/test split, though other partitions, such as 60%/20%/20%, are also common – it largely depends on whether the resulting test sets are large enough (see below). Note that it is fine, and indeed expected, that different instances of the same utterance will sometimes fall into different partitions.
Note that the the above recommended partition splits are for production usage data only. When you are training an initial model based on artificial data, you need enough test data (see below) in order for your results to be statistically significant, but it doesn't make sense to create a huge amount of artificial training data for an initial model. So in the case of an initial model prior to production, the split may end up looking more like 33%/33%/33%.
Some data management is helpful here to segregate the test data from the training and test data, and from the model development process in general. Ideally, the person handling the splitting of the data into train/validate/test and the testing of the final model should be someone outside the team developing the model.
Make sure you have enough test data
In order for test results to be statistically significant, test sets must be large enough. Ideal test set size depends on many factors, but as a very rough rule of thumb, a good test set should contain at least 20 utterances for each distinct intent and entity in the ontology. So the test set for an ontology with two intents, where the first intent has no entities and the second intent has three entities, should contain at least 100 utterances (2 intents + 3 entities = 5; 5 * 20 utterances = 100). Your validation and blind sets should each be at least this large.
Make sure the distribution of your test data is appropriate
The validation and test sets should be drawn from the same distribution as the training data – they should come from the same source (whether that is usage data, collected data, or developer-generated data), and the partition of the data into train/validation/test should be completely random.
Note that if the validation and test sets are drawn from the same distribution as the training data, then we expect some overlap between these sets (that is, some utterances will be found in multiple sets).
Use the Mix Testing Tool
Nuance provides a tool called the Mix Testing Tool (MTT) for running a test set against a deployed NLU model and measuring the accuracy of the set on different metrics.
For more details, speak to your Nuance representative.
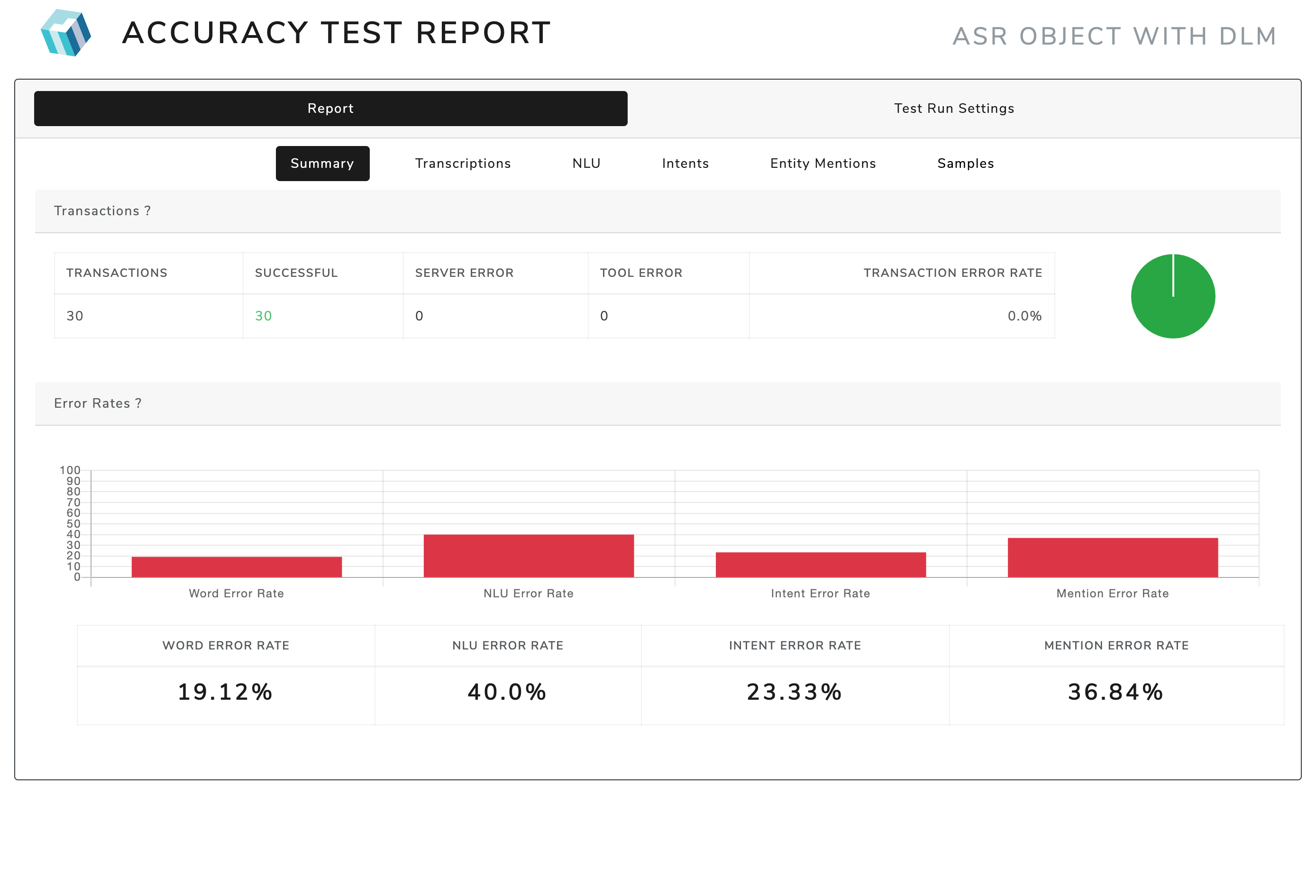 To the side, see of the output of MTT.
- Under the 'Summary' tab in the 'Error Rates' pane, you can see the NLU Error Rate, which corresponds to the full sentence accuracy, the Intent Error Rate which corresponds to the intent accuracy, and the Slot Error Rate which corresponds to the entity accuracy.
- If you click on the 'Slots' tab, you can see accuracy/error rates for each slot (entity) individually, across all intents, as well as per-intent slot error rate/accuracy.
The best overall metric of NLU accuracy is *full sentence accuracy,* which is the percentage of utterances for which the predicted intent and all predicted entity types and values exactly match the reference, or ground truth, annotation.
To the side, see of the output of MTT.
- Under the 'Summary' tab in the 'Error Rates' pane, you can see the NLU Error Rate, which corresponds to the full sentence accuracy, the Intent Error Rate which corresponds to the intent accuracy, and the Slot Error Rate which corresponds to the entity accuracy.
- If you click on the 'Slots' tab, you can see accuracy/error rates for each slot (entity) individually, across all intents, as well as per-intent slot error rate/accuracy.
The best overall metric of NLU accuracy is *full sentence accuracy,* which is the percentage of utterances for which the predicted intent and all predicted entity types and values exactly match the reference, or ground truth, annotation.
Use adjudication rules when appropriate
Adjudication rules refer to rules that are applied during evaluation to allow non-exact matches to count as accurate predictions. In some cases, there may be entities or intents that you want to have considered as equivalent, such that either counts as correct for an accuracy calculation. For example, some applications may not care whether an utterance is classified as a custom OUT_OF_DOMAIN intent or the built-in NO_MATCH intent. MTT supports adding adjudication rules for considering different intents or entities to be equivalent, as well as for ignoring entities entirely.
Don't cherry pick individual utterances
When analyzing NLU results, don't cherry pick individual failing utterances from your validation sets (you can't look at any utterances from your test sets, so there should be no opportunity for cherry picking). No NLU model is perfect, so it will always be possible to find individual utterances for which the model predicts the wrong interpretation. However, individual failing utterances are not statistically significant, and therefore can't be used to draw (negative) conclusions about the overall accuracy of the model. Overall accuracy must always be judged on entire test sets that are constructed according to best practices.
If there are individual utterances that you know ahead of time must get a particular result, then add these to the training data instead. They can also be added to a regression test set to confirm that they are getting the right interpretation. But doing this is unrelated to accuracy testing.
Improving NLU accuracy
Once you have trained and evaluated your NLU model, the next step is to improve the model's accuracy. There are two general ways of doing this:
- Collect and annotate additional data to add to the model training and testing. This additional data can come from two different sources: a. Prior to deployment, improve the model-based internal/external data collection. b. After deployment, improve the model based on actual usage data
- Conduct accuracy improvement based on error analysis of validation set accuracy.
There are some important considerations for improving NLU accuracy:
- Conduct error analysis on your validation set - but don't overfit
- Make sure your annotations are correct and consistent
- Make sure you have an annotation guide
Conduct error analysis on your validation set—but don't overfit
Conducting error analysis means going through the errors that the trained model makes on your validation set, and improving your training data to fix those errors (and hopefully related errors). In general, there are two types of validation set errors:
- Intents and entity types with no or too little training data
- Annotation errors, either in your training data or in validation set data
For errors caused by too little training data, the solution is simple: add additional training data that is similar to the failing validation set utterance. However, do not add the failing utterance itself unless it is likely to be seen frequently in production. This restriction is for helping to prevent overfitting.
Overfitting happens when you make changes to your training data that improve the validation set accuracy, but which are so tailored to the validation set that they generalize poorly to real-world usage data. It is something like fitting a curve to a set of plotted points by drawing a complicated curve that passes perfectly through every point rather than drawing a smooth, simple curve that broadly captures the overall shape of the data.
This typically happens when you add carrier phrases and entity literals that occur infrequently in a validation set to the training data, because phrases that occur infrequently in a validation set are less likely to also occur in test sets or in future usage data.
The problem of annotation errors is addressed in the next best practice below.
Make sure your annotations are correct and consistent
One important type of problem that error analysis can reveal is the existence of incorrect and inconsistent annotations, both in your training data and in your test sets. Some types of annotation inconsistencies are as follows:
- Intents: Two utterances with similar carrier phrases and meaning, but which belong to different intents. For example, if "please pay my electricity bill" and "I want to pay my water bill" is tagged with different intents, then this is likely an annotation inconsistency since in both utterances the user is attempting to pay a bill.
- Different/missing entities: Two utterances that contain similar words with similar meanings, but where the words are tagged as an entity in one utterance and as a different entity, or as no entity at all, in the other utterance. For example, in the following pair, the word "large" is tagged as SIZE in the first utterance, but in the second utterance, the similar word "short" is (incorrectly) tagged as part of the DRINK_TYPE entity:
- {ORDER} I would like a [SIZE] large [/] [DRINK_TYPE] latte [/] {/}
- {ORDER} I want a [DRINK_TYPE] short mocha [/] {/}
- Entity spans: Two utterances that contain similar words tagged with the same entity, but where the tagged entities span inconsistent sequences of words. For example, given the words "in five minutes" and a DURATION entity, one utterance might be tagged "[DURATION] in five minutes [/]" while the other is tagged "in [DURATION] five minutes [/]".
Often, annotation inconsistencies will occur not just between two utterances, but between two sets of utterances. In this case, it may be possible (and indeed preferable) to apply a regular expression. This can be done by exporting a TRSX file from Mix, running the regular expression on the TRSX file, and then re-uploading the corrected TRSX into the same Mix project (after deleting all data from the project to get rid of the inconsistently annotated data).
Note that since you may not look at test set data, it isn't straightforward to correct test set data annotations. One possibility is to have a developer who is not involved in maintaining the training data review test set data annotations.
Make sure you have an annotation guide
The problem of incorrect and inconsistent annotations can be greatly alleviated by maintaining an annotation guide that describes the correct usage for each intent and entity in your ontology, and provides examples. A good annotation guide acts as a rule book that standardized annotations across multiple annotators. In particular, an annotation guide provides two benefits:
- In any data set that contains real usage data, it will occasionally be unclear what the correct annotation for a particular utterance is. The annotation guide contains appropriate guidelines. If guidance doesn't already exist for that type of utterance, then once the correct annotation is decided, new guidelines can be added to the guide.
- The annotation guide helps to make sure that different people annotate in the same fashion.
As one simple example, whether or not determiners should be tagged as part of entities, as discussed above, should be documented in the annotation guide.
Summary: Dataset life cycle
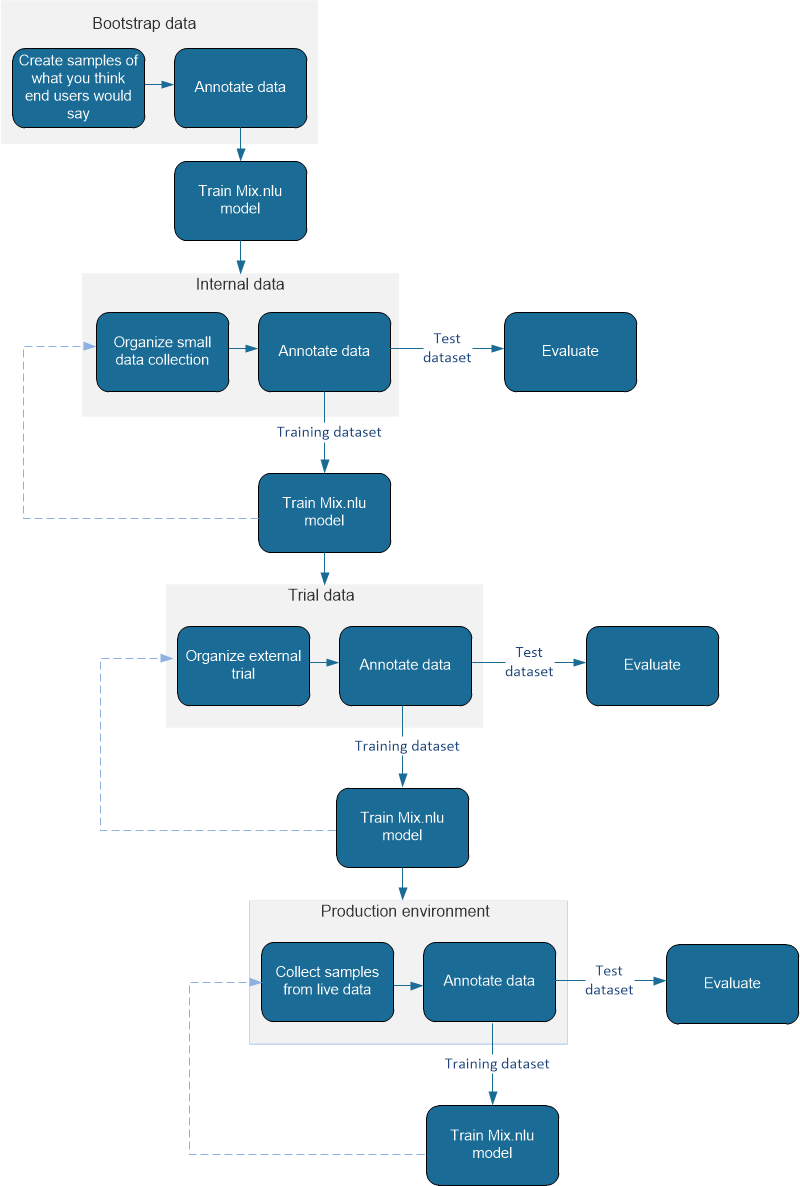
The following diagram visually summarizes the general steps involved in iteratively building a dataset and NLU model.
FAQ
Ontology design
Q: If I'm considering using two separate entities that have a great deal of overlap (greater number of members in intersection than not, say), is it best to merge them into one entity to avoid redundancy? Or better to keep separate to guarantee integrity of generated examples?
A: In general, it is better to keep them separate. But be mindful of the kinds of sentences in which these occur - are these identical or nearly so? If so, it may make sense to combine.
Over-generation
Q: How much does overgeneration of examples hurt?
A: In test data, you absolutely do not want to over-generate (i.e. use a grammar that generates unrealistic utterances), since you want the test data to maximally match what the system will encounter in production.
For training data, some over-generation is acceptable. It is unknown exactly how much unrealistic training data can be added before the performance of the model begins to degrade, but as a rule of thumb, try to limit over-generated/unrealistic data to no more than 20% of training data.
Entity spans
Q: Does it ever make sense to include full noun phrases (preceding determiner, adjective etc.) in an entity? For example:
{OPEN_INSURANCE_POLICY} I want to get insurance for [INSURED_OBJECT] my new car [/] {/}
vs.
{OPEN_INSURANCE_POLICY} I want to get insurance for my new [INSURED_OBJECT] car [/] {/}
A: Whether a determiner is included in the an entity is a decision that needs to be made for each project and documented in the annotation guide. However, in general, it is probably better to leave determiners out of entities, simply because they are not necessary to understand the meaning of the entity, and it is often possible for different determiners (or no determiners) to precede an entity.
As for adjectives like "new" in the example above, the question is whether the notion of a "new car" is important to the overall application. For example, if you are booking a space on a ferry, the application logic will be the same so matter how old the car is, so the NLU doesn't need to capture it. But if you are applying for car insurance, then the age of the car is very important to the business rules that decide how much the insurance will cost. But in this case, it's easy to imagine a user saying not just "new car", but also "old car", "new truck", "old motorcycle", and so on. Given this ability to combine different ages and insured objects, it would be more efficient (both for the NLU model and for downstream processing) to create a second entity [AGE] : "my [AGE] new [/] [INSURED_OBJECT] car [/]".
Literal-to-value mappings
Q: When is it appropriate for the literal and value in entity {literal, value} pairs to be identical, and when should they differ? Can/should the literal→ value mapping be used to provide more fine-grained information? For example, consider entity type PAYMENT_METHOD for an intent PAY_BILL—we want to know whether the user will pay by credit card, check, or money order. Here are two example utterances:
- Pay my bill by credit card
- Pay my bill by Mastercard The value for the literal "credit card" should be simply "credit card". But since a Mastercard is a kind of credit card, should the value for "Mastercard" be "mastercard", or should it be something like "credit card.mastercard"?
A: Values exist primarily because there are often different ways to express the same entity value. For example, "big" and "large" both mean the same thing, so these two literals should map to the same value (which could be either "big" or "large"). But it doesn't actually matter what the string of the value is, as long as it is unique – instead of "big" or "large", it could just as easily be "arcfrgu" – but this would make the NLU model and downstream application logic harder to understand. So from this point of view, it doesn't matter what the value associated with a literal is. However, the specific value "credit card.mastercard" is problematic because the dot implies that the value has internal structure, but it doesn't—it is simply a text string. The NLU model doesn't need to know or care that a Mastercard is a kind of credit card—and downstream processing will have to know in any event. So "mastercard" is the better value here.