
Mix tips for IVR developers
This document provides tips for IVR developers and points out important factors to consider when creating your Mix project, designing your Mix.dialog conversations, and when using the Dialog as a Service runtime API.
Create a project in Mix
This section describes how to choose channel, modalities, and engine pack versions for IVR projects.
Channel and modalities
When creating a project in Mix you specify the communication channels you intend to support. The predefined channels have recommended modalities preselected for you but you can customize the channels to suit your needs. You can even create and name your own custom channel.
Mix offers three project templates with default channels and modalities. For example, the IVR (Interactive Voice Response) predefined channel is meant to support the classic interactive touchtone telephone system using voice and DTMF, with prerecorded audio files for prompts (called messages in Mix.dialog).
A modality specifies a format used to exchange information with users, such as text-to-speech (TTS), audio, text, and so on. Modalities determine the options that are available for a channel in Mix.dialog. For example, if you select the DTMF modality, you will be able to map DTMF keys to entity values in the DTMF properties of question and answer nodes. If you don’t select the DTMF modality for any of the channels in your project, these properties will not be available, nor will any DTMF-related settings appear in the Project Settings panel for your project.
Consider the following factors when making your modality selections for an IVR project:
- If your application will be using recorded prompts, make sure Audio Script is selected. Select this option if you intend to use prerecorded messages, including messages dynamically assembled from smaller prerecorded audio files using dynamic concatenated audio, with or without backup text to be rendered using TTS.
- If your application will rely on speech synthesis (text-to-speech), make sure TTS is selected. The TTS modality enables the TTS streaming feature of the Dialog service.
- If your application will be DTMF-enabled, make sure DTMF is selected. The DTMF modality provides support for Dual-Tone Multi-Frequency tones as user input.
Unless you're creating an omnichannel project, you can skip Rich Text and Interactivity:
- Rich text lets you specify text messages that can be displayed on any screen, such as SMS messages. It also provides the ability to include richer content in messages, such as HTML tags that can be used in a web chat.
- Interactivity lets you add interactive elements to your dialog design, such as buttons and clickable links.
Once you have specified the channels and modalities for your project, you must select a use case (General is the default), followed by the languages you wish to support. The available languages depend on the selected use case. For more information, see Create a project.
Engine packs
When creating a project in Mix you must select the engine pack version that corresponds to the engines installed in your self-hosted environment.
This ensures that the resources generated for your project (ASR DLMs, NLU models, and Dialog models) are compatible with the engine versions you have installed. The engine pack version also determines the tooling features you can access. In the Mix tools, features introduced in a later engine pack version are not available until you upgrade to the engine pack version supporting these new features. This ensures that changes introduced in any hosted engines in the Mix runtime environment will not impact existing projects.
An engine pack version includes a major and a minor version number. Speech Suite 11 is only compatible with the 2.x releases of engine packs. To determine which specific engine pack version to use, select the version corresponding to your installed engines.
For the list of engine packs available for Speech Suite deployments, see Speech Suite.
If you are creating a project in Mix that needs to be deployed to an IVR environment with Speech Suite 11 (11.0.9 and up) and the Nuance Dialog engine—whether these components are self-hosted or Nuance-hosted (Nuance-Hosted IVR)—you need to select an engine pack that matches the versions of Speech Suite and Dialog engine installed in the IVR environment.
For example, consider the following Speech Suite 11 deployment:
- NVE 21.06.0 (aligns with TTS 21.06)
- Krypton 4.8.1 (aligns with ASR 4)
- NLE 4.9.1 (aligns with NLU 4)
- Dialog 1.1 with VoiceXML connector 1.1 (aligns with Dialog 1.1)
For this deployment, you would select the 2.0 engine pack.
To determine your installed engine versions and recommended engine pack version to select for your project:
- For self-hosted IVR deployments with SpeechSuite 11, see the release notes for your version of Speech Suite and VoiceXML Connector.
- For Nuance-Hosted IVR deployments, please work with your Program Delivery Team Leads to find out the version of Speech Suite and the VoiceXML Connector.
For more information about engine packs, see Manage engine packs and data packs.
Prepare audio and grammar files
In order for the application to retrieve audio and grammar files at runtime, you must place the files in specific directories relative to the client application.
Prerecorded messages
The expected location for prerecorded audio files follows this format:
basePath/language/prompts/library/channel/
Where:
- basePath is the path to where the client application expects to find all required language-specific material (audio files and grammars); for example,
http://webserver:8080/myContent - language is a directory named after the appropriate short language code (for example,
en-US,fr-CA) - The constant name
prompts(to allow you to store grammars on the same server - library is the value
default(advanced customization reserved for future use) - channel is the name of the channel with any non-alphanumeric characters stripped (for example,
IVRVoiceVA, notIVR/Voice VA)—usedefaultfor audio files that apply to all channels
Mix.dialog can generate filenames for your messages. When Mix builds the Dialog model for an application, it uses Audio File ID as the base filename for messages. If Audio File ID is not defined, Mix falls back to Message ID. For more information, see Add a message for your project.
The filename extension—.wav (default), .vox, or .ulaw—is set in your project settings.
VoiceXML Connector automatically appends the version query parameter, which refers to a specific Dialog build. (Mix generates a unique version number for each deployment.) Example: http://webserver:8080/myContent/en-US/prompts/default/IVRVoiceVA/promptName.wav?version=1.0_123456789
In the absence of a new Dialog build, VoiceXML Connector lets you explicitly specify version with an arbitrary value to make sure your VoiceXML application uses the latest version of a resource—in this case, an audio file—instead of any cached version. For more information, refer to the VoiceXML Connector documentation.
Dynamic message references
Dialog designs that support the Audio Script modality also support dynamic audio file references in messages. Rather than have the message point to a fixed audio file, a data access node is used to retrieve a reference to an audio file, whether from the client application, or from an external data store or endpoint. For more information, see DynamicMessageReference schema.
Dynamic messages
Mix.dialog gives you the flexibility to use HTML markup in Rich Text messages, and SSML tags in TTS and Audio Script messages. You can also create dynamic messages by adding placeholders (annotations) to be replaced at runtime based on what the user said or other circumstances. See Dynamic messages for more information.
Use the same directory structure as described above. For a message that contains dynamic data along with static text, the Dialog build references separate audio files with a suffix, such as _01, _03, and so on, appended to the base filename.
Runtime representation of a dynamic message for audio playback
"audio": [{
"text": "Adding ",
"mask": false,
"bargeInDisabled": false,
"uri": "en-US/prompts/default/IVRchannel/Report_quantity_added_ini_01_01.wav?version=preview_1.0_1634153564362"
}, {
"text": "",
"mask": false,
"bargeInDisabled": false,
"uri": "en-US/prompts/default/IVRchannel/cpr/silence.natnum.precpr.wav?version=preview_1.0_1634153564362"
}, {
"text": "",
"mask": false,
"bargeInDisabled": false,
"uri": "en-US/prompts/default/IVRchannel/cpr/silence.global.natnum.wav?version=preview_1.0_1634153564362"
}, {
"text": "5",
"mask": false,
"bargeInDisabled": false,
"uri": "en-US/prompts/default/IVRchannel/cpr/m.natnum.units05.wav?version=preview_1.0_1634153564362"
}, {
"text": "",
"mask": false,
"bargeInDisabled": false,
"uri": "en-US/prompts/default/IVRchannel/cpr/silence.global.natnum.wav?version=preview_1.0_1634153564362"
}, {
"text": "",
"mask": false,
"bargeInDisabled": false,
"uri": "en-US/prompts/default/IVRchannel/cpr/silence.natnum.postcpr.wav?version=preview_1.0_1634153564362"
}, {
"text": " units to your order",
"mask": false,
"bargeInDisabled": false,
"uri": "en-US/prompts/default/IVRchannel/Report_quantity_added_ini_01_03.wav?version=preview_1.0_1634153564362"
}
]
For example, consider this audio script message, and its runtime representation on the right:
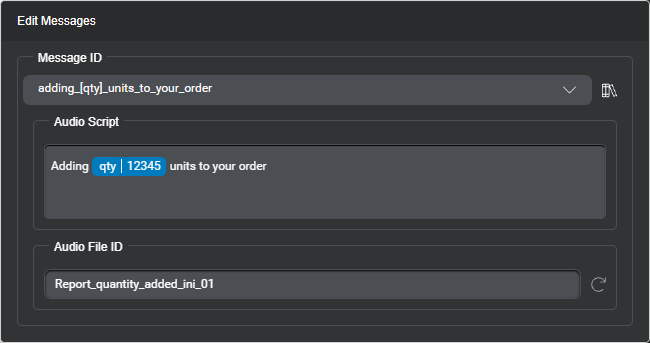
At runtime, the Dialog service represents this dynamic message in separate parts:
- The first part references a recorded audio file for the start of the message.
- Other parts reference silence audio files, and a recorded audio file for the value of
qty(“5”, in this example), to be fetched from the appropriated dynamic concatenated audio package. - The last part references a recorded audio file for the end of the message.
See Message actions, in the Dialog as a Service gRPC API documentation, for more information.
Dynamic concatenated audio packages
Annotations that represent variables or entities of certain types (date, time, temperature, and so on) support output formatting. At runtime, some VoiceXML applications can play Audio Script messages by using audio files identified in a package via the proprietary Nuance CPR algorithm for dynamic concatenated audio. If a recorded audio file cannot be found in the recorded audio package, TTS playback is used as a fallback. References to files located in dynamic concatenated audio packages have the same format with the addition of the /cpr subdirectory before the prompt name, as shown in this example:
http://webserver:8080/myContent/en-US/prompts/default/IVRVoiceVA/cpr/silence.global.date.wav?version=1.0_123456789
For more information, including on the formatting options available for the Audio Script, TTS, and Rich Text modalities, see Output formatting options. Note that support for dynamic concatenated audio is limited to specific languages.
Grammars for recognizing speech input
Mix supports uncompiled (.grxml) and precompiled (.gram) grammar file formats. Grammar files must be placed in specific directories, relative to the client application, following a similar pattern to audio files:
basePath/language/grammars/channel/filename
Where:
- basePath is the path to where the client application expects to find all required language-specific material (audio files and grammars); for example,
http://webserver:8080/myContent - language is a directory named after the appropriate short language code (for example,
en-US,fr-CA) - The constant name
grammars(to allow you to store audio files on the same server) - channel is the name of the channel with any non-alphanumeric characters stripped (for example,
IVRVoiceVA, notIVR/Voice VA) - filename is the name of the external grammar file
VoiceXML Connector automatically appends the version query parameter, which refers to a specific Dialog build. (Mix generates a unique version number for each deployment.) Example: http://webserver:8080/myContent/en-US/grammars/IVRVoiceVA/myGrammar.grxml?version=1.0_12345689
In the absence of a new Dialog build, VoiceXML Connector lets you explicitly specify version with an arbitrary value to make sure your VoiceXML application uses the latest version of a resource—in this case, a grammar—instead of any cached version. For more information, refer to the VoiceXML Connector documentation.
DTMF mappings and DTMF grammars
For IVR dialogs, you can also define mappings to handle DTMF input. You can either define the mappings in Mix.dialog or use a DTMF grammar file. See the section below for some advice. Place DTMF grammar files in a directory relative to the client application, the same as for speech recognition grammar files.
Use and manage grammars
Whether you're using Mix.nlu to recognize the caller's request or response, a Nuance Recognizer speech grammar (.grxml or .gram), DTMF, or a combination, VoiceXML Connector converts this into a <grammar> tag for your application. Mix.dialog provides the flexibility to handle different combinations of models and grammars, at any question and answer nodes in your dialog design.
For example, you might use:
- DTMF with Mix ASR/NLU resources (default methods for intent and entity recognition)
- Nuance Recognizer speech grammars (NR grammars) for directed dialog, without support for intent switching, to recognize and parse:
- entity in focus and commands
- confirmation
- NR grammars and DTMF
- DTMF only
| Scenario | Example use cases | Enabling for entity collection and confirmation | Command handling |
|---|---|---|---|
| ASR/NLU models only | NLU collection (intent and entities) | Default, no actions required. | Commands must be part of the NLU model. See Configure global commands. |
| ASR/NLU models, and DTMF | Menu-type collection, or simple input | See Enable DTMF. | Speech commands must be part of the NLU model.DTMF mappings can be specified in Mix.dialog, or through an external DTMF grammar. |
| NR grammar only | Alphanumeric collection, or complex speech-only recognition | See Enable Nuance Recognizer grammars. | Speech commands must be defined in an external grammar, and also configured in Mix.dialog. |
| NR grammar, and DTMF | Collecting strings of digits, or reusing grammars from an existing IVR project | See Enable Nuance Recognizer grammars and Enable DTMF. | Speech commands must be defined in an external grammar.DTMF mappings can be specified in Mix.dialog, or through an external DTMF grammar. |
| DTMF only | Language selection | See DTMF-only input states | DTMF mappings can be specified directly in Mix.dialog, or through an external DTMF grammar. |
Enable Nuance Recognizer grammars
Turn on Reference speech grammars in nodes for the appropriate channels in your project settings, and then specify the required speech grammars for entity collection (and for command overrides, if needed), in the desired question and answer nodes.
A question and answer node that collects an entity for which a Nuance Recognizer built-in grammar exists can reference the built-in speech grammar in a similar fashion. In such cases, the grammar reference is a URI specifying the type and name of the built-in grammar, any desired parameters, and the name of the entity being collected. For example, the node that collects an entity called ACCOUNT_NUMBER (based on nuance_CARDINAL_NUMBER) as a 7-digit string can reference the built-in digits speech grammar as:
builtin:grammar/digits?length=7;entity=ACCOUNT_NUMBER;
Where grammar indicates that we’re using a speech grammar, digits is the name of the desired built-in grammar, and ACCOUNT_NUMBER is the name of the entity to collect.
This requires VoiceXML Connector 0.17 or later. Refer to your Speech Suite documentation for more information on built-in grammars.
If you wish to support speech interaction at confirmation turns, see Specify grammars for confirmation.
Note that you can also specify speech grammar files for commands, in which case you must also specify a speech grammar for the entity in focus, at every question and answer node that must support command entity values.
Enable DTMF
Prerequisite: Your Mix project must have a channel that supports DTMF interaction. See Manage targets, for more information.
The ability to reference DTMF grammar files in question and answer nodes is enabled by default, in your project settings, for channels that support DTMF.
Any question and answer nodes can reference external DTMF grammars files: see Specify grammars.
A question and answer node that collects an entity for which a Nuance Recognizer built-in grammar exists can reference the built-in DTMF grammar in a similar fashion. In such cases, the grammar reference is a URI specifying the type and name of the built-in grammar, any desired parameters, and the name of the entity being collected. For example, the node that collects an entity called ACCOUNT_NUMBER (based on nuance_CARDINAL_NUMBER) as a 7-digit string can reference the built-in digits DTMF grammar as:
builtin:dtmf/digits?length=7;entity=ACCOUNT_NUMBER;
Where dtmf indicates that we’re using a DTMF grammar, digits is the name of the desired built-in grammar, and ACCOUNT_NUMBER is the name of the entity to collect.
This requires VoiceXML Connector 0.17 or later. Refer to your Speech Suite documentation for more information on built-in grammars.
For question and answer nodes that collect a list entity, you can also set DTMF mappings directly in the node, if desired. VoiceXML Connector can interpret DTMF input based on the dtmf_mappings information in the ExecuteResponse payload, without the need for an external DTMF grammar reference. See RecognitionSettings, in the Dialog as a Service gRPC API documentation, for more information.
In your project settings, you can specify a global DTMF grammar to support DTMF interaction at confirmation turns, see Specify grammars for confirmation.
Note that you can also specify DTMF grammar files for commands.
Set global properties and behaviors
Speech settings example
Timeout-related settings example for speech interaction
DTMF settings example
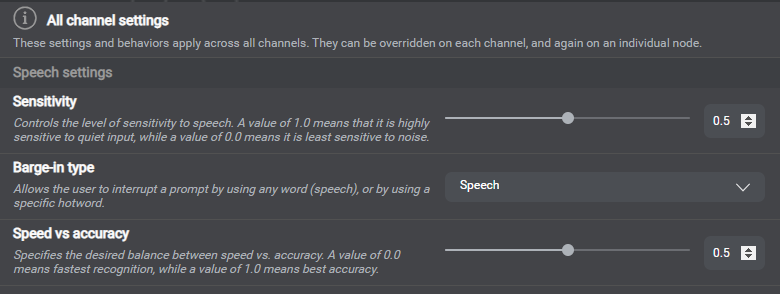
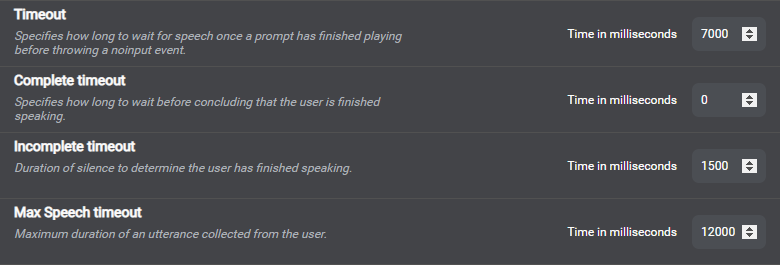
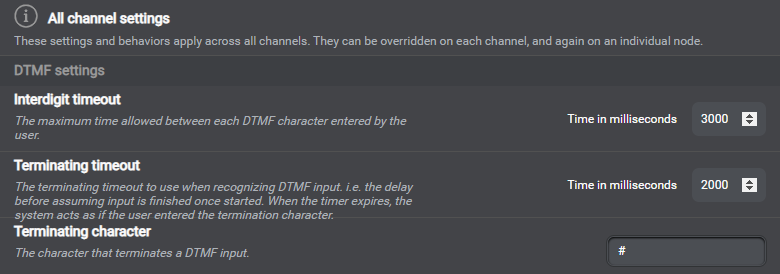
Use the Project Settings panel of Mix.dialog to define settings and behaviors that determine how your application handles commands and events, as well as collection, confirmation, and recovery. See Global settings and behaviors. You can set most parameters globally, for all channels; some are also, or only, available for specific channels, or for specific entities. Some settings are also available at the node level, for question and answer nodes and message nodes, or at the message level.
Note the limitations associated with some VoiceXML configuration parameters. This table shows VoiceXML parameters applicable to speech interaction, and their Mix.dialog equivalent:
The table below shows VoiceXML parameters applicable to DTMF interaction, and the corresponding settings in Mix.dialog. These settings are available in Mix.dialog under the DTMF settings category:
- For All channels (global scope)
- At the channel level, for channels that support DTMF
- At the entity level, for channels that support DTMF
- At the node level (for question and answer nodes)
| VoiceXML parameter | Mix.dialog setting |
|---|---|
interdigittimeout |
Interdigit timeout |
termtimeout |
Terminating timeout |
termchar |
Terminating character |
The required TTS language and voice should be installed in the environment and referenced in the appropriate document for your environment. Refer to the VoiceXML Connector documentation for more information.
Understand confidence evaluation
Confidence thresholds example for collection turns
Confirmation strategy, and confidence threshold for confirmation turns
Confirmation strategy type example for a specific entity
Confidence thresholds example for a specific entity
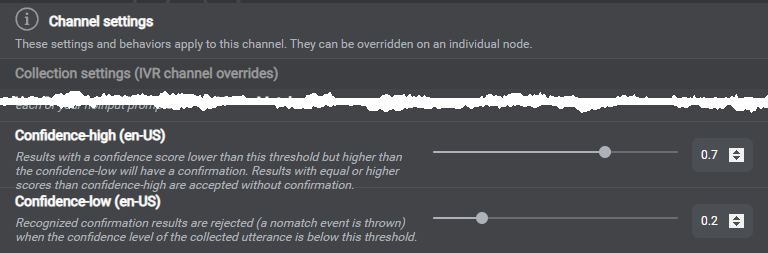
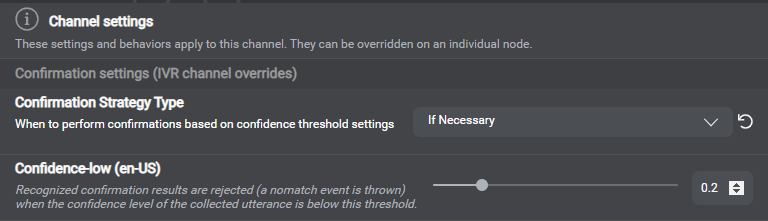
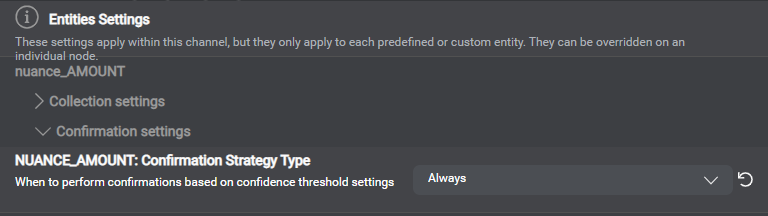
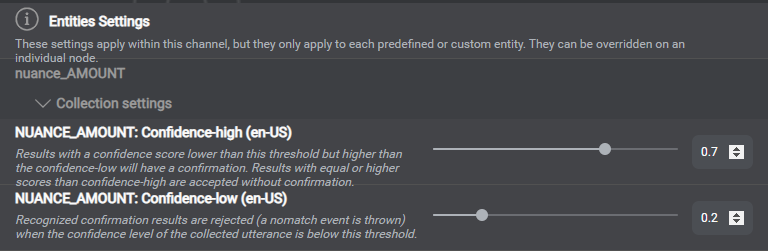
At runtime, the Dialog service handles confidence scores that VoiceXML Connector relays from your recognition engine (Nuance Recognizer or Dragon Voice) along with recognition results. When there are multiple results, the Dialog service chooses the best one, based on context and confidence score. The Dialog service then uses the applicable Confirmation strategy type, Confidence-high threshold, and Confidence-low threshold, to evaluate whether to accept the result, reject it, or elicit a confirmation turn. In Mix.dialog, you can find the thresholds and confirmation strategy types in your project settings.
At collection turns:
- If the confidence score of the collected utterance is lower than the Confidence-low threshold, the recognition result is rejected without confirmation. This generates a nomatch event.
- If the confidence score of the collected utterance is lower than the Confidence-high threshold but higher than Confidence-low, confirmation is triggered, unless the confirmation strategy type is Never, in which case the result is accepted without confirmation.
- If the confidence score of the collected utterance equals or is higher than the Confidence-high threshold, the recognition result is accepted without confirmation.
At confirmation turns, if the confidence score of the collected utterance is lower than the applicable Confidence-low threshold, the recognition result is rejected, and this generates a nomatch event.
The global confirmation strategy type is Never, by default. You can change the global strategy, or set a different confirmation strategy for specific channels, or for specific entities. You can also set confidence thresholds by language, for collection or for confirmation, for specific channels, or for specific entities.
Handle escalations
In your dialog design, you can use external actions nodes set up for a transfer action, to pass information to your VoiceXML application. When your application transfers the user to a live agent, it can make this information available for the agent, for example.
Use throw event actions, in question and answer nodes, message nodes, or decision nodes, to throw custom events, or global command events when you want to handle a situation the same way as the corresponding global command. For example, at the point in your dialog flow, where you want to transfer the user to a live agent, you can set a throw event action to throw the Escalate event.
Configure event handlers to catch error events, command events, or events thrown via throw event actions. The destination for an event handler can be an external actions node. It can also be a node of any type, which you might use to catch the event and perform additional logic before transitioning to the external actions node that will trigger the transfer action.
At runtime, VoiceXML Connector relays all the variables from the external actions node's Send Data parameters, to your VoiceXML application. Eventually, the application returns information, which VoiceXML Connector relays to the Dialog service. Depending on the outcome of the transfer action, the Dialog service will follow the success path (user has been transferred successfully), or the failure path (user could not be transferred), in your dialog flow.
Limitations
This section lists current limitations and feature gaps to consider when using Mix for a VoiceXML application.
Messages/prompts
- Latency messages used in a VoiceXML application cannot be dynamic—each latency message is limited to one audio file. See Play message on hold.
- IVR applications using Nuance Speech Suite with VoiceXML Connector require VoiceXML Connector 1.1 or later to support the data latency fetching properties and the continue action interaction for server-side fetching. See Data access actions and Continue actions for more information.
Global commands
- If your dialog design uses an external speech grammar for global commands, question and answer nodes that are configured to support NLU won’t recognize commands at runtime.
Workaround: Specify a speech grammar for the entity in focus at every question and answer node that must support commands. - The global command entity for your dialog design cannot be a rule-based entity.
External resources
- Wordsets: Projects using the Speech Suite platform only support inline wordsets (see Dynamic list entities). External NLU and ASR precompiled resources (including compiled wordsets) are not yet supported.
- Location of recorded audio files and external grammars: For a given language and channel combination, all required audio files, must be collocated in a single, flat folder. Likewise, all required external grammar files must be collocated in a single folder.
Workaround: If your audio and grammar resources are organized in a hierarchical folder structure—for example, if you have global resources in one folder, and application-specific resources in various folders, move them into the expected folder structure, as described in Prerecorded messages, and Grammars for recognizing speech input.
Recognition/interpretation
- Freeform entities: VoiceXML applications that use Speech Suite can’t yet support collecting freeform entities.
- Disambiguation: Mix doesn’t yet allow constraining recognition to a subset of intents, in open dialog.
Workaround: Use directed dialog (Nuance recognizer grammars) for disambiguation. (Note that directed dialog doesn’t support intent switching.) - Recognition parameters: Dragon voice doesn’t support hotword detection, speed vs. accuracy, and complete timeout. See Set global properties and behaviors, for more information.
- Confidence scores: Entity confidence scores from ASR/NLU models are not accurate.
Workaround: Use the corresponding intent confidence scores. Refer to Last interpretation specification for more information. - Formatted literal: VoiceXML applications that use Speech Suite for speech recognition (as opposed to ASR as a Service) require VoiceXML Connector 1.1 or later to support a formatted literal form of entities and intents from interpretation results.
- DTMF-only input states: Mix.dialog doesn’t let you set up question and answer nodes to only accept DTMF input.
Workaround:- Create a variable with the name property_inputmodes.
- Set its value to
dtmf. - Pass it as a Send Data parameter at the desired question and answer nodes.
See Enable DTMF, and Send data to the client application.
Voices/languages
- Speech Suite 11 doesn’t support switching to another language after the first NLU/ASR recognition. Specific configurations might allow some language switching after the first recognition. Contact your Nuance representative for details.
Workaround: In Mix.dialog, make sure the question and answer node that asks the user to choose a language is the first question and answer node in your dialog flow, and have it reference an external Nuance Recognizer grammar or a DTMF menu. Then, set the language variable to the appropriate language code. At runtime, the Dialog service uses this variable to return the appropriate recorded audio file paths, grammar file paths, and verbiage, for the specified language. - A VoiceXML application that uses TTS to render messages doesn’t automatically switch to the appropriate TTS voice, when the user chooses to continue in another language. This is outside the scope of the Dialog service.
Workaround: Pass the language variable as a Send Data parameter at the next question and answer nodes after the language change, and handle the logic on the client side so that VoiceXML Connector can use this to generate avxmltag with the desired language code (assuming the voice platform supports a single voice per installed language). For example:
<vxml version="2.1" xmlns="http://www.w3.org/2001/vxml" xml:lang="en-US"> - Mix doesn’t support using multiple TTS voices for the same language.
- Languages, TTS voices, and customizations are limited to those available in your Speech Suite installation.
Try mode
The Try mode supports rudimentary testing of IVR dialogs. For complete testing, you need to deploy your VoiceXML application, and test it with VoiceXML Connector.
- In Mix.nlu and Mix.dialog, the Try mode doesn’t support speech input. Interpretation results and confidence scores exposed in Try mode apply to text input, and are therefore not relevant.
- In Mix.dialog, the Try mode doesn’t support:
- DTMF interaction
- External grammar references
- Audio messages (recorded or TTS)
FAQs
This section answers common how-to questions.
Specify DNIS and ANI
When your IVR application invokes the dialog model, it can pass on the caller’s DNIS and ANI information (retrieved from telephony) to the dialog model for reporting purposes. Your dialog design can refer to this information through these fields of the userData predefined variable:
systemId(DNIS)userChannelId(ANI)
See Exchanging session data, in the Dialog as a Service gRPC API documentation, for more information.
Enable hotword detection
Nuance Recognizer supports hotword detection. To enable hotword detection, set Barge-in type to hotword, at the appropriate level, in Mix.dialog.
Mark data as sensitive
For applications involving information that must be masked in application logs, Mix.dialog lets you mark specific entities and variables as sensitive. In the StartRequestPayload of your client application, set suppress_log_user_data to True, to disable logging for ASR, NLU, TTS, and Dialog. For more information, see:
- Disabling logging
- Mark an entity as sensitive
- Mark a variable with a reporting property
- Mark a field as sensitive in a schema
Handle noinput or hang-up events
Your dialog design can handle situations such as when a caller doesn't speak or hangs up. Create event handlers to catch the predefined events MaxNoinput, and UserDisconnect, at the appropriate level. When a caller hangs up, this generates a UserDisconnect event. When your application has prompted a caller for the same piece of information for the maximum applicable number of times (default is 3), without eliciting any response, this generates a MaxNoinput event. You can set Maximum number of no inputs to the desired value, in the Collection settings category (global, channel level, entity level, node level). For more information, see:
- Manage events
- Configure global or component-level event handlers
- Configure node-level event handlers
- Collection settings
Play message on hold
For any data access nodes in your dialog design, you can set a message to be played while the caller is waiting for a backend system to return the desired data, and specify when to start playing the message, and for how long. For more information, see Specify a latency message, in the Mix.dialog documentation.
Export a grammar specification document
See Manage grammars, for a detailed description of the grammar specification document and how to export it from Mix.dialog.
Generate filenames for the Audio Script modality
Mix.dialog can automatically generate static filenames for all messages in your dialog design. You can also generate a filename for individual messages. You cannot generate a filename for messages that are not used. However, you can enter one manually (maximum 255 characters), if desired.
- In the message editor, or in the Messages resource panel, use the Generate icon
 , to generate a static filename for the message in focus.
, to generate a static filename for the message in focus. - Click Audio File IDs, in the upper-right corner of the Messages resource panel to generate static filenames for all messages where Audio File ID is still blank.
When you build your dialog model, if a message requires multiple audio files, Mix appends a suffix to the static filename based on the order in which the separate files are to play. If there are messages for which Audio File ID is blank, Mix generates filenames based on Message ID instead. The filename extension—.wav (default), .vox, or .ulaw—is set in your project settings, for all channels or for individual channels that support the Audio Script modality.
For more information, see:
Pass in VoiceXML parameters
For some VoiceXML parameters, there are no equivalent settings or node properties in Mix.dialog. If you want to set such a parameter in your dialog design, you can create a variable with the same name as the VoiceXML parameter, set it to the desired value, and pass it on to your client application as a Send Data parameter, via a data access node, external actions node, or question and answer node. Alternatively, you might prefer setting some VoiceXML properties in the stub application that invokes your dialog model.
Download configuration files and models
For VoiceXML applications, Mix lets you download NLU, ASR, and Dialog models, along with configuration files that will allow you to deploy your models to a self-hosted environment, as required. See Download models for an application configuration, for details.
Change log
Below are changes made to the Mix tips for IVR developers documentation.
2022-08-05
Updated Channel and modalities, Enable DTMF, and Limitations, to reflect the ability to add, modify, and disable channels after a Mix project has been created
2022-06-06
Added Download configuration files and models
2021-11-22
Added Engine packs to describe how to select an engine pack version for IVR projects
2021-10-13
Updated Dynamic messages to reflect the ability to apply TTS output formatting for Audio Script messages in Mix.dialog
2021-09-28
Updated FAQs and Limitations to reflect that it is now possible to specify, directly in your dialog design, latency messages (messages on hold) to play while data access operations are pending
2021-08-23
Added FAQs
2021-08-18
Added Limitations