Creating and Annotating Datasets for Optimal Accuracy
High-accuracy applications depend on the datasets that you use to train your Mix.nlu model. The more your training dataset reflects what your users will say when they are interacting with your application in the real world, the higher the accuracy of your model will be.
But this is a chicken and egg problem: How can you get real data if you are just starting to build your application?
This document describes a recommended approach to get you started with an initial dataset and improve it as your application evolves. It first goes over the main entities for defining an ontology and then provides guidelines for developing datasets for your Mix application.
Defining your ontology
Each project needs an ontology, which contains two main kinds of nodes that are used in the project: intents and entities.
- Intent nodes represent the global meaning of the entire sentence. For example, the intent BOOK_TICKET might correspond to the sentence “book two tickets for tomorrow”. Nuance recommends that you start by defining a list of groups into which the input sentences will be classified. The set of intents is determined by the business needs of the application. Once the main intents are defined, you can proceed to define the entities that are relevant for these intents.
- Entity nodes are used to identify the pieces of information pertinent for the intent. In the book ticket example above, the entity DATE can be used to identify “tomorrow”. Entities are also used to annotate words within a sentence. For example: “book two tickets for [DATE] tomorrow [/]”.
Each intent has a set of semantic roles that define the set of entities that apply to this intent. For example, the intent BOOK_TICKET could have the following semantic roles: DATE, DESTINATION, NUMBER_OF_PASSENGER, etc. Entities can also be linked to each other using two main relations, has_A and is_A:
- The has-A relation links a part to its container. For example, it can be used to link an ADDRESS and a CITY (ADDRESS has-A CITY), since an ADDRESS structure usually has a CITY part.
- The is-A relation links a generic entity to its precise role in a given context. For example, it can be used to link a CITY to a DESTINATION and ORIGIN in the context of a TRAVEL intention, since CITY plays the role of DESTINATION and ORIGIN in this context: DESTINATION is-A CITY and ORIGIN is-A CITY.
For more information, see:
Datasets: What data should you use, and how much do you need?
Once you have defined your ontology, you need to gather and annotate data to train a Mix model. This model will then be used by your application to extract meaning from user queries.
But what data should you annotate?
The best data to annotate
The best data to train your model is what real users will say or type when your application will be online.
How can you get there?
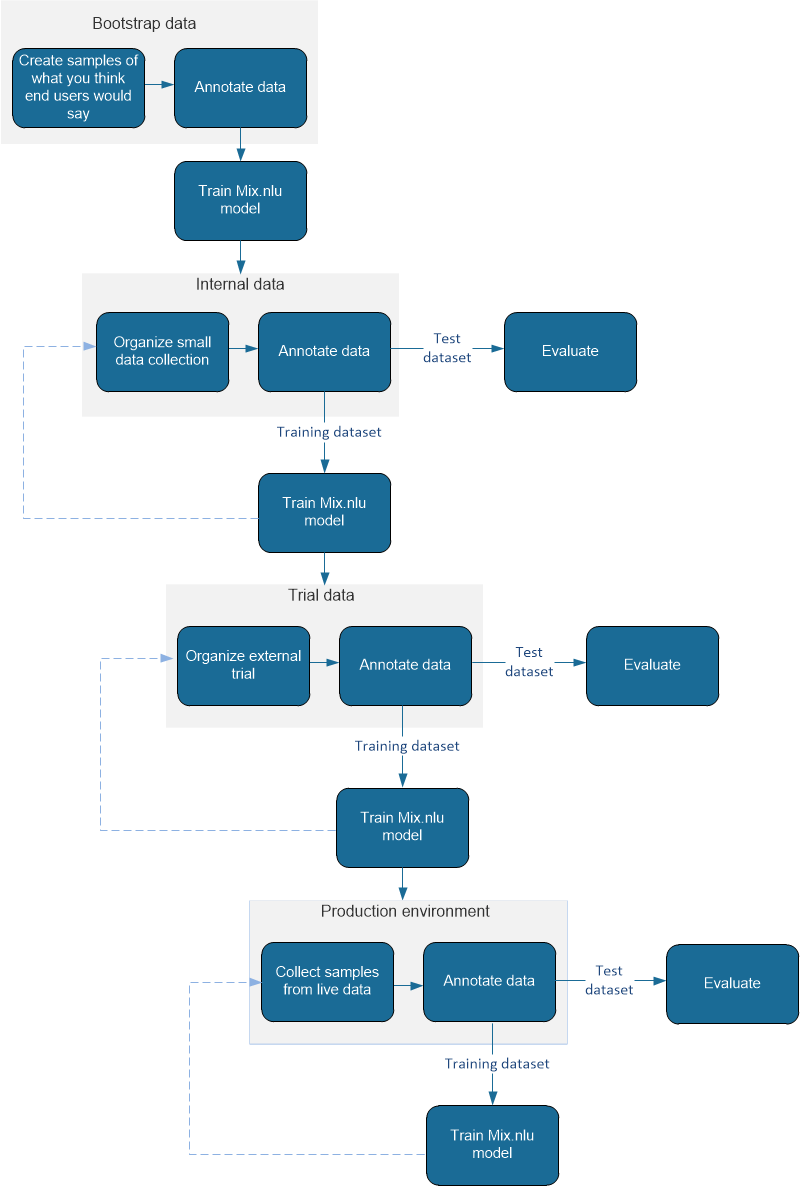
You can get there by steps. At the beginning of your project, when you build the first version or prototype of your application, you have no source of data other than trying to imagine what people might say to your application. This step can be done by someone understanding the scope of your application. In this document, this is called the bootstrap data and is covered in detail in section Tips for creating bootstrap data.
Once you have enough bootstrap data, you have annotated the data, you have trained a Mix.nlu model and you have a minimum viable version of your application, you can organize a small internal data collection. That data collection can be done internally to your organization (or even externally if you can set it up). This data will be better than your bootstrap data as it allows users to interact with your application, which will likely create more variability and will be closer to real-life data. This type of data is called internal data.
You can have one or more iterations of this step, each time bringing the data back to your NLU corpus and annotating, training, and evaluating a new Mix model and then using a better version of your application for the next collection steps.
Once your system is behaving correctly overall and offers the functionality that you are targeting for the real deployment, you can do an external trial to collect the next type of data. This is the final step before deployment. You can target a subset of the actual users of your application. If that is not possible, you can work with a more accessible group; for example, if you are developing the app for a travel company, you could target the employees of that company. This type of data is called trial data.
Finally, once that trial data has been annotated and the NLU models have been retrained, you can go to deployment. Bringing real data, annotating a good amount of that data, adding it to your corpus and retraining your models will be key to make sure the system is working optimally. It will also let you measure the performance that your system really has in the field. This is the most valuable data.
How much data do you need?
Here are some guidelines to help you determine how much data you need, based on trials and mature NLU systems developed by Nuance:
- For more complex intents, Nuance recommends that you collect and generate up to 10K annotations per intent. A complex intent is usually characterized by the presence of many possible sub entities and many different ways to express them. Nuance generates less data (between 1K-10K) when the intent is less complex.
- For applications that detect an intent only (without the need to detect sub entities), the usual amount of data recommended is 1K per intent.
So, as a general guideline you will need between 1K and 10K per intent, depending on the intent complexity.
Note that, in the initial phases of your dataset life cycle, you may not be able to get such a large dataset. But as you progress towards your production application, you should try to reach these guidelines.
The next section describes how you can evaluate the accuracy of your application at each cycle of development. This measure is a good guide to determine if you have enough annotated data in your system to reach a suited accuracy or if you need more data for the modeling.
Evaluating your application
As mentioned above, at each step of the NLU system development cycle, you need to collect new data from the target audience using the real dialog-based application (or at least a prototype of such dialog) and annotate a significant amount of user data semantically (intent & mentions).
This user data serves two purposes:
- Test your model: A random subset of the data will be put in a test dataset, which you will use to evaluate the accuracy of the current system (intent error rate, mention recall, and precision rate). The objective is to analyze the performance and identify the most important weaknesses based on the results obtained. Nuance recommends 1500 annotated samples for a decent test set. If the same sentence is repeated often, the test dataset should include multiple occurrences of this sentence, as you need to keep track of the frequency of input data.
- Train your model: Another random subset of the data will be put in a training dataset, which you will use to train the next version of your NLU model. The objective is to have a significant amount of data to update the NLU modeling (ideally, you should have many additional thousand samples at minimum). The new obtained model can be evaluated with the test dataset generated to ensure an improvement of the new NLU model.
How do you extract a test dataset and a training dataset?
When you are live and you get audio data, the audio data must first be orthographically transcribed. After that step, you can create the test dataset and the training dataset.
To create your dataset, you split the samples into two sets before importing them into Mix.nlu. You randomly pick samples for a test dataset (about 1500 samples) before loading it into Mix.
The next steps are:
- Compare the samples with the associated audio and make sure that the samples correspond to what your users actually said. Fix the incorrect samples in Mix.nlu. This will help build a better ASR model.
- Annotate the samples semantically.
At this stage, samples with the same orthography will be merged in order to annotate the identical sample only once, but the count of repeated samples will be preserved and available from the Mix.nlu tool. The remaining data can be used to build a training set. This set should also be randomly distributed and reflect the real usage distribution. This training set will also be imported in Mix.nlu to fix incorrect samples (if any), annotate the data and use it in a subsequent training stage.
Note that you can also do another data collection to create a test dataset.
What accuracy rate should you target?
When you have created your test dataset, you can use it to measure the performance of your application, including the accuracy rate. When following the guidelines provided in section How much data do you need?, you can expect an accuracy rate between 85% and 95% for typical applications. Is this an acceptable rate? It all really depends on your application.
For some applications, an incorrect result may have serious consequences, so in this case you should target a higher accuracy rate, which means additional training datasets, additional tests, and thus additional costs. For other applications, a lower accuracy rate may be good enough to get started. Only you can determine what is acceptable for your application.
Tips for creating bootstrap data
When you are in the bootstrap data phase, it is important to always keep in mind what actual users might say. While you will not be able to reproduce this data perfectly, by trying to think like your users, you can still come up with a very solid NLU model right away and avoid many problems.
Let’s take an example. Suppose you are building an airline reservation application. Your ontology may contain intents such as TRAVEL, GET_FLIGHT_STATUS, GET_LUGGAGE_FEES, and so on.
Now let’s zoom in for a moment on the TRAVEL intent. That intent may have various entities such as departure time, departure city, arrival city, and so on.
So, what could users say that would convey the intention that they want to travel and book a flight? Here is a first sentence:
I want to travel to Atlanta on March twenty two
When annotated, this sentence will look like this:
I want to travel to [DEP_CITY][CITY] Atlanta [/][/] on [DEP_TIME] [nuance_CALENDARX] March twenty two [/][/]
Keeping in mind what a real user will say, we know that the city will not always be Atlanta and people will not be traveling on the same day. For example, in a finite sample of user queries, some cities will appear a few times, such as larger cities, and some cities will appear only once. At this point it is not important to list all cities but rather to mimic what you could see in a real dataset of similar size. So here’s the first tip when coming up with bootstrap data:
Let’s go back to the sample sentence above. Instead of simply providing the list of all possible values for the city and date entities, we will introduce variety. For example, some cities will occur often (“New York”, “Los Angeles”) while others will be less common (“Albuquerque” or “Knoxville”). The same applies to dates.
Adding variety is very important and applies to more than entity values. Here’s the second tip:
From this tip, you can generate a sentence like “I want to travel”, where none of the entities are provided, as well as a sentence like “I want to travel from Boston to Montreal tomorrow morning”, where all the entities are provided, and many variations in between.
The next thing is to think about how people will express their intent.
From this tip, you can generate phrases such as: * “I want to fly…” * “I will be flying…” * “I want to go..”
Then think about introductory words that may change (e.g., “wanna” instead of “want to”), prepositions that could be dropped, etc.
For example, some users could drop the “I want to” part altogether or use other phrasing. Also, the preposition “on” in the phrase “March twenty two” will be dropped if users say “tomorrow”, “next Tuesday”, etc.
Now combining the 4 tips above, we can easily generate the following sentences:
- I want to travel to New York tomorrow
- I would like to go to Boston
- Flying to Los Angeles
- I would like to travel from Montreal to Dallas on August third
- Please, I’d like to fly from Boston next Sunday
- Would like to travel from Miami to Los Angeles Tuesday evening
- I want to fly from Miami to Atlanta on Monday morning
- Traveling from Cincinnati on July fifteen
- I need to travel to LA
- I wanna travel to Boston next Monday
- I want to go to Seattle next week
- I will be flying from San Francisco to LA this Sunday
- I would like to go to San Diego
- I need to fly to New York on March first
- I will be traveling from New York to LA
- I will be flying to Dallas on Sunday
- Please, I would like to go to Washington Friday March first
- I need to fly to LA tomorrow morning
- I want to travel from Boston to San Francisco on Monday
- I wanna fly to Portland on Tuesday
- I would like to go from New York to Washington
- I need to fly next week to LA
- I will be going to Washington March 27th
- Tomorrow I need to go to Boston
- I want to travel from New York to Miami on June 29th
The next step is to think about a totally different way people might want to express the intent.
For our example, maybe some people will use the word “booking”…. Note that the first 2 sentences are quite different than the previous ones:
- This is for booking a flight
- This is for booking a flight to Los Angeles
- I want to book a flight to Denver
- Booking a flight from Seattle to Chicago
- It’s for booking a flight from New York to Rochester
- Booking a trip to Denver leaving Tuesday afternoon
And furthermore, maybe people will use the term “trip”:
- This is for a trip to Los Angeles.
- For a trip to Boston, leaving early morning Wednesday.
- It’s for a trip to Las Vegas.
When we put all these sentences together, we get the following set:
- I want to travel to Atlanta on March twenty twoI want to travel to New York tomorrow
- I would like to go to Boston
- Flying to Los Angeles
- I would like to travel from Montreal to Dallas on August third
- Please, I’d like to fly from Boston next Sunday
- Would like to travel from Miami to Los Angeles Tuesday evening
- I want to fly from Miami to Atlanta on Monday morning
- Traveling from Cincinnati on July fifteen
- I need to travel to LA
- I wanna travel to Boston next Monday
- I want to go to Seattle next week
- I will be flying from San Francisco to LA this Sunday
- I would like to go to San Diego
- I need to fly to New York on March first
- I will be traveling from New York to LA
- I will be flying to Dallas on Sunday
- Please, I would like to go to Washington Friday March first
- I need to fly to LA tomorrow morning
- I want to travel from Boston to San Francisco on Monday
- I wanna fly to Portland on Tuesday
- I would like to go from New York to Washington
- I need to fly next week to LA
- I will be going to Washington March 27th
- Tomorrow I need to go to Boston
- I want to travel from New York to Miami on June 29th
- This is for booking a flight
- This is for booking a flight to Los Angeles
- I want to book a flight to Denver
- Booking a flight from Seattle to Chicago
- It is for booking a flight from New York to Rochester
- Booking a trip to Denver leaving Tuesday afternoon
- This is for a trip to Los Angeles.
- For a trip to Boston, leaving early morning Wednesday.
- It’s for a trip to Las Vegas.
The dataset created by following the tips in this section will never replace real, actual data. But it will give you much better accuracy than a dataset that does not contain the variations expected in a real-life scenario.
Note that you do not need to list all the possible things that your users might say. For example, if your reservation application covers 350 cities, you do not need to create samples for all these cities, on all possible days. Just select a good sampling of what people might say, as close as possible to the actual target traffic.
Summary: Dataset life cycle