
ASR as a Service gRPC API
Nuance ASR provides real-time speech recognition
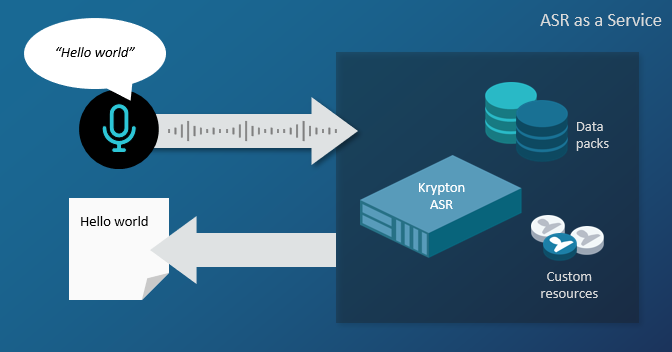
Nuance ASR (Automatic Speech Recognition) as a Service is powered by Krypton, a speech-to-text engine that turns speech into text in real time.
Krypton works with Nuance data packs in many languages, and optionally uses domain language models and wordsets to customize recognition for specific environments.
The gRPC Recognizer protocol provided by Krypton allows client applications to request speech recognition services in any of the programming languages supported by gRPC. An additional gRPC Training protocol allows applications to compile wordsets for use in recognition.
gRPC is an open source RPC (remote procedure call) software that uses HTTP/2 for transport and protocol buffers to define the API. Krypton supports Protocol Buffers version 3, also known as proto3.
Version: v1
This release supports version v1 of the Recognizer API and v1beta1 of the Training API (for compiling wordsets).
The Training API is available to Mix users who create resources using https://mix.nuance.co.uk and access them using the asr.api.nuance.co.uk ASR endpoint. It is not available in other geographies.
For ongoing changes, consult the Change log.
Prerequisites from Mix
Before developing your gRPC application, you need a Nuance Mix project. This project provides credentials to run your application against the Nuance-hosted Krypton ASR engine. It also lets you create one or more domain language models (domain LMs or DLMs) to improve recognition in your environment.
-
Create a Mix project and model: see Mix.nlu workflow to:
Create a Mix project.
Create, train, and build a model in the project. The model must include an intent, optionally entities, and a few annotated sentences.
Since your model is for speech recognition only (not semantic understanding), you can use any intent name, for example DUMMY, and add entities and sentences to that intent. Your entities (for example NAMES and PLACES) should contain words that are specific to your application environment. You can add more words to these categories using wordsets.
Create and deploy an application configuration for the project.
Generate a "secret" and client ID of your Mix project: see Authorize your client application. Later you will use these credentials to request an access token to run your application.
Learn the URL to call the Krypton ASR service: see Accessing a runtime service.
Learn how to reference DLMs and compiled wordsets in your application, using URN syntax. You may only reference resources in your Mix project. See URN in Accessing a runtime service.
gRPC setup
Install gRPC for programming language
$ pip install --upgrade pip
$ pip install grpcio
$ pip install grpcio-tools
Download and unzip proto files. When unzipping the training files, ignore the RPC files
$ unzip nuance_asr_rpc_protos.zip
$ unzip nuance_training_rpc_protos.zip
$ tree
├── Your client apps here
└── nuance
├── asr
│ ├── v1
│ │ ├── recognizer.proto
│ │ ├── resource.proto
│ │ └── result.proto
│ └── v1beta1
│ └── training.proto
└── rpc
├── error_details.proto
├── status_code.proto
└── status.proto
Generate ASR client stubs from proto files
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ --grpc_python_out=./ nuance/asr/v1/recognizer.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/asr/v1/resource.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/asr/v1/result.proto
Generate RPC client stubs
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/status.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/status_code.proto
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ nuance/rpc/error_details.proto
Generate training client stubs
$ python -m grpc_tools.protoc --proto_path=./ --python_out=./ --grpc_python_out=./ nuance/asr/v1beta1/training.proto
Final structure of protos and stubs for ASR and training files (_pycache_ files are not shown)
├── Your client apps here
└── nuance
├── asr
│ ├── v1
│ │ ├── recognizer_pb2_grpc.py
│ │ ├── recognizer_pb2.py
│ │ ├── recognizer.proto
│ │ ├── resource_pb2.py
│ │ ├── resource.proto
│ │ ├── result_pb2.py
│ │ └── result.proto
│ └── v1beta1
│ ├── training_pb2_grpc.py
│ ├── training_pb2.py
│ └── training.proto
└── rpc
├── error_details_pb2.py
├── error_details.proto
├── status_code_pb2.py
├── status_code.proto
├── status_pb2.py
└── status.proto
The basic steps for using the Krypton gRPC protocol are:
Install gRPC for your programming language, including C++, Java, Python, Go, Ruby, C#, Node.js, and others. See gRPC Documentation for a complete list and instructions on using gRPC with each one.
Download the Krypton gRPC proto files, which contain a generic version of the functions or classes for creating Krypton applications. Two sets of zip files are available:
Recognizer protos: nuance_asr_rpc_protos.zip: These files are for requesting recognition. They include recognizer files and Nuance RPC status message files.
Training protos: nuance_training_rpc_protos.zip: These files are for compiling wordsets and consist of the training file and Nuance RPC status message files.
Unzip the files in a location that your applications can access, for example under the directory that contains or will contain your client apps. The files extract to a directory structure starting with nuance.
You need only one copy of the RPC proto files. If you unzip the training files after the recognizer files, you are prompted to keep or overwrite these RPC files: choose [n]o or [N]one to ignore them.
replace nuance/rpc/error_details.proto? [y]es, [n]o, [A]ll, [N]one, [r]ename: NFor Python, or any programming language that requires client stub files, generate the stubs from the proto files using gRPC protoc, using the Python example as guidance. The stubs are generated in the same directories as the proto files.
These stubs contain the methods and fields from the proto files as implemented in your programming language. Some languages, such as Node.js, can use the proto files directly, meaning client stubs are not required. Consult the gRPC documentation for your programming language.
If you already have client stubs for the RPC files in this location, you do not need to regenerate them and may use the existing files.
Endpoints and rate limits
The endpoints for ASR in the hosted Mix environment are:
- Runtime:
asr.api.nuance.co.uk:443 - Authorization:
https://auth.crt.nuance.co.uk/oauth2/token
For security reasons, you are limited to a maximum of requests when using the ASR service. This is to prevent Distributed Denial of Service (DDOS) attacks. When the limit is reached, a rate limit error (gRPC status code UNAVAILABLE) is returned.
See Rate limits for the ASR rate limits in the Mix environment.
What's next?
Once you have the proto files and optionally the client stubs, you are ready to start writing client applications. See:
Client app development: Steps in creating a client, using a simple Python scenario.
Sample Python app: A complete Python recognition client.
Sample Python app: Training: A Python client that compiles wordsets.
Client app development
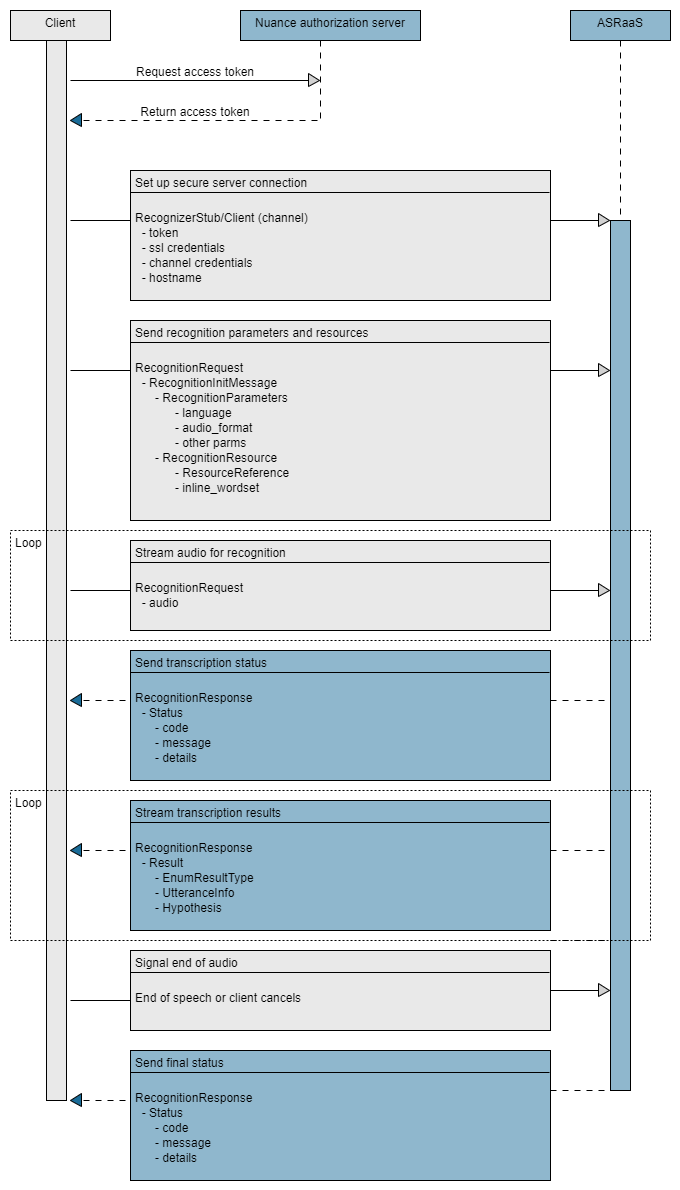
The gRPC protocol for Krypton lets you create a client application for recognizing and transcribing speech. This section describes how to implement the basic functionality of Krypton in the context of a Python application. For the complete application, see Sample Python app.
The essential tasks are illustrated in the following high-level sequence flow:
Step 1: Authorize
Authorize and run Python client (run-python-client.sh)
#!/bin/bash
CLIENT_ID="appID%3ANMDPTRIAL_your_name_company_com_20201102T144327123022%3Ageo%3Aus%3AclientName%3Adefault"
SECRET="9L4l...8oda"
export MY_TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" \
"https://auth.crt.nuance.co.uk/oauth2/token" \
-d "grant_type=client_credentials" -d "scope=asr" \
| python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`"
./my-python-client.py asr.api.nuance.co.uk:443 $MY_TOKEN $1
Nuance Mix uses the OAuth 2.0 protocol for authorization. The client application must provide an access token to be able to access the ASR runtime service. The token expires after a short period of time so must be regenerated frequently.
Your client application uses the client ID and secret from the Mix Dashboard (see Prerequisites from Mix) to generate an access token from the Nuance authorization server.
The client ID starts with appID: followed by a unique identifier. If you are using the curl command, replace the colon with %3A so the value can be parsed correctly:
appID:NMDPTRIAL_your_name_company_com_2020... --> appID%3ANMDPTRIAL_your_name_company_com_2020...
The token may be generated in several ways, either as part of the client application or as a script file. This Python example uses a Linux script to generate a token and store it in an environment variable. The token is then passed to the application, where it is used to create a secure connection to the ASR service.
Step 2: Import functions
Import functions from stubs
from nuance.asr.v1.resource_pb2 import *
from nuance.asr.v1.result_pb2 import *
from nuance.asr.v1.recognizer_pb2 import *
from nuance.asr.v1.recognizer_pb2_grpc import *
The application imports all functions from the Krypton client stubs that you generated from the proto files in gRPC setup.
Do not edit these stub files.
Step 3: Set recognition parms
Set recognition parameters
def stream_out(wf):
try:
init = RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(
pcm = PCM(
sample_rate_hz=wf.getframerate()
)
),
result_type = 'IMMUTABLE_PARTIAL',
utterance_detection_mode = 'MULTIPLE',
recognition_flags = RecognitionFlags(
auto_punctuate=True)
),
resources = [ travel_dlm, places_wordset ]
)
The application sets a RecognitionInitMessage containing RecognitionParameters, or parameters that define the type of recognition you want. Consult your generated stubs for the precise parameter names. Some parameters are:
Language and topic (mandatory): The locale of the audio to be recognized and a specialized language pack. Both values must match an underlying data pack.
Audio format (mandatory): The codec of the audio and optionally the sample rate, 8000 or 16000 (Hz). This example extracts the sample rate from the audio file.
Result type: How results are streamed back to the client. This example sets IMMUTABLE_PARTIAL, as described in Results.
Utterance detection mode: Whether Krypton should transcribe one or all sentences in the audio stream. This example sets MULTIPLE, meaning all sentences.
Recognition flags: One or more true/false recognition parameters. The example sets auto punctuate to true, meaning the results will include periods, commas, and other punctuation.
For details about all recognition parameters, see RecognitionParameters.
RecognitionInitMessage may also include resources such as domain language models and wordsets, which customize recognition for a specific environment or business. See Add DLMs and wordsets.
Step 4: Call client stub
Define and call client stub
try:
hostaddr = sys.argv[1]
access_token = sys.argv[2]
audio_file = sys.argv[3]
. . .
call_credentials = grpc.access_token_call_credentials(access_token)
ssl_credentials = grpc.ssl_channel_credentials()
channel_credentials = grpc.composite_channel_credentials(ssl_credentials, call_credentials)
with grpc.secure_channel(hostaddr, credentials=channel_credentials) as channel:
stub = RecognizerStub(channel)
stream_in = stub.Recognize(client_stream(wf))
The app must include the location of the Krypton instance, the access token, and where the audio is obtained. See Authorize.
Using this information, the app calls a client stub function or class. In some languages, this stub is defined in the generated client files: in Python it is named RecognizerStub, in Go it is RecognizerClient, and in Java it is RecognizerStub.
Step 5: Request recognition
Request recognition and simulate audio stream
def client_stream(wf):
try:
init = RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(
pcm = PCM(sample_rate_hz=wf.getframerate())),
result_type = 'FINAL',
utterance_detection_mode = 'MULTIPLE'),
resources = [ travel_dlm, places_wordset ]
)
yield RecognitionRequest(recognition_init_message = init)
print(f'stream {wf.name}')
packet_duration = 0.020
packet_samples = int(wf.getframerate() * packet_duration)
for packet in iter(lambda: wf.readframes(packet_samples), b''):
yield RecognitionRequest(audio=packet)
sleep(packet_duration)
After setting recognition parameters, the app sends the RecognitionRequest stream, including recognition parameters and the audio to process, to the channel and stub.
In this Python example, this is achieved with a two-part yield structure that first sends recognition parameters then sends the audio for recognition in chunks.
yield RecognitionRequest(recognition_init_params=init)
. . .
yield RecognitionRequest(audio=chunk)
Normally your app will send streaming audio to Krypton for processing but, for simplicity, this application simulates streaming audio by breaking up an audio file into chunks and feeding it to Krypton a bit at a time.
Step 6: Process results
Receive results and print selected fields
try:
# Iterate through messages returned from server
for message in stream_in:
if message.HasField('status'):
if message.status.details:
print(f'{message.status.code} {message.status.message} - {message.status.details}')
else:
print(f'{message.status.code} {message.status.message}')
elif message.HasField('result'):
restype = 'partial' if message.result.result_type else 'final'
print(f'{restype}: {message.result.hypotheses[0].formatted_text}')
except StreamClosedError:
pass
except Exception as e:
print(f'server stream: {type(e)}')
traceback.print_exc()
Finally the app returns the results received from the Krypton engine. This app prints the resulting transcript on screen as it is streamed from Krypton, sentence by sentence, with intermediate partial sentence results when the app has requested PARTIAL or IMMUTABLE_PARTIAL results.
The results may be long or short depending on the length of your audio, the recognition parameters, and the fields included by the app. See Results.
Result type IMMUTABLE_PARTIAL
Results from audio file with result type PARTIAL_IMMUTABLE
stream ../audio/monday_morning_16.wav
100 Continue - recognition started on audio/l16;rate=16000 stream
partial : It's Monday
partial : It's Monday morning and the
final : It's Monday morning and the sun is shining.
partial : I'm getting ready
partial : I'm getting ready to
partial : I'm getting ready to walk
partial : I'm getting ready to walk to the
partial : I'm getting ready to walk to the train commute
final : I'm getting ready to walk to the train commute into work.
partial : I'll catch
partial : I'll catch the
partial : I'll catch the 750
partial : I'll catch the 758 train from
final : I'll catch the 758 train from Cedar Park station.
partial : It will take
partial : It will take me an hour
partial : It will take me an hour to get
final : It will take me an hour to get into town.
stream complete
200 Success
This example shows the results from my audio file, monday_morning_16.wav, a 16kHz wave file talking about my commute into work. The audio file says:
It's Monday morning and the sun is shining.
I'm getting ready to walk to the train and commute into work.
I'll catch the seven fifty-eight train from Cedar Park station.
It will take me an hour to get into town.
The result type in this example is IMMUTABLE_PARTIAL, meaning that partial results are delivered after a slight delay, to ensure that the recognized words do not change with the rest of the received speech.
See Recognition parameters in request for an example of result type PARTIAL.
Result type FINAL
Result type FINAL returns only the final version of each sentence
stream ../audio/weather16.wav
100 Continue - recognition started on audio/l16;rate=16000 stream
final: There is more snow coming to the Montreal area in the next few days
final: We're expecting 10 cm overnight and the winds are blowing hard
final: Our radar and satellite pictures show that we're on the western edge of the storm system as it continues to traffic further to the east
stream complete
200 Success
This example transcribes the audio file weather16.wav, which talks about winter weather in Montreal. The file says:
There is more snow coming to the Montreal area in the next few days.
We're expecting ten centimeters overnight and the winds are blowing hard.
Our radar and satellite pictures show that we're on the western edge of the storm system as it continues to track further to the east.
The result type in the case is FINAL, meaning only the final version of each sentence is returned.
In both these examples, Krypton performs the recognition using only the data pack. For these simple sentences, the recognition is nearly perfect.
Step 7: Add DLMs and wordsets
Declare DLM and wordset
# Declare a DLM defined in your Mix project
travel_dlm = RecognitionResource(
external_reference = ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/<context_tag>/mix.asr?=language=eng-USA'),
reuse = 'HIGH_REUSE',
weight_value = 0.7)
# Define a wordset that extends an entity in the DLM
places_wordset = RecognitionResource(
inline_wordset = '{"PLACES":[{"literal":"La Jolla", "spoken":["la hoya","la jolla"]},
{"literal":"Llanfairpwllgwyngyll","spoken":["lan vire pool guin gill"]},
{"literal":"Abington Pigotts"},{"literal":"Steeple Morden"},
{"literal":"Hoyland Common"},{"literal":"Cogenhoe","spoken":["cook no"]},
{"literal":"Fordoun","spoken":["forden","fordoun"]},{"literal":"Llangollen",
"spoken":["lan goth lin","lan gollen"]},{"literal":"Auchenblae"}]}',
reuse='HIGH_REUSE')
# Add recognition parms and resources
init = RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=16000)),
result_type = 'FINAL',
utterance_detection_mode = 'MULTIPLE'),
resources = [ travel_dlm, places_wordset ]
)
Once you have experimented with basic recognition, you can add resources such as domain language models and wordsets to improve recognition of specific terms and language in your environment. For example, you might add resources containing names and places in your business.
Include DLMs and wordsets in your recognition request with RecognitionResource.
DLMs exist only on the Mix platform, and you access them using a URN. See Prerequisites from Mix and the example at the right.
Define a wordset as
inline_wordsetusing JSON. (You could instead read the wordset from a local file, as shown in Inline wordsets, or as a compiled wordset in Compiled wordsets). This wordset adds values to an entity named PLACES in the DLM.Reference both DLM and wordset in RecognitionResource so they are included in the recognition.
Before and after DLM and wordset
Before: Without a DLM or wordset, unusual place names are not recognized
stream ../audio/abington.wav
100 Continue - recognition started on audio/l16;rate=16000 stream
final : I'm going on a trip to Abington tickets in Cambridgeshire England.
final : I'm speaking to you from the town of cooking out in Northamptonshire.
final : We visited the village of steeple Morton on our way to highland common in Yorkshire.
final : We spent a week in the town of land Gosling in Wales.
final : Have you ever thought of moving to La Jolla in California.
stream complete
200 Success
After: Recognition is perfect with a DLM and wordset
stream ../audio/abington.wav
100 Continue - recognition started on audio/l16;rate=16000 stream
final : I'm going on a trip to Abington Piggots in Cambridgeshire England.
final : I'm speaking to you from the town of Cogenhoe in Northamptonshire.
final : We visited the village of Steeple Morden on our way to Hoyland Common in Yorkshire.
final : We spent a week in the town of Llangollen in Wales.
final : Have you ever thought of moving to La Jolla in California.
stream complete
200 Success
The audio file in this example, abington.wav, is a recording containing a variety of place names, some common and some unusual. The recording says:
I'm going on a trip to Abington Piggots in Cambridgeshire, England.
I'm speaking to you from the town of Cogenhoe [cook-no] in Northamptonshire.
We visited the village of Steeple Morden on our way to Hoyland Common in Yorkshire.
We spent a week in the town of Llangollen [lan-goth-lin] in Wales.
Have you ever thought of moving to La Jolla [la-hoya] in California.
Without a DLM or wordset, the unusual place names are not recognized correctly.
But when all the place names are defined, either in the DLM or in a wordset such as the following, there is perfect recognition.
{
"PLACES": [
{ "literal":"La Jolla",
"spoken":[ "la hoya","la jolla" ] },
{ "literal":"Llanfairpwllgwyngyll",
"spoken":[ "lan vire pool guin gill" ] },
{ "literal":"Abington Pigotts" },
{ "literal":"Steeple Morden" },
{ "literal":"Hoyland Common" },
{ "literal":"Cogenhoe",
"spoken":[ "cook no" ] },
{ "literal":"Fordoun",
"spoken":[ "forden","fordoun" ] },
{ "literal":"Llangollen",
"spoken":[ "lan goth lin","lan gollen" ] },
{ "literal":"Auchenblae" }
]
}
Sample Python app
Location of application files, above the Python stubs
├── my-python-client.py
├── run-python-client.sh
└── nuance
├── asr
│ └── v1
│ ├── recognizer_pb2_grpc.py
│ ├── recognizer_pb2.py
│ ├── resource_pb2.py
│ └── result_pb2.py
└── rpc
├── error_details_pb2.py
├── status_code_pb2.py
└── status_pb2.py
A shell script, run-python-client.sh, obtains an access token and runs the app
#!/bin/bash
CLIENT_ID="appID%3ANMDPTRIAL_your_name_company_com_20201102T144327123022%3Ageo%3Aus%3AclientName%3Adefault"
SECRET="9L4l...8oda"
export MY_TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" \
"https://auth.crt.nuance.co.uk/oauth2/token" \
-d "grant_type=client_credentials" -d "scope=asr nlu tts dlg" \
| python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`"
./my-python-client.py asr.api.nuance.co.uk:443 $MY_TOKEN ../audio/towns_16.wav
This basic Python app, my-python-client.py, transcribes an audio file
#!/usr/bin/env python3
import sys, wave, grpc, traceback
from time import sleep
from nuance.asr.v1.resource_pb2 import *
from nuance.asr.v1.result_pb2 import *
from nuance.asr.v1.recognizer_pb2 import *
from nuance.asr.v1.recognizer_pb2_grpc import *
# Declare a DLM that exists in a Mix project
travel_dlm = RecognitionResource(
external_reference = ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/<context_tag>/mix.asr?=language=eng-USA'),
weight_value = 0.7)
# Declare an inline wordset for an entity in that DLM
places_wordset = RecognitionResource(
inline_wordset = '{"PLACES":[{"literal":"La Jolla","spoken":["la hoya"]},{"literal":"Llanfairpwllgwyngyll","spoken":["lan vire pool guin gill"]},{"literal":"Abington Pigotts"},{"literal":"Steeple Morden"},{"literal":"Hoyland Common"},{"literal":"Cogenhoe","spoken":["cook no"]},{"literal":"Fordoun","spoken":["forden"]},{"literal":"Llangollen","spoken":["lan-goth-lin","lhan-goth-luhn"]},{"literal":"Auchenblae"}]}'
)
# Declare a compiled wordset
places_compiled_ws = RecognitionResource(
external_reference = ResourceReference(
type = 'COMPILED_WORDSET',
uri = 'urn:nuance-mix:tag:wordset:lang/<context_tag>/places-compiled-ws/eng-USA/mix.asr',
mask_load_failures = True
)
)
# Send recognition request parameters and audio
def client_stream(wf):
try:
# Set recognition parameters
init = RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=wf.getframerate())),
result_type = 'FINAL',
utterance_detection_mode = 'MULTIPLE',
recognition_flags = RecognitionFlags(
auto_punctuate = True)),
resources = [ travel_dlm, places_wordset ],
client_data = {'company':'Aardvark','user':'Leslie'}
)
yield RecognitionRequest(recognition_init_message=init)
# Simulate a realtime audio stream using an audio file
print(f'stream {wf.name}')
packet_duration = 0.020
packet_samples = int(wf.getframerate() * packet_duration)
for packet in iter(lambda: wf.readframes(packet_samples), b''):
yield RecognitionRequest(audio=packet)
sleep(packet_duration)
print('stream complete')
except CancelledError as e:
print(f'client stream: RPC canceled')
except Exception as e:
print(f'client stream: {type(e)}')
traceback.print_exc()
# Collect arguments from user
hostaddr = access_token = audio_file = None
try:
hostaddr = sys.argv[1]
access_token = sys.argv[2]
audio_file = sys.argv[3]
except Exception as e:
print(f'usage: {sys.argv[0]} <hostaddr> <token> <audio_file.wav>')
exit(1)
# Check audio file attributes and open secure channel with token
with wave.open(audio_file, 'r') as wf:
assert wf.getsampwidth() == 2, f'{audio_file} is not linear PCM'
assert wf.getframerate() in [8000, 16000], f'{audio_file} sample rate must be 8000 or 16000'
assert wf.getnchannels() == 1, f'{audio_file} is not a mono audio file'
setattr(wf, 'name', audio_file)
call_credentials = grpc.access_token_call_credentials(access_token)
ssl_credentials = grpc.ssl_channel_credentials()
channel_credentials = grpc.composite_channel_credentials(ssl_credentials, call_credentials)
with grpc.secure_channel(hostaddr, credentials=channel_credentials) as channel:
stub = RecognizerStub(channel)
stream_in = stub.Recognize(client_stream(wf))
try:
# Iterate through messages returned from server
for message in stream_in:
if message.HasField('status'):
if message.status.details:
print(f'{message.status.code} {message.status.message} - {message.status.details}')
else:
print(f'{message.status.code} {message.status.message}')
elif message.HasField('result'):
restype = 'partial' if message.result.result_type else 'final'
print(f'{restype}: {message.result.hypotheses[0].formatted_text}')
except StreamClosedError:
pass
except Exception as e:
print(f'server stream: {type(e)}')
traceback.print_exc()
A simple Python 3.6 client application for requesting recognition is shown at the right. To run it:
Make sure you have Python 3.6 or later installed on your system.
Generate the Python stubs from proto files (see gRPC setup).
Copy the script into a file named run-python-client.sh and the application to my-python-client.py. Place both files in the directory above the proto and Python stub files. Don’t forget to give the files execute permission (
chmod +x).Know your client ID and secret from Mix (see Prerequisites from Mix).
Obtain an audio file: mono, linear PCM file, 8 or 16 kHz. Stereo audio files are not supported.
This example uses a DLM and an inline wordset. To request recognition without a DLM or wordset, comment out the resources line:
init = RecognitionInitMessage(
parameters = RecognitionParameters(...),
# resources = [ travel_dlm, places_wordset ],
client_data = {'company':'Aardvark','user':'Leslie'}
Running the Python app
This sample Python app accepts an audio file and transcribes it. Run it from the shell script, which generates a token and runs the app. Pass it the name of an audio file.
$ ./run-python-client.sh ../audio/towns_16.wav stream ../audio/towns_16.wav 100 Continue - recognition started on audio/l16;rate=16000 stream final: I'm going on a trip to Abington Pigotts in Cambridgeshire England final: I'm speaking to you from the town of Cogenhoe in Northamptonshire final: We stopped at the village of Steeple Morden on our way to Hoyland Common in Yorkshire final: We spent a week in the town of Llangollen in Wales final: Have you ever thought of moving to La Jolla in California stream complete 200 Success
The run-python-client.sh script generates a token that authorizes the application to call the Krypton service. It takes your credentials and stores the resulting token in an environment variable, MY_TOKEN.
You may instead incorporate the token-generation code within the application, reading the credentials from a configuration file.
Using a compiled wordset
To use a compiled wordset created with the Training API (see Sample Python app: Training, change the resources line to reference it instead of the inline wordset:
init = RecognitionInitMessage(
parameters = RecognitionParameters(...),
resources = [ travel_dlm, places_compiled_ws ],
client_data = {'company':'Aardvark','user':'Leslie'}
Displaying all results
This application prints just a few selected fields. For examples of adding extra individual fields, see Dsp, Hypothesis, and DataPack. To display all possible information returned by Krypton, replace these lines:
for message in stream_in:
if message.HasField('status'):
if message.status.details:
print(f'{message.status.code} {message.status.message} - {message.status.details}')
else:
print(f'{message.status.code} {message.status.message}')
elif message.HasField('result'):
restype = 'partial' if message.result.result_type else 'final'
print(f'{restype}: {message.result.hypotheses[0].formatted_text}')
With these:
for message in stream_in:
print(message)
For an example of these longer—potentially much longer—results, see Fields chosen by app.
e
Sample Python app: Training
Download and extract sample training app
$ unzip sample-python-training-app.zip
Archive: sample-python-training-app.zip
inflating: client.py
inflating: flow_compilewordsetandwatch.py
inflating: flow_deletewordset.py
inflating: flow_getwordsetmetadata.py
inflating: places-wordset.json
inflating: run-training-client.sh
inflating: util.py
$ chmod +x client.py
$ chmod +x run-training-client.sh
$ python3 --version
Python 3.6.8
Location of application files, above the Python stubs
├── client.py
├── flow_compilewordsetandwatch.py
├── flow_deletewordset.py
├── flow_getwordsetmetadata.py
├── places-wordset.json
├── run-training-client.sh
├── util.py
└── nuance
├── asr
│ └── v1beta1
│ ├── training_pb2_grpc.py
│ └── training_pb2.py
└── rpc
├── error_details_pb2.py
├── status_code_pb2.py
└── status_pb2.py
Apart from the Recognizer API, Krypton includes a separate training API for compiling and managing wordsets. See Training API for the details of the methods.
A sample Python application lets you try out the training API. Download this zip file, sample-python-training-app.zip, and extract it into the directory above your proto files and Python stubs. The file contains:
- client.py: The main client application file.
- util.py: A utility file referenced by client.py.
- flow_*.py: Several sample input files.
- run-training-client.sh: A script file to run the application.
- places-wordset.json: A source JSON wordset file.
- The files client.py and run-training-client.sh need execute permission (
chmod +x). - Optionally add a line at the top of the Python files to identify your Python environment, for example:
#!/usr/bin/env python3
To run this sample app, you also need:
Python 3.6 or later.
Proto files and generated client stubs for training and RPC messaging. See gRPC setup.
Credentials from Mix (a client ID and secret). See Prerequisites from Mix.
A source (JSON) wordset as text or in a file. See Wordsets for information on source wordsets.
You can use the application to compile wordsets, get information about existing compiled wordsets, and delete compiled wordsets. Once you have created the compiled wordsets, you can use them in the recognizer API. See ResourceReference.
Here are a few training scenarios you can try.
Get help
Results from help request
$ ./client.py -h
usage: client.py [-options]
options:
-h, --help Show this help message and exit
-f file [file ...], --files file [file ...]
List of flow files to execute sequentially,
default=['flow.py']
-l lvl, --loglevel lvl fatal, error, warn, default=info, debug
-L [fn], --logfile [fn] log to file, default fn=krcli-{datetimestamp}.log
-q, --quiet disable console logging
-p, --parallel Run each flow in a separate thread
-i [num], --iterations [num] Number of times to run the list of files, default=1
-s [url], --serverUrl [url] NQAS Trainer server URL, default=localhost:8090
--oauthURL [url] OAuth 2.0 URL
--clientID [url] OAuth 2.0 Client ID
--clientSecret [url] OAuth 2.0 Client Secret
--oauthScope [url] OAuth 2.0 Scope, default=asr
--secure Connect to the server using a secure gRPC channel
--rootCerts [file] Root certificates when using a secure gRPC channel
--privateKey [file] Certificate private key when using a secure gRPC
channel
--certChain [file] Certificate chain when using a secure gRPC channel
--jaeger [addr] Send UDP opentrace spans, default
addr=udp://localhost:6831
--meta [txtfile] read header:value metadata lines from file,
default=.metadata
--maxReceiveSizeMB [megabytes] Maximum length of gRPC server response in megabytes,
default=50 MB
--wsFile [file] Inline wordset file for a gRPC channel, if provided
overrides the request.inline_wordset
For a quick check that the application is working, and to see the arguments it accepts, run the client app directly using the help (-h or --help) option.
$ ./client.py -h
See the results at the right and notice:
-for--file: This argument names the input file or files that you will use to enter your synthesis input and parameters. By default the file is named flow.py, the file downloaded as part of the sample app. The sample run script expects you to provide a filename: one of the flow_*.py files.-sor--serverUrl: This is the URL of the training server. By default this is localhost:8090 but the sample run script specifies the Mix service, asr.api.nuance.co.uk on its default port, 443.
Edit script and input files
Before running the application against the Krypton server, edit the sample files for your environment: the script file that runs the app and the input files.
Edit run script
Sample run-training-client.sh
#!/bin/bash
CLIENT_ID="appID%3ANMDPTRIAL_your_name_company_com_20201102T144327123022%3Ageo%3Aus%3AclientName%3Adefault"
SECRET="9L4l...8oda"
export MY_TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" \
"https://auth.crt.nuance.co.uk/oauth2/token" \
-d "grant_type=client_credentials" -d "scope=asr asr.wordset" \
| python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`"
./client.py --serverUrl asr.api.nuance.co.uk:443 --secure \
--token $MY_TOKEN --files $1
The sample run script, run-training-client.sh, offers an easy way to request a token from Mix and then call the client application. (Alternatively, you may generate the token using the application itself, by providing your credentials in the oauthURL, clientID, clientSecret, and oauthScope arguments.)
As for the Recognizer API, Nuance Mix uses the OAuth 2.0 protocol for authorization. The client application must provide an access token to be able to access the Training service. The token expires after a short period of time so must be regenerated frequently.
The client application uses the client ID and secret from the Mix Dashboard (see Prerequisites from Mix) to generate an access token from the Nuance authorization server.
The client ID starts with appID: followed by a unique identifier. If you are using the curl command, replace the colon with %3A so the value can be parsed correctly:
appID:NMDPTRIAL_your_name_company_com_2020... --> appID%3ANMDPTRIAL_your_name_company_com_2020...
When calling the Training service, the scope in the authorization request is asr.wordset. You may also include the Recognizer scope, asr, if you are qualified for both services.
Edit input files
The flow_compilewordsetandwatch.py input file
from nuance.asr.v1beta1.training_pb2 import *
list_of_requests = []
watchrequest = True
request = CompileWordsetRequest()
request.companion_artifact_reference.uri = "urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA"
request.target_artifact_reference.uri = "urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
request.wordset = '{"PLACES":[{"literal":"La Jolla","spoken":["la hoya","la jolla"]},{"literal":"Llanfairpwllgwyngyll","spoken":["lan vire pool guin gill"]},{"literal":"Abington Pigotts"},{"literal":"Steeple Morden"},{"literal":"Hoyland Common"},{"literal":"Cogenhoe","spoken":["cook no"]},{"literal":"Fordoun","spoken":["forden","fordoun"]},{"literal":"Llangollen","spoken":["lan goth lin","lan gollen"]},{"literal":"Auchenblae"}]}'
request.metadata['app_os'] = 'CentOS'
#Add request to list
list_of_requests.append(request)
Also add your information to the input files. Most files contain the Mix-specific location of the domain LM that contains the entity or entities your wordset extends, a URN for the compiled wordset, and a wordset in compressed JSON. Change:
companion_artifact_reference.uri: Enter the Mix context tag of your domain LM, for example /names-places/.target_artifact_reference.uri: Enter a context tag for your wordset, plus a new name for the compiled wordset that you are creating. You may create a new context tag for the wordset or use the same tag as its companion DLM. For example, /names-places/places-compiled-ws/wordset= Enter your source wordset in compressed JSON. You may optionally leave this wordset as is and provide your own source wordset in a file containing either expanded or compressed JSON. The sample package includes a wordset file that you may edit: see places-wordset.json.Optionally add a line at the top of the files to identify your Python environment, for example:
#!/usr/bin/env python3
Compile and watch
Streaming results from compile wordset and watch
./run-training-client.sh flow_compilewordsetandwatch.py
2021-04-05 17:05:41,375 INFO : Iteration #1
2021-04-05 17:05:41,375 INFO : Running flows in serial
2021-04-05 17:05:41,387 INFO : Running file [flow_compilewordsetandwatch.py]
2021-04-05 17:05:41,387 INFO : Sending CompileWordsetAndWatch request
2021-04-05 17:05:41,387 INFO : Override the inline wordset with input file [places-wordset.json]
2021-04-05 17:05:41,387 INFO : Sending request: wordset: "{\"PLACES\":[{\"literal\":\"La Jolla\",\"spoken\":[\"la hoya\",\"la jolla\"]},{\"literal\":\"Llanfairpwllgwyngyll\",\"spoken\":[\"lan vire pool guin gill\"]},{\"literal\":\"Abington Pigotts\"},{\"literal\":\"Steeple Morden\"},{\"literal\":\"Hoyland Common\"},{\"literal\":\"Cogenhoe\",\"spoken\":[\"cook no\"]},{\"literal\":\"Fordoun\",\"spoken\":[\"forden\",\"fordoun\"]},{\"literal\":\"Llangollen\",\"spoken\":[\"lan goth lin\",\"lan gollen\"]},{\"literal\":\"Auchenblae\"}]}\n"
companion_artifact_reference {
uri: "urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA"
}
target_artifact_reference {
uri: "urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
}
metadata {
key: "app_os"
value: "CentOS"
}
2021-04-05 17:05:41,387 INFO : Sending metadata: []
2021-04-05 17:05:41,817 INFO : new server stream count 1
2021-04-05 17:05:41,817 INFO : Received response: job_status_update {
job_id: "246b7980-9652-11eb-b085-5b55ffeb5cba"
status: JOB_STATUS_QUEUED
}
request_status {
status_code: OK
http_trans_code: 200
}
2021-04-05 17:05:42,871 INFO : new server stream count 2
2021-04-05 17:05:42,871 INFO : Received response: job_status_update {
job_id: "246b7980-9652-11eb-b085-5b55ffeb5cba"
status: JOB_STATUS_COMPLETE
}
request_status {
status_code: OK
http_trans_code: 200
}
2021-04-05 17:05:42,871 INFO : First chunk latency: 1.4839928820729256 seconds
2021-04-05 17:05:42,871 INFO : Done running file [flow_compilewordsetandwatch.py]
2021-04-05 17:05:42,872 INFO : Iteration #1 complete
2021-04-05 17:05:42,872 INFO : Average first-chunk latency (over 1 train requests): 1.4839928820729256 seconds
Done
To compile a wordset, you send the training request and watch as the job progresses. This scenario uses the flow_compileandwatch.py input file, which calls the CompileWordsetAndWatch method. The results are streamed back from the server as the compilation proceeds, so you can see the progress of the job.
Open the input file, flow_compileandwatch.py, and make sure your URIs and wordset are correct. In this example, the wordset being created is named places-compiled-ws. This wordset extends the PLACES entity in the domain LM in companion_artifact_reference.
from nuance.asr.v1beta1.training_pb2 import *
list_of_requests = []
watchrequest = True
request = CompileWordsetRequest()
request.companion_artifact_reference.uri = "urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA"
request.target_artifact_reference.uri = "urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
request.wordset = '{"PLACES":[{"literal":"La Jolla","spoken":["la hoya","la jolla"]},{"literal":"Llanfairpwllgwyngyll","spoken":["lan vire pool guin gill"]},{"literal":"Abington Pigotts"},{"literal":"Steeple Morden"},{"literal":"Hoyland Common"},{"literal":"Cogenhoe","spoken":["cook no"]},{"literal":"Fordoun","spoken":["forden","fordoun"]},{"literal":"Llangollen","spoken":["lan goth lin","lan gollen"]},{"literal":"Auchenblae"}]}'
request.metadata['app_os'] = 'CentOS'
#Add request to list
list_of_requests.append(request)
Open the run script, run-training.client.sh, and optionally add the name and location of your source wordset file. You must provide the source wordset either in the flow file or (as in this example) using the --wsFile option in the run script.
#!/bin/bash CLIENT_ID="appID%3ANMDPTRIAL_your_name_company_com_20201102T144327123022%3Ageo%3Aus%3AclientName%3Adefault" SECRET="9L4l...8oda" export MY_TOKEN="`curl -s -u "$CLIENT_ID:$SECRET" \ "https://auth.crt.nuance.co.uk/oauth2/token" \ -d 'grant_type=client_credentials' -d 'scope=asr asr.wordset' \ | python -c 'import sys, json; print(json.load(sys.stdin)["access_token"])'`" ./client.py --serverUrl asr.api.nuance.co.uk:443 --secure \ --token $MY_TOKEN --wsFile places-wordset.json --files $1
Run the application using the run script, passing it the flow file as input.
$ ./run-training-client.sh flow_compilewordsetandwatch.py
See the results at the right. The training API reads the wordset from the file, then compiles it as places-compiled-ws and stores it in the Mix environment. You can then reference it your recognition requests (see ResourceReference) using the URN you provided, for example:
urn:nuance-mix:tag:wordset:lang/<wordset_context_tag>/places-compiled-ws/eng-USA/mix.asr
Get information
Results from get information
$ ./run-training-client.sh flow_getwordsetmetadata.py
2021-04-05 17:21:48,318 INFO : Iteration #1
2021-04-05 17:21:48,319 INFO : Running flows in serial
2021-04-05 17:21:48,331 INFO : Running file [flow_getwordsetmetadata.py]
2021-04-05 17:21:48,331 INFO : Sending GetWordsetMetadata request
2021-04-05 17:21:48,331 INFO : Sending request: artifact_reference {
uri: "urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
}
2021-04-05 17:21:48,331 INFO : Sending metadata: []
2021-04-05 17:21:48,616 INFO : Received response: metadata {
key: "app_os"
value: "CentOS"
}
metadata {
key: "content-type"
value: "application/x-nuance-wordset-pkg"
}
metadata {
key: "x_nuance_companion_checksum_sha256"
value: "2a0b126f996e09beb436123ee382717f68b1538251524cb0b18de7fad29b7094"
}
metadata {
key: "x_nuance_compiled_wordset_checksum_sha256"
value: "b2fb6955008d69cb9b6e3c9f00864246f2a465c3c702d69b949ef5d6451c3d55"
}
metadata {
key: "x_nuance_compiled_wordset_last_update"
value: "2021-04-05T21:10:51.500Z"
}
metadata {
key: "x_nuance_wordset_content_checksum_sha256"
value: "d58fb9c69c676c6fa852c988522d0a42b5d49822a1f405f4153f392c2d063329"
}
request_status {
status_code: OK
http_trans_code: 200
}
2021-04-05 17:21:48,617 INFO : Done running file [flow_getwordsetmetadata.py]
2021-04-05 17:21:48,617 INFO : Iteration #1 complete
Done
To obtain information about a compiled wordset, use the flow_getwordsetmetadata.py input file, which calls the GetWordsetMetadata method. It returns metadata information but not the source JSON wordset.
Open the input file, flow_getwordsetmetadata.py, and make sure your wordset URI is correct. In this example, the wordset being referenced is places-compiled-ws.
from nuance.asr.v1beta1.training_pb2 import * list_of_requests = [] request = GetWordsetMetadataRequest() request.artifact_reference.uri = "urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr" #Add request to list list_of_requests.append(request)
Run the application using the run script, passing it the flow file as input.
$ ./run-training-client.sh flow_getwordsetmetadata.py
See the results at the right.
Delete wordset
Results from delete wordset
$ ./run-training-client.sh flow_deletewordset.py
2021-04-05 17:27:06,696 INFO : Iteration #1
2021-04-05 17:27:06,696 INFO : Running flows in serial
2021-04-05 17:27:06,707 INFO : Running file [flow_deletewordset.py]
2021-04-05 17:27:06,707 INFO : Sending DeleteWordset request
2021-04-05 17:27:06,707 INFO : Sending request: artifact_reference {
uri: "urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
}
2021-04-05 17:27:06,707 INFO : Sending metadata: []
2021-04-05 17:27:07,020 INFO : Received response: request_status {
status_code: OK
http_trans_code: 200
}
2021-04-05 17:27:07,020 INFO : Done running file [flow_deletewordset.py]
2021-04-05 17:27:07,021 INFO : Iteration #1 complete
Done
To delete a compiled wordset, use the flow_deletewordset.py input file, which calls the DeleteWordset method. It removes the wordset permanently from the Mix environment.
Open the input file, flow_deletewordset.py, and make sure your wordset URI is correct. In this example, the wordset being deleted is places-compiled-ws.
from nuance.asr.v1beta1.training_pb2 import * list_of_requests = [] request = DeleteWordsetRequest() request.artifact_reference.uri = "urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr" #Add request to list list_of_requests.append(request)
Run the application using the run script, passing it the flow file as input.
$ ./run-training-client.sh flow_deletewordset.py
See the results at the right.
Troubleshooting
Existing wordset in the compile service
2021-04-05 17:37:41,457 INFO : Sending metadata: []
2021-04-05 17:37:41,977 INFO : Received response: request_status {
status_code: ALREADY_EXISTS
status_sub_code: 10
http_trans_code: 200
status_message {
locale: "en-US"
message: "Compiled wordset already available for artifact reference urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
message_resource_id: "10"
}
}
A missing quotation mark in the JSON
2021-04-05 16:34:55,874 INFO : Received response: request_status {
status_code: BAD_REQUEST
status_sub_code: 7
http_trans_code: 400
status_message {
locale: "en-US"
message: "Invalid wordset content Unexpected token c in JSON at position 5"
message_resource_id: "7"
}
}
A missing end brace in JSON
2021-04-05 16:39:16,027 INFO : Received response: request_status {
status_code: BAD_REQUEST
status_sub_code: 7
http_trans_code: 400
status_message {
locale: "en-US"
message: "Invalid wordset content Unexpected end of JSON input"
message_resource_id: "7"
}
}
These are some of the errors you may encounter using the sample training application.
Existing wordset: If you use the same wordset name in a compile request, you receive an error that the wordset already exists. You can either use a new name or delete the existing wordset before creating it again.
JSON errors: If you source wordset uses incorrect JSON, you receive errors to help you correct it.
Reference topics
This section provides more information about topics in the Krypton gRPC API.
Status messages and codes
Recognizer service
service Recognizer {
rpc Recognize (stream RecognitionRequest) returns (stream RecognitionResponse);
}
Status response message
{
status: {
code: 100
message: 'Continue'
details: 'recognition started on audio/l16;rate=8000 stream'
}
cookies: { ... }
}
A single Recognizer service provides a single Recognize method supporting bi-directional streaming of requests and responses.
The client first provides a recognition request message with parameters indicating at minimum what language to use. Optionally, it can also include resources to customize the data packs used for recognition, and arbitrary client data to be injected into call recording for reference in offline tuning workflows.
In response to the recognition request message, Krypton returns a status message confirming the outcome of the request. Usually the message is Continue: recognition started on audio/l16;rate=8000 stream.
Status messages include HTTP-aligned status codes. A failure to begin recognizing is reflected in a 4xx or 5xx status as appropriate. (Cookies returned from resource fetches, if any, are returned in the first response only.)
When a 100 Continue status is received, the client may proceed to send one or more messages bearing binary audio samples in the format indicated in the recognize message (default: signed PCM/8000 Hz). The server responds with zero or more result messages reflecting the outcome of recognizing the incoming audio, until a terminating condition is reached, at which point the server sends a final status message indicating normal completion (200/204) or any errors encountered (4xx/5xx). Termination conditions include:
- Utterance detection mode is SINGLE and server detects end of speech.
- Utterance detection mode is SINGLE and server observes non-speech samples corresponding to the no_input_timeout_ms value.
- Utterance detection mode is SINGLE and server observes speech samples corresponding to the recognition_timeout_ms value.
- Client ends its message stream to the server.
- Client cancels the RPC.
- Client sends no audio for a server-configured idle timeout.
- Server encounters an error.
If the client cancels the RPC, no further messages are received from the server. If the server encounters an error, it attempts to send a final error status and then cancels the RPC.
Status codes
| Code | Message | Indicates |
|---|---|---|
| 100 | Continue | Recognition parameters and resources were accepted and successfully configured. Client can proceed to send audio data. Also returned in response to a start_timers_message, which starts the no-input timer manually. |
| 200 | Success | Audio was processed, recognition completed, and returned a result with at least one hypothesis. Each hypothesis includes a confidence score, the text of the result, and (for the final result only) whether the hypothesis was accepted or rejected. 200 Success is returned for both accepted and rejected results. A rejected result means that one or more hypothesis are returned, all with rejected = True. |
| 204 | No result | Recognition completed without producing a result. This may occur if the client closes the RPC stream before sending any audio. |
| 400 | Bad request | A malformed or unsupported client request was rejected. |
| 401 | Unauthenticated | The request could not be authorized, when authorization is required. |
| 403 | Forbidden | A request specified a topic that the client is not authorized to use. |
| 404 | No speech | No utterance was detected in the audio stream for a number of samples corresponding to no_input_timeout_ms. This may occur if the audio does not contain anything resembling speech. |
| 408 | Audio timeout | Excessive stall in sending audio data. |
| 409 | Conflict | The recognizer is currently in use by another client. |
| 410 | Not recognizing | A start_timers_message was received (to start the no-input timer manually) but no in-progress recognition exists. |
| 413 | Too much speech | Recognition of utterance samples reached a duration corresponding to recognition_timeout_ms. |
| 500 | Internal server error | A serious error occurred that prevented the request from completing normally. |
| 502 | Resource error | One or more resources failed to load. |
| 503 | Service unavailable | Unused, reserved for gateways. |
Results
The results returned by Krypton applications can range from a simple transcript of an individual sentence to thousands of lines of JSON information. The scale of these results depends on two main factors: the recognition parameters in the request and the fields chosen by the the client application.
Recognition parameters in request
One way to customize the results from Krypton is with two RecognitionParameters in the request: result_type and utterance_detection_mode.
RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(...),
result_type = 'FINAL|PARTIAL|IMMUTABLE_PARTIAL',
utterance_detection_mode = 'SINGLE|MULTIPLE|DISABLED'
)
Result type
In these examples, the application displays only a few basic fields. If the application displays more fields, the results include all those additional fields. See Fields chosen by app next.
Results with FINAL result type and SINGLE utterance detection mode
final : It's Monday morning and the sun is shining
PARTIAL result type with same detection mode
partial : It's
partial : It's me
partial : It's month
partial : It's Monday
partial : It's Monday no
partial : It's Monday more
partial : It's Monday March
partial : It's Monday morning
partial : It's Monday morning and
partial : It's Monday morning and the
partial : It's Monday morning and this
partial : It's Monday morning and the sun
partial : It's Monday morning and the center
partial : It's Monday morning and the sun is
partial : It's Monday morning and the sonny's
partial : It's Monday morning and the sunshine
final : It's Monday morning and the sun is shining
IMMUTABLE_PARTIAL result type with same detection mode
partial : It's Monday
partial : It's Monday morning and the
final : It's Monday morning and the sun is shining
The result type specifies the level of detail that Krypton returns in its streaming result. Set the desired result in RecognitionParameters - result_type. In the response, the type is indicated in Result - result_type. This parameter has three possible values:
FINAL(default): Only the final version of each sentence is returned. The result type is FINAL but is not included in the results in Python applications because it is the default. To show this information to users, the app can determine the result type and display it using code such as this:elif message.HasField('result'):
restype = 'partial' if message.result.result_type else 'final' print(f'{restype}: {message.result.hypotheses[0].formatted_text}')PARTIAL: Partial and final results are returned. Partial results of each sentence are delivered as soon as speech is detected, but with low recognition confidence. These results usually change as more speech is processed and the context is better understood. The result type is shown as PARTIAL. Final results are returned at the end of each sentence.IMMUTABLE_PARTIAL: Partial and final results are returned. Partial results are delivered after a slight delay to ensure that the recognized words do not change with the rest of the received speech. The result type is shown as PARTIAL (not IMMUTABLE_PARTIAL). Final results are returned at the end of each sentence.
Some data packs perform additional processing after the initial recognition. The transcript may change slightly during this second pass, even for immutable partial results. For example, Krypton originally recognized "the seven fifty eight train" as "the 750 A-Train" but adjusted it during a second pass, returning "the 758 train" in the final version of the sentence.
partial : I'll catch the 750 partial : I'll catch the 750 A-Train final : I'll catch the 758 train from Cedar Park station
Utterance detection mode
Results with MULTIPLE utterance detection mode and FINAL result type
final: It's Monday morning and the sun is shining
final: I'm getting ready to walk to the train commute into work
final: I'll catch the 758 train from Cedar Park station
final: It will take me an hour to get into town
Another recognition parameter, utterance_detection_mode, determines how much of the audio Krypton will process. Specify the desired result in RecognitionParameters - utterance_detection_mode. This parameter has three possible values:
SINGLE(default): Return recognition results for one sentence (utterance) only, ignoring any trailing audio. Default.MULTIPLE: Return results for all sentences detected in the audio stream.DISABLED: Return recognition results for all audio provided by the client, without separating it into sentences. The maximum allowed audio length for this detection mode is 30 seconds.
The combination of these two parameters returns different results. In all cases, the actual returned fields also depend on which fields the client application chooses to display.
| Utterance detection mode | |||
|---|---|---|---|
| Result type | SINGLE |
MULTIPLE |
DISABLED |
FINAL |
Returns final version of first sentence. | Returns final version of each sentence. | Returns final version of all speech. |
PARTIAL |
Returns partial results, including corrections, of first sentence. | Returns partial results of each sentence. | Returns partial results of all speech. |
IMMUTABLE_PARTIAL |
Returns stabilized partial results of first sentence. | Returns stabilized partial results of each sentence. | Returns stabilized partial results of all speech. |
The utterance detection modes do not support all the timeout parameters in RecognitionParameters. See Timeouts and detection modes.
Fields chosen by app
Another way to customize your results is by selecting specific fields, or all fields, in your application.
From the complete results returned by Krypton, the application selects the information to display to users. It can be just a few basic fields or the complete results in JSON format.
Basic fields
Client app displays a few basic fields, giving a relatively short result
stream ../../audio/weather16.wav
100 Continue - recognition started on audio/l16;rate=16000 stream
final: There is more snow coming to the Montreal area in the next few days
final: We're expecting 10 cm overnight and the winds are blowing hard
final: Radar and satellite pictures show that we're on the western edge of the storm system as it continues to track further to the east
200 Success
In this example, the application displays only a few essential fields: the status code and message, plus the result type and the formatted text of the best hypothesis of each sentence. The recognition parameters in this request include result type FINAL and utterance detection mode MULTIPLE, meaning only the final and best version of the sentence is returned and all sentences in the audio are processed.
for message in stream_in:
if message.HasField('status'):
if message.status.details:
print(f'{message.status.code} {message.status.message} - {message.status.details}')
else:
print(f'{message.status.code} {message.status.message}')
elif message.HasField('result'):
restype = 'partial' if message.result.result_type else 'final'
print(f'{restype}: {message.result.hypotheses[0].formatted_text}')
All fields
Client app displays all available fields, giving a much longer result
stream ../../audio/weather16.wav
status {
code: 100
message: "Continue"
details: "recognition started on audio/l16;rate=16000 stream"
}
start_of_speech {
first_audio_to_start_of_speech_ms: 880
}
. . .
result {
abs_start_ms: 5410
abs_end_ms: 10290
utterance_info {
duration_ms: 4880
dsp {
snr_estimate_db: 17.0
level: 18433.0
num_channels: 1
initial_silence_ms: 80
initial_energy: -58.339298248291016
final_energy: -68.26629638671875
mean_energy: 171.83999633789062
}
}
hypotheses {
confidence: 0.004999999888241291
average_confidence: 0.6499999761581421
formatted_text: "We\'re expecting 10 cm overnight and the winds are blowing hard"
minimally_formatted_text: "We\'re expecting ten centimeters overnight and the winds are blowing hard"
words {
text: "We\'re"
confidence: 0.6769999861717224
start_ms: 80
end_ms: 240
}
words {
text: "expecting"
confidence: 0.8859999775886536
start_ms: 240
end_ms: 760
}
words {
text: "10"
confidence: 0.8090000152587891
start_ms: 760
end_ms: 1080
}
words {
text: "cm"
confidence: 0.8510000109672546
start_ms: 1080
end_ms: 1780
}
. . .
3,051 lines omitted in the result for this sentence, with 9 more hypotheses
This example prints all results returned by Krypton, giving a long JSON output of all fields. See RecognitionResponse - Result for all fields.
for message in stream_in:
print(message)
The output starts with the initial status and start-of-speech information, followed by statistics and finally by Krypton’s recognition hypotheses, including all words in the sentence. Typically several hypotheses are returned for each sentence, showing confidence levels of the hypothesis as well as formatted and minimally formatted text of the sentence. See Formatted text for the difference between formatted and minimally formatted text.
Depending on the recognition parameters in the request, these results can include one or all sentences, and can show more or less of Krypton’s "thinking process" as it recognizes the words the user is speaking.
In this example, the result type is FINAL, meaning Krypton returns several hypotheses for each sentence but only the final version of each hypothesis.
With result type PARTIAL, the results can be much longer, with many variations in each hypothesis as the words in the sentence are recognized and transcribed.
Formatted text
Formatted vs. minimally formatted text
Formatted text: December 9, 2005
Minimally formatted text: December nine two thousand and five
Formatted text: $500
Minimally formatted text: Five hundred dollars
Formatted text: I'll catch the 758 train
Minimally formatted text: I'll catch the seven fifty eight train
Formatted text: We're expecting 10 cm overnight
Minimally formatted text: We're expecting ten centimeters overnight
Formatted text: I'm okay James, how about yourself?
Minimally formatted text: I'm okay James, how about yourself?
Krypton returns results in two Hypothesis fields: formatted_text and minimally_formatted_text.
Formatted text includes initial capitals for recognized names and places, numbers expressed as digits, currency symbols, and common abbreviations. In minimally formatted text, words are spelled out but basic capitalization and punctuation are included.
In many cases, both formats are identical.
Krypton uses the settings in the data pack to format the material in formatted_text, for example displaying "ten centimeters" as "10 cm." For more precise control, you may specify a formatting scheme and/or option as a recognition parameter. See Formatting.
Formatting scheme
Formatting scheme
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=wf.getframerate())),
result_type = 'FINAL',
utterance_detection_mode = 'MULTIPLE',
formatting = Formatting(
scheme = 'date',
options = {
'abbreviate_titles': True,
'abbreviate_units': False,
'censor_profanities': True,
'censor_full_words': True
}
)
)
)
The formatting scheme determines how ambiguous numbers are displayed in the formatted_ text result field. Only one type may be specified, for example scheme = 'date'.
The available schemes depend on the data pack, but most data packs support date, time, phone, address, all_as_words, default, and num_as_digits.
Each scheme is a collection of many options (see Formatting options below), but the defining option is PatternBias, which sets the preferred pattern for numbers that cannot otherwise be interpreted. The values of PatternBias give their name to most of the schemes: date, time, phone, address, and default.
The PatternBias option cannot be modified, but you may adjust other options using formatting options.
date, time, phone, and address
Formatting schemes help Krypton interpret ambiguous numbers, e.g. "It's seven twenty six"
scheme = 'date' --> It's 7/26
scheme = 'time' --> It's 7:26
scheme = 'address' --> It's 726
scheme = 'phone' --> It's 726
The formatting schemes date, time, phone, and address tell Krypton to prefer one pattern for ambiguous numbers.
By default, Krypton can identify some numbers as dates, times, or phone numbers, for example:
"I'll catch the seven twenty six a m train" is identified as a time because of "a m."
"I was born on eleven twenty six nineteen ninety four" is identified as a date (in American English) because of the sequence of month, day, and year.
"It's six nine seven three two nine four" is identified as a phone number (in American English) because of the pattern of the numbers.
But Krypton considers some numbers ambiguous:
"I'll catch the seven twenty six train" is not recognized as a specific pattern, so Krypton displays it as a simple cardinal number: "I'll catch the 726 train."
"My birthday is eleven twenty six." Similarly, Krypton displays this as: "My birthday is 1126."
By setting the formatting scheme to date, time, phone, or address, you instruct Krypton to interpret these ambiguous numbers as the specified pattern. For example, if you know that the utterances coming into your application are likely to contain dates rather than times, set scheme to date.
all_as_words
Scheme all_as_words
"I'll catch the seven twenty six a m train"
With scheme = 'all_as_words'
--> I'll catch the seven twenty six a.m. train
With the default or any other scheme
--> I'll catch the 7:26 AM train
The all_as_words scheme displays all numbers as words, even when a pattern (date, time, phone, or address) is found. For example, Krypton identifies this as an address: "My address is seven twenty six brookline avenue cambridge mass oh two one three nine."
With the all_as_words scheme, the numbers are written out and address formatting is ignored:
"My address is seven twenty six Brookline Avenue, Cambridge, Mass. Oh two one three nine"With all other schemes, the text is formatted as a standard address:
"My address is 726 Brookline Ave., Cambridge, MA 02139"
default
This scheme is the default. It has the same effect as not specifying a scheme. If Krypton cannot determine the format of the number, it interprets it as a cardinal number.
num_as_digits
The num_as_digits scheme is the same as default, except in its treatment of numbers under 10.
The default scheme formats numbers as numerals from 10 upwards: one, two, three ... nine, 10, 11, 12, etc.
num_as_digits formats all numbers as numerals: 1, 2, 3, etc.
Num_as_digits affects isolated cardinal and ordinal numbers, plural cardinals (ones, twos, nineteen fifties, etc.), some prices, and fractions. "Isolated" means a number that is not found within a greater pattern such as a date or time.
This scheme has no modifiable options.
all_as_katakana
Formatting scheme all_as_katakana
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'ja-JP',
...
formatting = Formatting(
scheme = 'all_as_katakana'
)
)
)
With and without all_as_katakana
Japanese form of "How many kilograms can I check in?"
With scheme = 'all_as_katakana'
--> アズケルニモツノオモサハナンキロマデデスカ
With the default or any other scheme
--> 預ける荷物の重さは何キロまでですか
Available for Japanese data packs only, the all_as_katakana scheme returns the transcript in Katakana, meaning the output is entirely in the phonetic Katakana script, without Kanji, Arabic numbers, or Latin characters.
When all_as_katakana is not specified, the output is a mix of scripts representing standard written Japanese.
This scheme has no modifiable options.
Formatting options
No formatting scheme or options: default scheme is in effect
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=wf.getframerate())),
result_type = 'FINAL',
utterance_detection_mode = 'MULTIPLE'
)
)
Scheme only: all options in the date scheme are in effect
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=wf.getframerate())),
result_type = 'FINAL',
utterance_detection_mode = 'MULTIPLE',
formatting = Formatting(
scheme= 'date'
)
)
)
Options only: options in the default scheme are overridden by specific options
RecognitionInitMessage(
parameters = RecognitionParameters(
...
formatting = Formatting(
options = {
'abbreviate_titles': True,
'abbreviate_units': False,
'censor_profanities': True,
'censor_full_words': True,
}
)
)
)
Scheme and options: options in the date scheme are overridden by specific options
RecognitionInitMessage(
parameters = RecognitionParameters(
...
formatting = Formatting(
scheme = 'date',
options = {
'abbreviate_titles': True,
'abbreviate_units': False,
'censor_profanities': True,
'censor_full_words': True,
}
)
)
)
Formatting options are individual parameters for displaying words and numbers in the formatted_text result field. All options are part of the current formatting scheme (default if not specified) but can be set on their own to override the current setting. The num_as_digits and all_as_katakana schemes have no modifiable options.
The available options depend on the data pack. See Formatting options by language.
All options are boolean. The values are set in the scheme to which they belong.
| Formatting options | Formatting scheme | |
|---|---|---|
| default, date, time, phone, address | all_as_words | |
PatternBiasThe defining characteristic of the scheme. Not modifiable. |
default, date, time, phone, addresss | |
abbreviate_titlesWhether to abbreviate titles such as Captain (Capt), Director (Dir), Madame (Mme), Professor (Prof), etc. In American English, a period follows the abbreviation. The titles Mr, Mrs, and Dr are always abbreviated. |
False | False |
abbreviate_unitsWhether to abbreviate units of measure such as centimeters (cm), meters (m), megabytes (MB), pounds (lbs), ounces (oz), miles per hour (mph), etc. When true, metric units are always abbreviated, but imperial one-word tokens are not abbreviated, so ten feet is 10 feet and twelve quarts is 12 quarts. The formatting of expressions with mutiple units depends on the units involved: only common combinations are formatted. |
True | False |
Arabic_numerals_not_Kanji (Japanese)How to display numbers. False: All numbers are displayed in Kanji. True: Numbers are either Arabic or half-formatted, depending on the half-formatted (million_as_numerals) setting. By default, cardinals are half-formatted, meaning that magnitude words (thousands, millions, etc.) are in Kanji. See Japanese options. |
True | False |
capitalize_2nd_person_pronouns (German)Whether to capitalize second person personal pronouns such as Du, Dich, etc. |
False | False |
capitalize_3rd_person_pronouns (German)Whether to capitalize third-person personal pronouns such as Sie, Ihnen, etc. |
True | True |
censor_profanitiesWhether to mask profanities partially with asterisks, for example “fr*gging” versus “frigging.” |
False | False |
censor_full_wordsWhether to mask profanities completely with asterisks, for example "********" versus "frigging." When true, censor_profanities must also be true. |
False | False |
expand_contractionsIn English data packs, whether to expand common contractions, for example "don't" versus "do not" or "it's nice" versus "it is nice." |
False | False |
format_addressesWhether to format text identified as postal addresses. This does not include adding commas or new lines. Full street address formatting is done for most data packs, following the standards of the country's postal service. |
True | False |
format_currency_codesWhether to replace the currency symbol with its ISO currency code, for example USD125 instead of $125. When true, format_prices must also be true. |
False | False |
format_datesWhether to format text identified as dates as, for example, 7/26/1994, 7/26/94, or 7/26. The order of month and day depends on the data pack. |
True | False |
format_non-USA_postcodesFor non-US data packs, whether to format UK and Canadian postcodes. UK postcodes have the form A9 9AA, A99 9AA, etc. Canadian postal codes have the form A9A 9A9. |
False | False |
format_phone_numbersFor US and Canadian data packs, whether to format numbers identified as phone numbers, as 123-456-7890 or 456-7899, optionally with 1 or +1 before the number. |
True | False |
format_pricesWhether to format numbers identified as prices, including currency symbols and price ranges. The currency symbol depends on the data pack language. |
True | False |
format_social_security_numbersWhether to format numbers identified as US social security numbers or (for Canadian data packs) Canadian social insurance numbers. Both are a series of nine digits formatted as 123-45-6789 or 123 456 789. |
False | False |
format_timesWhether to format numbers identified as times (including both 12- and 24-hour times) as, for example, 10:35 with optional AM or PM. |
True | False |
format_URLs_and_email_addressesWhether to format web and email addresses, including @ (for at) and most suffixes, including multiple suffixes, for example .ac.edu. Numbers are displayed as digits and output is in lowercase. |
True | False |
format_USA_phone_numbers (Mexican)Whether to use US phone formatting instead of Mexican. |
False | False |
improper_fractions_as_numeralsWhether to express improper fractions as numbers, for example 5/4 versus five fourths. |
True | False |
million_as_numeralsWhether to half-format numbers ending in million, billion, trillion, and so on, for example 5 million. See Japanese options. |
True | Inactive |
mixed_numbers_as_numeralsWhether to express numbers that are a combination or an integer and a fraction (three and a half) as numerals (3 1/2). |
True | False |
names_as_katakana (Japanese)Whether recognized first and last names are transcribed in Katakana. This option can improve the transcription of homophone Japanese names, reducing variation and increasing accuracy. This option is true in the all_as_katakana scheme. In other schemes, the option is false by default, meaning names are transcribed in the script usually associated with the name. |
False | False |
two_spaces_after_periodWhether to insert two spaces (instead of one) following a period (full stop), question mark, or exclamation mark. |
False | False |
Japanese options
Formatting options in Japanese data packs
Arabic_numerals_not_Kanji
abbreviate_units
censor_full_words
censor_profanities
format_URLs_and_email_addresses
format_addresses
format_dates
format_phone_numbers
format_prices
format_times
million_as_numerals
names_as_katakana
Combining options: This displays all numbers in Kanji
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'ja-JP',
...
formatting = Formatting(
options = {'Arabic_numerals_not_Kanji':False}
)
)
)
This displays numbers in Kanji and Arabic. This is the default setting so may be omitted.
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'ja-JP',
...
formatting = Formatting(
options = {'Arabic_numerals_not_Kanji':True,
'million_as_numerals':True}
)
)
)
This displays all numbers in Arabic
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'ja-JP',
...
formatting = Formatting(
options = {'Arabic_numerals_not_Kanji':True,
'million_as_numerals':False}
)
)
)
Japanese data packs support the formatting options shown at the right. (See also all_as_katakana for a Japanese-specific formatting scheme.) In these data packs, two options work together to specify how numbers are displayed.
Arabic_numerals_not_Kanjidetermines whether numbers are shown in Arabic, Kanji, or both.For words containing numbers, the formatting output depends on whether the word is defined in the system. For example, 八百屋 is a defined word meaning "greengrocer" (although literally "800 shop"). Even when Arabic_numerals_not_Kanji is True, it is always output as 八百屋, never as 800屋.
If the word containing a number is not defined in the system, the formatting output depends on the context and the formatting scheme in effect (date, time, price, address, and so on).
million_as_numeralsdetermines whether magnitude words (thousands, millions, etc.) are in Kanji and the rest in Arabic, or numbers are entirely in Arabic. When million_as_numerals is True, magnitudes are written in Kanji, as shown below. This affects prices also, so $50,000 is written as $5万.
万 10,000
億 100,000,000
兆 1,000,000,000,000
京 10,000,000,000,000
You can control how numbers are displayed by combining Arabic_numerals_not_Kanji and million_as_numerals:
| All Kanji | Half-formatted (default) | All Arabic |
|---|---|---|
Arabic: False |
Arabic: Truemillion: True |
Arabic: Truemillion: False |
| All numbers are displayed in Kanji. | Magnitude words are in Kanji and the rest in Arabic. | All numbers are displayed in Arabic. |
| 三 | 3 | 3 |
| 十一 | 11 | 11 |
| 六十五 | 65 | 65 |
| 八百三十七 | 837 | 837 |
| 千 | 1,000 | 1,000 |
| 千九百四十五 | 1,945 | 1,945 |
| 八千五百 | 8,500 | 8,500 |
| 一万 | 1万 | 10,000 |
| 一万五千 | 1万5,000 | 15,000 |
| 一億三千万 | 1億3,000万 | 130,000,000 |
| 二億五 | 2億5 | 200,000,005 |
Scheme vs. options
Scheme vs. options
Utterance: "My address is seven twenty six brookline avenue cambridge mass"
With any formatting scheme and
formatting option 'format_addresses': True
--> My address is 726 Brookline Ave., Cambridge, MA
formatting option 'format_addresses': False
--> My address is 726 Brookline Avenue Cambridge Mass
Some formatting schemes have similar names to formatting options, for example the date, phone, time, and address scheme and the options format_dates, format_times, and so on. What's the difference?
These schemes tell Krypton how to interpret ambiguous numbers, while the options tell Krypton how to format text for display. For example:
formatting - scheme = 'date': Interpret "eleven twenty six" as the date 11/26 (November 26).formatting - options{'format_dates': True}: Display numbers identified as dates in the locale's date format, for example 11/26 in American English. This is the default setting.formatting - options{'format_dates': False}: Display numbers as cardinal numbers (1126) or write them out (eleven twenty-six), even for numbers identified as dates.
When you set formatting options, be aware of the default for the scheme to which it belongs. For example, format_prices is True for most schemes, so there is no need to set it explicitly if you want prices to be shown with currency symbols and characters.
Other schemes—all_as_words, num_as_digits, and all_as_katakana—set general instructions for displaying the result and are not related to interpretation of ambiguous numbers.
Formatting options by language
Each language supports a different set of formatting options, which you may modify to customize the way that Krypton formats its results. See Formatting options.
Arabic (ara-XWW)
censor_profanities
format_dates
format_times
format_URLs_and_email_addresses
Chinese (China, chm-CHN)
abbreviate_units
censor_profanities
format_addresses
format_channel_numbers
format_dates
format_phone_numbers
format_times
million_as_numerals
no_math_symbols
Chinese (Taiwan, chm-TWN)
As Chinese plus:
censor_full_word
format_prices
Croatian (hrv-HRV)
abbreviate_units
format_currency_codes
format_dates
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
Czech (ces-CZE)
abbreviate_units
censor_profanities
format_currency_codes
format_dates
format_phone_numbers
format_prices
format_times
format_URLs_and_email_addresses
format_social_security_numbers
Danish (dan-DNK)
abbreviate_units
censor_full_words
censor_profanities
format_currency_codes
format_dates
format_phone_numbers
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
Dutch (nld-NLD)
As Danish plus:
format_addresses
English (USA eng-USA)
abbreviate_titles
abbreviate_units
censor_full_words
censor_profanities
expand_contractions
format_addresses
format_currency_codes
format_dates
format_non-USA_postcodes
format_phone_numbers
format_prices
format_social_security_numbers
format_times
format_URLs_and_email_addresses
improper_fractions_as_numeral
million_as_numerals
mixed_numbers_as_numerals
two_spaces_after_period
English (Australia eng-AUS, Britain eng-BGR)
As English (US) excluding:
format_non-USA_postcodes
format_social_security_numbers
English (India eng-IND)
As English (US) excluding:
format_addresses
format_non-USA_postcodes
Finnish (fin-FIN)
abbreviate_units
censor_profanities
format_currency_codes
format_prices
format_times
format_URLs_and_email_addresses
French (France, fra-FRA), Italian (ita-ITA)
abbreviate_units
censor_profanities
format_addresses
format_currency_codes
format_dates
format_phone_numbers
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
French (Canada fra-CAN)
As French plus:
format_social_insurance_numbers
German (deu-DEU)
abbreviate_units
capitalize_2nd_person_pronouns
capitalize_3rd_person_pronouns
censor_profanities
format_addresses
format_currency_codes
format_dates
format_phone_numbers
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
Greek (ell-GRC)
abbreviate_units
censor_profanities
format_currency_codes
format_dates
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
Hebrew (heb-ISR)
abbreviate_units
format_currency_codes
format_dates
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
Hindi (hin-IND)
abbreviate_units
format_dates
format_prices
format_times
Hungarian (hun-HUN)
abbreviate_units
censor_profanities
format_addresses
format_currency_codes
format_dates
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
Indonesian (ind-IDN)
abbreviate_units
censor_profanities
format_dates
format_phone_numbers
format_prices
format_times
Japanese (jpn-JPN)
abbreviate_units
Arabic_numerals_not_Kanji
censor_full_words
censor_profanities
format_addresses
format_dates
format_phone_numbers
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
names_as_katakana
Korean (kor-KOR)
abbreviate_units
censor_profanities
format_addresses
format_currency_codes
format_dates
format_phone_numbers
format_prices
format_times
format_URLs_and_email_addresses
Norwegian (nor-NOR), Polish (pol-POL)
abbreviate_units
censor_profanities
format_currency_codes
format_dates
format_phone_numbers
format_prices
format_times
format_URLs_and_email_addresses
Portuguese (Brazil por-BRA, Portugal por-PRT)
abbreviate_units
censor_profanities
format_addresses
format_currency_codes
format_dates
format_phone_numbers
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
Romanian (ron-ROU)
abbreviate_units
censor_profanities
format_currency_codes
format_dates
format_phone_numbers
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
Slovak (slk-SVK), Ukranian (ukr-UKR)
abbreviate_units
censor_profanities
format_currency_codes
format_dates
format_prices
format_times
format_URLs_and_email_addresses
Spanish (spa-ESP)
abbreviate_units
censor_profanities
format_addresses
format_currency_codes
format_dates
format_phone_numbers
format_prices
format_times
format_URLs_and_email_addresses
format_USA_phone_numbers
million_as_numerals
Spanish Latin America (spa-XLA), USA (spa-USA)
As Spanish plus:
format_USA_phone_numbers
Thai (tha-THA)
abbreviate_units
censor_profanities
format_dates
format_prices
format_times
Turkish (tur-TUR, Swedish swe-SWE, Russian rus-RUS)
abbreviate_units
censor_full_words
censor_profanities
format_addresses
format_currency_codes
format_dates
format_prices
format_times
format_URLs_and_email_addresses
million_as_numerals
Vietnamese (vie-VNM)
abbreviate_units
censor_full_words
censor_profanities
format_dates
format_prices
format_times
Timers

Krypton offers three timers for limiting user silence and recognition time: a no-input timer, a recognition timer, and an end-of-utterance timer.
No-input timer
No-input timeout on its own can cause problems
RecognitionRequest(
recognition_init_message = RecognitionInitMessage(
parameters = RecognitionParameters(
no_input_timeout_ms = 3000
)
)
)
[*** Play prompt to user ***]
RecognitionRequest(audio)

By default, the no-input timer starts when recognition starts, but has an infinite timeout, meaning Krypton simply waits for the user to speak and never times out.
If you set a no-input timeout, for example no_input_timeout_ms = 3000, the user must start speaking within 3 seconds. If a prompt plays as recognition starts, the recognition may time out before the user hears the prompt.
Add stall_timers and start_timers_message
RecognitionRequest(
recognition_init_message = RecognitionInitMessage(
parameters = RecognitionParameters(
no_input_timeout_ms = 3000,
recognition_flags = RecognitionFlags(stall_timers = True)
)
)
)
[*** Play prompt to user ***]
RecognitionRequest(
control_message = ControlMessage(
start_timers_message = StartTimersControlMessage()
)
)
RecognitionRequest(audio)

To avoid this problem, use stall_timers and start_timers_message to start the no-input timer only after the prompt finishes.
Timeout and timer fields
| Field | Description |
|---|---|
| RecognitionParameters no_input_timeout_ms (no-input timer) |
Time to wait for user input. Default is 0, meaning infinite. By default, the no-input timer starts with recognition_init_message but is only effective when no_input_timeout_ms has a value. When stall_timers is True, you can start the timer manually with start_timers_message. |
| recognition_timeout_ms (recognition timer) |
Duration of recognition, in milliseconds. Default is 0, meaning infinite. The recognition timer starts when speech input starts (after the no-input timer) but is only effective when recognition_timeout_ms has a value. |
| utterance_end_silence_ms (utterance end timer) |
Period of time that signals the end of an utterance. Default is 500 (ms, or half a second). The utterance end timer starts automatically. |
| RecognitionFlags stall_timers |
Do not start the no-input timer. Default is False. By default, the no-input timer starts with recognition_init_message. When stall_timers is True, this timer does not start at that time. The other timers are not affected by stall_timers. |
| ControlMessage start_timers_message |
Starts the no-input timer if it was disabled by stall_timers. This message starts the no-input timer manually. |
The timeout parameters are not supported in all utterance detection modes. See Timeouts and detection modes next.
Timeouts and detection modes
In RecognitionParameters, the utterance detection modes do not support all the timeout parameters. In MULTIPLE detection mode, you may not set a recognition timeout, and in DISABLED mode you may not set any timeouts.
| Utterance detection mode → Recognition parameter ↓ |
SINGLE |
MULTIPLE |
DISABLED |
|---|---|---|---|
| no_input_timeout_ms | Supported | Supported | Not supported |
| recognition_timeout_ms | Supported | Not supported | Not supported |
| utterance_end_silence_ms | Supported | Supported | Not supported |
Wakeup words
Define wakeup words as a recognition resource
# Define wakeup words
wakeups = RecognitionResource(
wakeup_word = WakeupWord(
words = ["Hi Dragon", "Hey Dragon", "Yo Dragon"] )
)
. . .
# Add wakeups to resource list, filter in final results
def client_stream(wf):
try:
init = RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-us',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=wf.getframerate())),
result_type = 'FINAL',
utterance_detection_mode = 'SINGLE',
recognition_flags = RecognitionFlags(
filter_wakeup_word = True )
),
resources = [travel_dlm, places_wordset, wakeups]
)
yield RecognitionRequest(recognition_init_message=init)
Final result from audio: "Hey Dragon, I'd like to watch The Godfather" with filter_wakeup_word=True
stream ../../audio/wuw.wav
100 Continue - recognition started on audio/l16;rate=8000 stream
final: I'd like to watch the Godfather
Result for IMMUTABLE_PARTIAL result type, showing wakeup word in partial but not final results
stream ../../audio/wuw.wav
100 Continue - recognition started on audio/l16;rate=8000 stream
partial: Hey
partial: Hey Dragon
partial: Hey Dragon I
final: I'd like to watch the Godfather
Extract from full results for IMMUTABLE_PARTIAL, showing detected wakeup word at end
status {
code: 100
message: "Continue"
details: "recognition started on audio/l16;rate=8000 stream"
}
start_of_speech {
first_audio_to_start_of_speech_ms: 930
}
result {
result_type: PARTIAL
abs_start_ms: 930
abs_end_ms: 2330
hypotheses {
formatted_text: "Hey Dragon"
minimally_formatted_text: "Hey Dragon"
words {
text: "Hey"
start_ms: 220
end_ms: 320
}
words {
text: "Dragon"
start_ms: 320
end_ms: 740
}
}
data_pack {
language: "eng-USA"
topic: "GEN"
version: "4.7.0"
}
}
result {
//result_type: FINAL (not shown because it's the default value)
abs_start_ms: 930
abs_end_ms: 3910
utterance_info {
duration_ms: 2980
dsp {
snr_estimate_db: 20.0
level: 17409.0
num_channels: 1
initial_silence_ms: 220
initial_energy: -68.99490356445312
final_energy: -59.839900970458984
mean_energy: 123.34700012207031
}
}
hypotheses {
average_confidence: 0.3019999861717224
formatted_text: "I\'d like to watch the Godfather"
minimally_formatted_text: "I\'d like to watch the Godfather"
words {
text: "I\'d"
confidence: 0.7639999985694885
start_ms: 110
end_ms: 270
}
words {
text: "like"
confidence: 0.9570000171661377
start_ms: 270
end_ms: 430
}
words {
text: "to"
confidence: 0.9210000038146973
start_ms: 430
end_ms: 550
}
words {
text: "watch"
confidence: 0.6290000081062317
start_ms: 550
end_ms: 790
silence_after_word_ms: 200
}
words {
text: "the"
confidence: 0.20800000429153442
start_ms: 990
end_ms: 1030
}
words {
text: "Godfather"
confidence: 0.18000000715255737
start_ms: 1030
end_ms: 1630
}
detected_wakeup_word: "Hey Dragon"
}
A wakeup word is a word or phrase that users can say to activate an application, for example "Hey Nuance" or "Hi Dragon." Krypton reports the wakeup word spoken by the user, and optionally removes the word from the final transcript.
Follow these steps to use wakeup words in your client applications.
Define wakeup words
Specify one or more wakeup words or phrases in your recognition request, using RecognitionResource - wake_up_word (WakeupWord) - words.
Each wakeup word consists of one or more space-separated literals with no markup or control characters. The recognition resource fields, weight_enum, weight_value, and reuse, are ignored for wakeup words.
For best recognition results, include several variations of the wakeup word your application can accept.
Filter wakeup word
Optionally have the wakeup word removed from the final results, using RecognitionFlags - filter_wakeup_word = True.
By default, filter_wakeup_words is False, meaning wakeup words are included in the resulting transcript.
When only a wakeup word is spoken, it is always included in the final results even when filter_wakeup_word is True. See Only a wakeup word below for an example.
See the results
When filter_wakeup_word is True, Krypton removes the wakeup word spoken by the user (if any) from the final transcription results, in most situations. Specifically, in result - Hypothesis:
A wakeup word at the start of a formatted_text or minimally_formatted_text result is removed from final results.
A wakeup word as the first element of a word array is removed from final results.
If the wakeup word is the only input, it is not filtered. It is included in the final results: in formatted_text, minimally_formatted_text, and in the word array. In this situation, filter_wakeup_word is ignored.
In all partial results, wakeup words are reported normally. They are not removed from partial or immutable partial results.
See the detected word
The wakeup word spoken by the user is returned in Hypothesis - detected_wakeup_word.
When the input includes a wakeup word and Krypton recognizes it, detected_wakeup_word always contains the wakeup word, even if the word is removed from the final results by filter_wakeup_word = True.
If the user does not say any of the wakeup words, or if Krypton does not recognize them, the transcription proceeds without error, reporting all words spoken by the user. The detected_wakeup_word field is not included in the result.
The overall result properties remain intact, including abs_start_ms, utterance_info, and the hypothesis confidences, which all reflect the presence of the wakeup word.
Limitations
Grammars are not supported (RecognitionResource - inline_grammar) when wakeup words are used.
When the user says only a wakeup word, the word is always included in the results: in the final hypotheses and in detected_wakeup_word.
For example, this is the final result from the audio: "Hey Dragon" with filter_wakeup_word=True. Notice the wakeup word is not filtered from the results.
stream ../../audio/wuw.wav
100 Continue - recognition started on audio/l16;rate=8000 stream
final: Hey Dragon
And the wakeup word is shown in detected_wakeup_word in the details of the final hypotheses, whether filter_wakeup_word is True or False.
hypotheses {
average_confidence: 0.3019999861717224
formatted_text: "Hey Dragon"
minimally_formatted_text: "Hey Dragon"
...
words {
text: "Hey"
start_ms: 220
end_ms: 320
}
words {
text: "Dragon"
start_ms: 320
end_ms: 740
}
}
...
detected_wakeup_word: "Hey Dragon"
}
Resources
In the context of Krypton, resources are objects that facilitate or improve recognition of user speech. Resources include data packs, domain language models, wordsets, builtins, and speaker profiles.
At least one data pack is required. Other resources are optional.
Data packs
Data pack includes acoustic and language model
Krypton works with one or more factory data packs, available in several languages and locales. The data pack includes these neural network-based components:
Acoustic model (AM) translates utterances into phonetic representations of speech.
Language model (LM) identifies the words or phrases most likely spoken.
The base acoustic model is trained to give good performance in many acoustic environments. The base language model is developed to remain current with popular vocabulary and language use. As such, Krypton paired with a data pack is ready for use out-of-the-box for many applications.
You may extend the data pack at runtime using several types of specialization resources:
Each recognition turn leverages a weighted mix of builtins, domain LMs, and wordsets. See Resource weights.
Builtins
Data pack builtins
# Define builtins
cal_builtin = RecognitionResource(
builtin = 'CALENDARX',
weight_value = 0.2)
distance_builtin = RecognitionResource(
builtin ='DISTANCE',
weight_value = 0.2)
# Include builtins in RecognitionInitMessage
init = RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=16000)),
resources = [ travel_dlm, cal_builtin, distance_builtin ]
The data pack may include one or more builtins, which are predefined recognition objects focused on common tasks (numbers, dates, and so on) or general information in a vertical domain such as financial services or healthcare. The available builtins depends on the data pack. For American English data packs, for example, the builtins are:
ALPHANUM DOUBLE TEMPERATURE
AMOUNT DURATION TIME
BOOLEAN DURATION_RANGE VERT_FINANCIAL_SERVICES
CALENDARX GENERIC_ORDER VERT_HEALTHCARE
CARDINAL_NUMBER GLOBAL VERT_TELECOMMUNICATIONS
DATE NUMBERS VERT_TRAVEL
DIGITS ORDINAL_NUMBER
DISTANCE QUANTITY_REL
To use a builtin in Krypton, declare it with builtin in RecognitionResource.
Domain LMs
Each data pack supplied with Krypton provides a base language model that lets Krypton recognize the most common terms and constructs in the language and locale.
You may complement this language model with one or more domain-specific models, called domain language models (domain LMs or DLMs). Each DLM is based on sentences from a specific environment, or domain, and may include one or more entities, or collections of terms used in that environment.
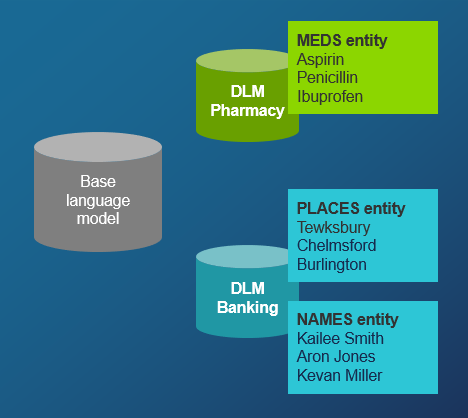
Include DLM in recognition request
# Define DLM
travel_dlm = RecognitionResource(external_reference =
ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/<context_tag>/mix.asr?=language=eng-USA'),
weight_value = 0.7)
# Include DLM in RecognitionInitMessage
init = RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=16000)),
resources = [ travel_dlm ]
DLMs are created in Nuance Mix and included in recognition requests using a URN available from Mix. See URN format and the code sample at the right for an example of a URN.
In Krypton, a DLM is a resource declared with RecognitionResource. Krypton accepts up to ten DLMs, which are weighted along with other recognition objects. See Resource weights.
DLM limits
Each recognition request allows 5 DLMs and 5 compiled wordsets for each reuse setting (LOW_REUSE and HIGH_REUSE).
There is no fixed limit for the number of inline wordsets, but for performance reasons a maximum of 10 is recommended.
Topics in request and DLM
Mix project shows locale and topic
In Mix, a DLM is created using the project's data pack, identified by its language and topic, as shown in the Mix PROJECT tab under Details, for example, Locale(s): en-US and Topic Domain: gen. (The topic is known as a use case when creating a project in Mix.)
When you reference a DLM in a recognition request, the request’s language and topic must match the DLM’s. For example, this request loads an American English GEN data pack and includes a DLM, travel_dlm. The DLM was created in a Mix project with en-US and gen, so it's compatible with the request.
travel_dlm = RecognitionResource(
external_reference = ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA')
)
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
... ),
resources = [travel_dlm]
)
If the language/topic in the request and the DLM do not match, Krypton returns an error. For example, if the request specifies topic = 'GENFAST' but the DLM was created with GEN, it returns this message:
code: 400,
message: 'Bad request',
details: 'topic mismatch for URN(s): urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA'
Wordsets
Wordsets extend entities in DLMs
Inline wordset, places_wordset, extends the PLACES entity
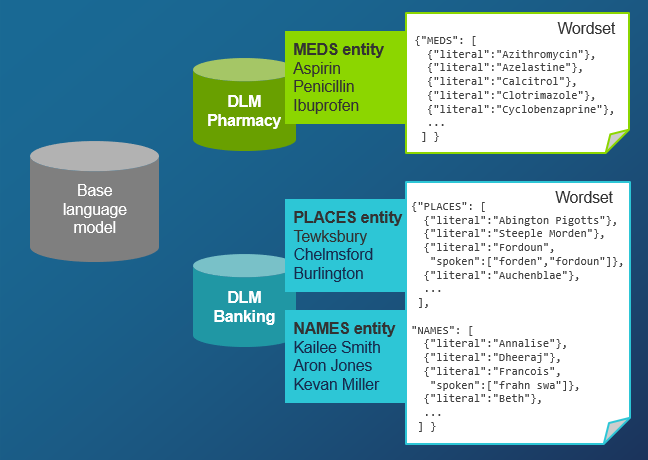
# Define DLM (names-places is its context tag from Mix)
travel_dlm = RecognitionResource(external_reference =
ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA'),
weight_value = 0.7)
# Define a wordset that extends an entity in that DLM
places_wordset = RecognitionResource(
inline_wordset = '{"PLACES":[{"literal":"La Jolla","spoken":["la hoya","la jolla"]},{"literal":"Llanfairpwllgwyngyll","spoken":["lan vire pool guin gill"]},{"literal":"Abington Pigotts"},{"literal":"Steeple Morden"},{"literal":"Hoyland Common"},{"literal":"Cogenhoe","spoken":["cook no"]},{"literal":"Fordoun","spoken":["forden","fordoun"]},{"literal":"Llangollen","spoken":["lan goth lin","lan gollen"]},{"literal":"Auchenblae"}]}')
# Include DLM and wordset in RecogntitionInitMessage
init = RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=16000),
result_type = 'FINAL',
utterance_detection_mode = 'MULTIPLE'),
resources = [ travel_dlm, places_wordset ]
A wordset is a collection of words and short phrases that extends Krypton's recognition vocabulary by providing additional values for entities in a DLM. For example, a wordset might extend the NAMES entity with the names in a user’s contact list or extend the PLACES entity with local place names.
Wordsets are declared with RecognitionInitMessage - RecognitionResource, either as an inline wordset or a compiled wordset.
Defining wordsets
The source wordset is defined in JSON format as a one or more arrays. Each array is named after an entity defined within a DLM to which words can be added at runtime. Entities are templates that tell Krypton how and where words are used in a conversation.
For example, you might have an entity, PLACES, with place names used by the application, or NAMES, containing personal names. The wordset adds to the existing terms in the entity, but applies only to the current recognition session. The terms in the wordset are not added permanently to the entity.
All entities must be defined in DLMs, which are loaded along with the wordset.
The wordset includes additional values for one or more entities. The syntax is:
{
"entity-1" : [
{ "literal": "written form",
"spoken": ["spoken form 1", "spoken form n"]
},
{ "literal": "written form",
"spoken": ["spoken form 1", "spoken form n"]
},
...
],
"entity-n": [ ... ]
}
| Syntax | ||
|---|---|---|
| entity | String | An entity defined in a DLM, containing a set of values. The name is case-sensitive. Consult the DLM training material for entity names. The wordset may contain terms for multiple entities. |
| literal | String | The written form of the value that Krypton returns in the formatted_text field. |
| spoken | Array | (Optional) One or more spoken forms of the value. When not supplied, Krypton guesses the pronunciation of the word from the literal. Include a spoken form only if the literal is difficult to pronounce or has an unusual pronunciation in the language. When a spoken form is supplied, it is the only source for recognition: the literal is not considered. If the literal pronunciation is also valid, you should include it as a spoken form. For example, the city of Worcester, Massachusetts is pronounced wuster, but users reading it on a map may say it literally, as worcester. To allow Krypton to recognize both forms, specify: {"literal":"Worcester", "spoken":["wuster","worcester"]} |
Wordsets may not contain the characters < and >. For this wordset, for example:
{
"PIZZA" : [
{ "literal" : "<Neapolitan>"},
{ "literal" : "Chicago"},
. . .
Krypton generates the following error:
400 Bad request - Error validating wordset: Invalid characters in wordset. Characters < and > are not allowed.
Other special characters and punctuation may affect recognition and should be avoided where possible in both the literal and spoken fields.
The literal field may contain special characters such as !, ?, &, %, and so on, if they are an essential part of the word or phrase. In this case, also include a spoken form without special characters, for example:
{ "literal" : "ExtraMozz!!", "spoken": ["extra moz"] }
Krypton includes the special characters in the return value, for example, when the user says "I'd like to order an extra moz pizza":
hypotheses {
formatted_text: "I\'d like to order an ExtraMozz!! pizza"
minimally_formatted_text: "I\'d like to order an ExtraMozz!! pizza"
See Before and after DLM and wordset to see the difference that a wordset can make on recognition.
Krypton supports both source and compiled wordsets. You can either provide the source wordset in the request or reference a compiled wordset using its URN in the Mix environment.
Inline wordsets
Wordset defined inline
# Define DLM
travel_dlm = RecognitionResource(external_reference =
ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA'),
weight_value = 0.7)
# Define the wordset inline
places_wordset = RecognitionResource(
inline_wordset = '{"PLACES":[{"literal":"La Jolla","spoken":["la hoya","la jolla"]},{"literal":"Llanfairpwllgwyngyll","spoken":["lan vire pool guin gill"]},{"literal":"Abington Pigotts"},{"literal":"Steeple Morden"},{"literal":"Hoyland Common"},{"literal":"Cogenhoe","spoken":["cook no"]},{"literal":"Fordoun","spoken":["forden","fordoun"]},{"literal":"Llangollen","spoken":["lan goth lin","lan gollen"]},{"literal":"Auchenblae"}]}')
# Include the DLM and wordset in RecognitionInitMessage
init = RecognitionInitMessage(
parameters = RecognitionParameters(...),
resources = [ travel_dlm, places_wordset ]
)
Wordset read from a local file using Python function
# Define DLM
travel_dlm = RecognitionResource(external_reference =
ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA'),
weight_value = 0.7)
# Read wordset from local file
places_wordset_content = None
with open('places-wordset.json', 'r') as f:
places_wordset_content = f.read()
places_wordset = RecognitionResource(
inline_wordset = places_wordset_content)
# Include the DLM and wordset in RecognitionInitMessage
init = RecognitionInitMessage(
parameters = RecognitionParameters(...),
resources = [ travel_dlm, places_wordset ]
)
You may provide a source wordset directly in the request or read it from a local file using a programming language function.
This source wordset extends the PLACES entity in the DLM with additional place names. Notice that a spoken form is provided only for terms that do not follow the standard pronunciation rules for the language.
{
"PLACES": [
{ "literal":"La Jolla",
"spoken":[ "la hoya","la jolla" ] },
{ "literal":"Llanfairpwllgwyngyll",
"spoken":[ "lan vire pool guin gill" ] },
{ "literal":"Abington Pigotts" },
{ "literal":"Steeple Morden" },
{ "literal":"Hoyland Common" },
{ "literal":"Cogenhoe",
"spoken":[ "cook no" ] },
{ "literal":"Fordoun",
"spoken":[ "forden","fordoun" ] },
{ "literal":"Llangollen",
"spoken":[ "lan goth lin","lan gollen" ] },
{ "literal":"Auchenblae" }
]
}
To use a source wordset, specify it as inline_wordset in RecognitionResource:
You may include the JSON definition directly in the
inline_wordsetfield, compressed (without spaces) and enclosed in single quotation marks, as shown in the first example at the right.You may instead store the source wordset in a local JSON file and read the file (places-wordset.json) with a programming-language function, as shown in the second example.
Compiled wordsets
Compiled wordset
# Define DLM as before
travel_dlm = RecognitionResource(external_reference =
ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA'),
weight_value = 0.7)
# Define a compiled wordset (here its context is the same as the DLM)
places_compiled_ws = RecognitionResource(
external_reference = ResourceReference(
type = 'COMPILED_WORDSET',
uri = 'urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr')
)
# Include the DLM and wordset in RecognitionInitMessage
init = RecognitionInitMessage(
parameters = RecognitionParameters(...),
resources = [ travel_dlm, places_compiled_ws ]
)
Alternatively, you may reference a compiled wordset that was created with the training API. To use a compiled wordset, specify it in ResourceReference as COMPILED_WORDSET and provide its URN in the Mix environment.
This wordset extends the PLACES entity in the DLM with travel locations.
Inline or compiled?
You may use either inline or compiled wordsets to aid in recognition. The size of your wordset often dictates the best form:
Small wordsets, containing 100 or fewer terms, are suitable for inline use. You can include these with each recognition request at runtime. The wordset is compiled behind the scenes and applied as a resource.
Larger wordsets can be compiled ahead of time using the training API. The compiled wordset is stored in Mix and can then be referenced and loaded as an external resource runtime. This strategy improves latency significantly for large wordsets.
If you are unsure of which approach to take, test the latency when using wordsets inline.
Wordset URNs
Wordset URN and its companion DLM
Domain LM
urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA
Compiled wordset
urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr
To compile a wordset, you must provide a URN for the wordset and for the DLM that it extends.
The URN for the wordset has one of these forms, depending on the level of the wordset:
Application-level wordset. These wordsets apply to all users of an application, for example a company’s employee directory, a movie list, product names, or travel destinations:
urn:nuance-mix:tag:wordset:lang/context_tag/wordset_name/lang/mix.asrUser-level wordset. These wordsets apply to a specific user of an application, for example a contact list, patient list, music playlist, and so on:
urn:nuance-mix:tag:wordset:lang/context_tag/wordset_name/lang/mix.asr?=user_id=user_id
| Syntax | |
|---|---|
| context_tag | An application context tag. This can be an existing wordset context tag or a new context tag that will be created. For clarity, we recommend you use the same context tag as the wordset’s companion DLM. |
| wordset_name | A name for the wordset. When compiling a wordset, this is a new name for the wordset being created. |
| lang | The language and locale of the underlying data pack. |
| user_id | A unique identifier for the user. |
Once the wordset is compiled, it is stored on Mix and can be referenced at runtime by a client application using the same DLM and wordset URNs.
Wordset limits
This wordset request exceeds the maximum size of 4 MB
<_Rendezvous of RPC that terminated with:
status = StatusCode.RESOURCE_EXHAUSTED
details = "Received message larger than max (10329860 vs. 4194304)"
debug_error_string = "{"created":"@1618234583.079000000","description":"Error received from peer ipv4:10.58.161.137:443","file":"src/core/lib/surface/call.cc","file_line":1055,"grpc_message":"Received message larger than max (10329860 vs. 4194304)","grpc_status":8}"
Each recognition request allows 5 DLMs and 5 compiled wordsets for each reuse setting (LOW_REUSE and HIGH_REUSE).
When creating a compiled wordset, the request message has a maximum size of 4 MB. A gRPC error is generated if you exceed this limit.
There is no fixed limit for the number of inline wordsets, but for performance reasons a maximum of 10 is recommended.
Scope of compiled wordsets
The wordset must be compatible with the companion DLM, meaning it must have the same locale and reference entities in the DLM.
The context tag used for the wordset does not have to match the context tag of the companion DLM but it may provide easier wordset management to use the same context tag for both DLM and its associated wordsets.
Both Krypton and NLU both provide a similar API for wordsets, but they are compiled and stored separately for both engines. If your application uses both services and requires large wordsets for both, you must compile them separately for each service.
Wordset lifecycle
Wordsets are available for 28 days after compilation, after which they are automatically deleted and must be compiled again.
Existing compiled wordsets can be updated. Compiling a wordset using an existing wordset URN replaces the existing wordset with the newer version if:
- The source wordset definition is different.
- The wordset’s time to live (TTL) has almost expired, meaning it is nearing the end of its 28-day lifecycle.
- The URN of the companion DLM is different.
- The companion DLM has been updated with new content or its underlying data pack has been updated to a new version.
- Otherwise, the wordset compilation request returns a status ALREADY_EXISTS and the existing wordset remains usable at runtime.
Wordsets can also be manually deleted if no longer needed. Once deleted, a wordset is completely removed and cannot be restored.
If a recognition request includes an incompatible or missing wordset, the ResourceReference mask_load_failures parameter determines whether the request fails or succeeds. When mask_load_failures is True, incompatible or missing wordsets are ignored and the recognition continues without error.
Speaker profiles
Speaker profile
# Define speaker profile
speaker_profile = RecognitionResource(
external_reference = ResourceReference(
type = 'SPEAKER_PROFILE')
)
# Include profile in RecognitionInitMessage
init = RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=16000)
),
resources = [ travel_dlm, places_wordset, speaker_profile ],
user_id = 'james.somebody@aardvark.com'
)
Optionally discard data after request
# Define speaker profile
speaker_profile = RecognitionResource(
external_reference = ResourceReference(
type = 'SPEAKER_PROFILE')
)
# Include profile in RecognitionInitMessage, (optionally) discard after adaptation
init = RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=16000)),
recognition_flags = RecognitionFlags(
discard_speaker_adaptation=True)
),
resources = [ travel_dlm, places_wordset, speaker_profile ],
user_id = 'james.somebody@aardvark.com'
)
Speaker adaptation is a technique that adapts the acoustic model and improves speech recognition based on qualities of the speaker and channel. The best results are achieved by updating the data pack's acoustic model in real time based on the immediate utterance.
Krypton maintains adaptation data for each caller as speaker profiles in an internal datastore.
To use speaker profiles in Krypton, specify them in ResourceReference as SPEAKER_PROFILE, and include a user_id in RecognitionInitMessage. The user id must be a unique identifier for a speaker, for example:
user_id='socha.someone@aardvark.com'
user_id='erij-lastname'
user_id='device-1234'
user_id='33ba3676-3423-438c-9581-bec1dc52548a'
The first time you send a request with a speaker profile, Krypton creates a profile based on the user id and stores the data in the profile. On subsequent requests with the same user id, Krypton adds the data to the profile, which adapts the acoustic model for that specific speaker, providing custom recognition.
Speaker profiles do not have a weight.
After the Krypton session, the adapted data is saved by default. If this information is not required after the session, set discard_speaker_adaptation to True in RecognitionFlags.
The overall time-to-live (TTL) for speaker profiles is 14 days, meaning they are saved for 14 days and then discarded.
Resource weights
Resources used in recognition
A wordset, two DLMs, and one builtin are declared in this example, leaving the base LM with a weight of 0.200
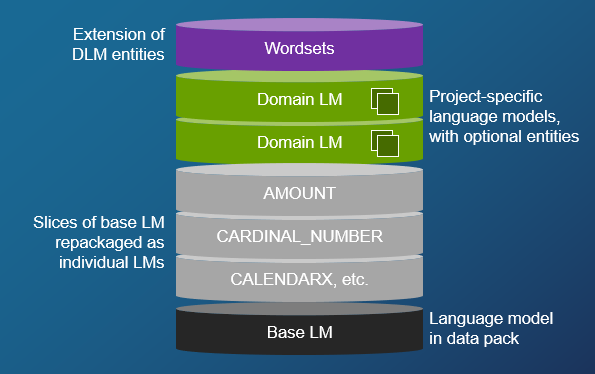

In each recognition turn, Krypton uses a weighted mix of resources: the base LM plus any builtins, DLMs, and wordsets declared in the recognition request. You may set specific weights for DLMs and builtins. You cannot set a weight for wordsets.
The total weight of all resources is 1.0, made up of these components:
| Component | Weight |
|---|---|
| Base LM | By default, the base language model has a weight of 1.0 minus other components in the recognition turn, with a minimum of 0.1 (10%). If other resources exceed 0.9, their weight is reduced to allow the base LM a minimum weight of 0.1. When RecognitionFlags - |
| Builtins | The default weight of each declared builtin is 0.25, or MEDIUM. You may set a weight for each builtin with RecognitionResource - |
| Domain LMs | The default weight of each declared DLM is 0.25, or MEDIUM. You may set a weight for each DLM with RecognitionResource - |
| Wordsets | The weight of each wordset is tied to the weight of its DLM. You cannot set a weight for wordsets. Wordsets also have a small fixed weight (0.1) to ensure clarity within the wordset, so values such as John Smith and Jon Taylor are not confused as John Taylor and Jon Smith. This weight applies to all wordsets together. |
DLMs with 100% weight
This DLM is the principal resource weight
# Declare DLM with 100% weight
names_places_dlm = RecognitionResource(
external_reference = ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA'),
weight_value = 1.0)
# Set allow_zero_base_lm_weight to let DLM use all weight
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=wf.getframerate())),
result_type = 'PARTIAL',
utterance_detection_mode = 'MULTIPLE',
recognition_flags = RecognitionFlags(
allow_zero_base_lm_weight = True)
)
)
If you wish to emphasize one or more DLMs at the expense of the base LM, give them a combined weight of 1.0 and enable the recognition flag, allow_zero_base_lm_weight. In the example at the right, the base LM has little effect on recognition.
Defaults
The proto files provide the following default values for messages in the RecognitionRequest sent to Krypton. Mandatory fields are shown in bold.
| Items in RecognitionRequest | Default | |||
|---|---|---|---|---|
| recognition_init_message (RecognitionInitMessage) | ||||
| parameters (RecognitionParameters) | ||||
| language | Mandatory, e.g. en-US | |||
| topic | GEN | |||
| audio_format (AudioFormat) | Mandatory, e.g. PCM | |||
| utterance_detection_mode (EnumUtterance DetectionMode) | SINGLE (0): transcribe one utterance only | |||
| result_type (EnumResultType) | FINAL (0): return only final version of each utterance | |||
| recognition_flags (RecognitionFlags) | ||||
| auto_punctuate | False: Do no punctuate results | |||
| filter_profanity | False: Leave profanity as is | |||
| include_tokenization | False: Do not include tokenized result | |||
| stall_timers | False: Start no-input timers | |||
| discard_speaker_adaptation | False: Keep speaker profile data | |||
| suppress_call_recording | False: Log calls and audio | |||
| mask_load_failures | False: Loading errors for any resource end recognition | |||
| allow_zero_base_lm_weight | False: Base LM uses minimum 10% resource weight | |||
| no_input_timeout_ms | 0*, usually no timeout | |||
| recognition_timeout_ms | 0*, usually no timeout | |||
| utterance_end_silence_ms | 0*, usually 500 ms or half second | |||
| speech_detection_sensitivity | 0.5 | |||
| max_hypotheses | 0*, usually 10 hypotheses | |||
| speech_domain | Depends on data pack | |||
| formatting (Formatting) | ||||
| scheme | Depends on data pack | |||
| options | Empty | |||
| resources (RecognitionResource) | ||||
| external_reference (ResourceReference) | ||||
| type (Enum ResourceType) | Mandatory with resources - external_reference | |||
| uri | Mandatory with resources - external_reference | |||
| mask_load_failures | False: Loading errors (wordsets only) end recognition | |||
| request_timeout_ms | 0*, usually 10000 ms or 10 seconds | |||
| headers | Empty | |||
| inline_wordset | Empty | |||
| builtin | Empty | |||
| inline_grammar | Empty | |||
| wakeup_word | Empty | |||
| weight_enum (EnumWeight) | 0, meaning MEDIUM | |||
| weight_value | 0 | |||
| reuse (EnumResourceReuse) | LOW_REUSE: only one recognition | |||
| client_data | Empty | |||
| user_id | Empty | |||
| control_message (ControlMessage) | Empty | |||
| audio | Mandatory | |||
* Items marked with an asterisk (*) default to 0, meaning a server default: the default is set in the configuration file used by the Krypton engine instance. The values shown here are the values set in the sample configuration files (default.yaml and development.yaml) provided with the Krypton engine. In the case of max_hypotheses, the default (10 hypotheses) is set internally within Krypton.
Recognizer API
Proto files and client stubs for Recognizer service
└── nuance
├── asr
│ ├── v1
│ │ ├── recognizer_pb2_grpc.py
│ │ ├── recognizer_pb2.py
│ │ ├── recognizer.proto
│ │ ├── resource_pb2.py
│ │ ├── resource.proto
│ │ ├── result_pb2.py
│ │ └── result.proto
└── rpc
├── error_details_pb2.py
├── error_details.proto
├── status_code_pb2.py
├── status_code.proto
├── status_pb2.py
└── status.proto
Krypton provides protocol buffer (.proto) files to define Nuance's ASR Recognizer service for gRPC. These files contain the building blocks of your speech recognition applications.
- recognizer.proto defines the main Recognize streaming service.
- resource.proto defines recognition resources such as domain language models and wordsets.
- result.proto defines the recognition results that Krypton streams back to the client application.
- The RPC files contain status and error messages used by other Nuance APIs. See RPC status messages.
Once you have transformed the proto files into functions and classes in your programming language using gRPC tools (see gRPC setup), you can call these functions from your application to request recognition, to set recognition parameters, to load “helper” resources such as domain language models and wordsets, and to send the resulting transcript where required.
See Client app development and Sample Python app for scenarios and examples in Python. For other languages, consult the gRPC and Protocol Buffers documentation.
Proto file structure
Structure of proto files
Recognizer
Recognize
RecognitionRequest
RecognitionResponseRecognitionRequest
recognition_init_messsage RecognitionInitMessage
parameters RecognitionParameters
language and other recognition parameter fields
audio_format AudioFormat
result_type EnumResultType
recognition_flags RecognitionFlags
formatting Formatting
resources RecognitionResource
external_reference ResourceReference
type EnumResourceType
inline_wordset
builtin
inline_grammar
wakeup_word WakeupWord
weight_enum EnumWeight | weight_value
client_data
user_id
control_message ControlMessage
start_timers_message StartTimersControlMessage
audioRecognitionResponse
status Status
start_of_speech StartOfSpeech
result Result
result fields
result_type EnumResultType
utterance_info UtteranceInfo
utterance fields
dsp Dsp
hypotheses Hypothesis
hypothesis fields
words Word
word fields
data_pack DataPack
data pack fields
notification Notification
notification fields
The proto files define a Recognizer service with a Recognize method that streams a RecognitionRequest and RecognitionResponse. Details about each component are referenced by name within the proto file.
This shows the structure of the principal request fields:

And this shows the main response fields:

For the RPC fields, see RPC status messages.
Recognizer
Recognizer stub and Recognize method
with grpc.secure_channel(hostaddr, credentials=channel_credentials) as channel:
stub = RecognizerStub(channel)
stream_in = stub.Recognize(client_stream(wf))
The Recognizer service offers one RPC method to perform streaming recognition. The method consists of a bidirectional streaming request and response message.
| Method | Request and response | Description |
|---|---|---|
| Recognize | RecognitionRequest stream RecognitionResponse stream |
Starts a recognition request and returns a response. Both request and response are streamed. |
RecognitionRequest
RecognitionRequest sends recognition_init_message, then audio to be transcribed
def client_stream(wf):
try:
# Start the recognition
init = RecognitionInitMessage(. . .)
yield RecognitionRequest(recognition_init_message = init)
# Simulate a typical realtime audio stream
print(f'stream {wf.name}')
packet_duration = 0.020
packet_samples = int(wf.getframerate() * packet_duration)
for packet in iter(lambda: wf.readframes(packet_samples), b''):
yield RecognitionRequest(audio=packet)
For a control_message example, see Timers.
Input stream messages that request recognition, sent one at a time in a specific order. The first mandatory field sends recognition parameters and resources, the final field sends audio to be recognized. Included in Recognize method.
| Field | Type | Description |
|---|---|---|
| One of: | ||
| recognition_init_message | Recognition InitMessage | Mandatory. First message in the RPC input stream, sends parameters and resources for recognition. |
| control_message | Control Message | Optional second message in the RPC input stream, for timer control. |
| audio | bytes | Mandatory. Subsequent message containing audio samples in the selected encoding for recognition. |
Krypton is a real-time service and audio should be streamed at a speed as close to real time as possible. For the best recognition results, we recommend an audio chunk size of 20 to 100 milliseconds.
This message includes:
RecognitionRequest
recognition_init_message (RecognitionInitMessage)
parameters (RecognitionParameters)
resources (RecognitionResource)
client_data
user_id
control_message (ControlMessage)
audio
RecognitionInitMessage
RecognitionInitMessage example
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(
pcm = PCM(
sample_rate_hz=wf.getframerate()
)
),
result_type = 'FINAL',
utterance_detection_mode = 'MULTIPLE',
recognition_flags = RecognitionFlags(
auto_punctuate = True)
),
resources = [travel_dlm, places_wordset],
client_data = {'company':'Aardvark','user':'James'},
user_id = 'james.somebody@aardvark.com'
)
Minimal RecognitionInitMessage
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=16000))
)
)
Input message that initiates a new recognition turn. Included in RecognitionRequest.
| Field | Type | Description |
|---|---|---|
| parameters | Recognition Parameters | Mandatory. Language, audio format, and other recognition parameters. |
| resources | Recognition Resource | Repeated. Resources (DLMs, wordsets, builtins) to improve recognition. |
| client_data | map<string, string> | Map of client-supplied key, value pairs to inject into the call log. |
| user_id | string | Identifies a specific user within the application. |
This message includes:
RecognitionRequest
recognition_init_message (RecognitionInitMessage)
parameters (RecognitionParameters)
language
topic
audio_format
utterance_detection_mode
result_type
etc.
resources (RecognitionResource)
external_reference
type
uri
inline_wordset
builtin
inline_grammar
weight_enum | weight_value
reuse
client_data
user_id
RecognitionParameters
RecognitionParameters example
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(
pcm = PCM(
sample_rate_hz = wf.getframerate()
)
),
result_type = 'PARTIAL',
utterance_detection_mode = 'SINGLE',
recognition_timeout_ms = 10000,
recognition_flags = RecognitionFlags(
auto_punctuate = True,
filter_wakeup_word = True
)
)
)
Input message that defines parameters for the recognition process. Included in RecognitionInitMessage.
The language and audio_format parameters are mandatory. All others are optional. See Defaults for a list of default values.
| Field | Type | Description |
|---|---|---|
| language | string | Mandatory. Language and region (locale) code as xx-XX, e.g. 'en-US' for American English. Codes in the form xxx-XXX, e.g. 'eng-USA' are also supported for backward compatibility. |
| topic | string | Specialized language model in data pack. Case-sensitive, uppercase. Default is 'GEN' (general). If the request includes a DLM, see Topics in request and DLM. |
| audio_format | AudioFormat | Mandatory. Audio codec type and sample rate. |
| utterance_detection_mode | EnumUtterance DetectionMode | How many sentences (utterances) within the audio stream are processed. Default SINGLE. |
| result_type | EnumResultType | The level of recognition results. Default FINAL. |
| recognition_flags | RecognitionFlags | Boolean recognition parameters. |
| no_input_timeout_ms | uint32 | Maximum silence, in milliseconds, allowed while waiting for user input after recognition timers are started. Default (0) means server default, usually no timeout. |
| recognition_timeout_ms | uint32 | Maximum duration, in milliseconds, of recognition turn. Default (0) means server default, usually no timeout. |
| utterance_end_silence_ms | uint32 | Minimum silence, in milliseconds, that determines the end of a sentence. Default (0) means server default, usually 500 milliseconds or half a second. |
| For timeout parameters, see also Timers and Timeouts and detection modes. | ||
| speech_detection_sensitivity | float | A balance between detecting speech and noise (breathing, etc.), 0 to 1. 0 means ignore all noise, 1 means interpret all noise as speech. Default is 0.5. |
| max_hypotheses | uint32 | Maximum number of n-best hypotheses to return. Default (0) means server default, usually 10 hypotheses. |
| speech_domain | string | Mapping to internal weight sets for language models in the data pack. Values depend on the data pack. |
| formatting | Formatting | Formatting keyword. See also Formatted text. |
This message includes:
RecognitionRequest
recognition_init_message (RecognitionInitMessage)
parameters (RecognitionParameters)
language
topic
audio_format
pcm|alaw|ulaw|opus|ogg_opus
utterance_detection_mode - SINGLE|MULTIPLE|DISABLED
result_type - FINAL|PARTIAL|IMMUTABLE_PARTIAL
recognition_flags
auto_punctuate
filter_profanity
mask_load_failures
etc.
speech_detection_sensitivity
max_hypotheses
formatting
etc.
AudioFormat
PCM format, with alternatives shown in commented lines
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(
pcm = PCM(
sample_rate_hz = wf.getframerate()
)
),
# audio_format = AudioFormat(pcm = PCM()),
# audio_format = AudioFormat(pcm = PCM(sample_rate_hz = 16000)),
# audio_format = AudioFormat(alaw = Alaw()),
# audio_format = AudioFormat(ulaw = Ulaw()),
# audio_format = AudioFormat(opus = Opus(source_rate_hz = 16000)),
# audio_format = AudioFormat(ogg_opus = OggOpus(output_rate_hz = 16000)),
result_type = 'FINAL',
utterance_detection_mode = 'MULTIPLE'
)
)
Mandatory input message containing the audio format of the audio to transcribe. Included in RecognitionParameters.
| Field | Type | Description |
|---|---|---|
| One of: | ||
| pcm | PCM | Signed 16-bit little endian PCM, 8kHz or 16kHz. |
| alaw | ALaw | G.711 A-law, 8kHz. |
| ulaw | Ulaw | G.711 µ-law, 8kHz. |
| opus | Opus | RFC 6716 Opus, 8kHz or 16kHz. |
| ogg_opus | OggOpus | RFC 7845 Ogg-encapsulated Opus, 8kHz or 16kHz. |
PCM
Input message defining PCM sample rate. Included in AudioFormat.
| Field | Type | Description |
|---|---|---|
| sample_rate_hz | uint32 | Audio sample rate in Hertz: 0, 8000, 16000. Default 0, meaning 8000. |
Alaw
Input message defining A-law audio format. G.711 audio formats are set to 8kHz. Included in AudioFormat.
Ulaw
Input message defining µ-law audio format. G.711 audio formats are set to 8kHz. Included in AudioFormat.
Opus
Input message defining Opus packet stream decoding parameters. Included in AudioFormat.
| Field | Type | Description |
|---|---|---|
| decode_rate_hz | uint32 | Decoder output rate in Hertz: 0, 8000, 16000. Default 0, meaning 8000. |
| preskip_samples | uint32 | Decoder 48 kHz output samples to skip. |
| source_rate_hz | uint32 | Input source sample rate in Hertz. |
OggOpus
Input message defining Ogg-encapsulated Opus audio stream parameters. Included in AudioFormat.
| Field | Type | Description |
|---|---|---|
| output_rate_hz | uint32 | Decoder output rate in Hertz: 0, 8000, 16000. Default 0, meaning 8000. |
Krypton supports the Opus audio format, either raw Opus (RFC 6716) or Ogg-encapsulated Opus (RFC 7845). The recommended encoder settings for Opus for speech recognition are:
- Sampling rate: 16 kHz
- Complexity: 3
- Bitrate: 28kbps recommended (20kbps minimum)
- Bitrate type: VBR (variable bitrate) or CBR (constant bitrate).
- Packet length: 20 milliseconds
- Encoder mode: SILK only mode
- With Ogg encapsulation, the maximum Ogg container delay should be <= 100 milliseconds.
Please note that Opus is a lossy codec, so you should not expect recognition results to be identical to those obtained with PCM audio.
EnumUtteranceDetectionMode
Detect and recognize each sentence in the audio stream
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=wf.getframerate())),
result_type = 'PARTIAL',
utterance_detection_mode = 'MULTIPLE'
)
)
Input field specifying how sentences (utterances) should be detected and transcribed within the audio stream. Included in RecognitionParameters. The default is SINGLE. When the detection mode is DISABLED, the recognition ends only when the client stops sending audio, up to the allowed length.
| Name | Number | Description |
|---|---|---|
| SINGLE | 0 | Return recognition results for one sentence only, ignoring any trailing audio. Default. |
| MULTIPLE | 1 | Return results for all sentences detected in the audio stream. |
| DISABLED | 2 | Return recognition results for all audio provided by the client, without separating it into sentences. The maximum allowed audio length for this detection mode is 30 seconds. |
The detection modes do not support all the timer parameters in RecognitionParameters. See Timeouts and detection modes.
EnumResultType
Return a stream of partial results, including corrections
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=wf.getframerate())),
result_type = 'PARTIAL',
utterance_detection_mode = 'MULTIPLE'
)
)
Input and output field specifying how results for each sentence are returned. See Results for examples.
As input in RecognitionParameters, EnumResultType specifies the desired result type.
As output in Result, it indicates the actual result type that was returned:
For final results, the
result_typefield is not returned in Python applications, as FINAL is the default.For partial and immutable partial results, the
result_typePARTIAL is returned.
| Name | Number | Description |
|---|---|---|
| FINAL | 0 | Only the final version of each sentence is returned. Default. |
| PARTIAL | 1 | Variable partial results are returned, followed by a final result. |
| IMMUTABLE_PARTIAL | 2 | Stabilized partial results are returned, following by a final result. |
RecognitionFlags
Recognition flags are set within recognition parameters
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=wf.getframerate())),
result_type = 'PARTIAL',
utterance_detection_mode = 'MULTIPLE',
recognition_flags = RecognitionFlags(
auto_punctuate = True,
filter_profanity = True,
suppress_initial_capitalization = True,
allow_zero_base_lm_weight = True,
filter_wakeup_word = True
)
)
)
When suppress_initial_capitalization=True, sentences start with lowercase
stream ../audio/testtowns.wav
100 Continue - recognition started on audio/l16;rate=16000 stream
final: my father's family comes from the town Fordoun in Scotland near Aberdeen
final: another town nearby is called Auchenblae
final: when we were in Wales we visited the town of Llangollen
Input message containing boolean recognition parameters. Included in RecognitionParameters. The default is false in all cases.
| Field | Type | Description |
|---|---|---|
| auto_punctuate | bool | Whether to enable auto punctuation, if available for the language. |
| filter_profanity | bool | Whether to mask known profanities as *** in the result, if available for the language. |
| include_tokenization | bool | Whether to include tokenized recognition result. |
| stall_timers | bool | Whether to disable the no-input timer. By default, this timer starts when recognition begins. See Timers. |
| discard_speaker_adaptation | bool | If speaker profiles are used, whether to discard updated speaker data. By default, data is stored. |
| suppress_call_recording | bool | Whether to disable call logging and audio capture. By default, call logs, audio, and metadata are collected. |
| mask_load_failures | bool | When true, errors loading external resources are not reflected in the Status message and do not terminate recognition. They are still reflected in logs. To set this flag for a specific resource (compiled wordset only), use mask_load_failures in ResourceReference. |
| suppress_initial_capitalization | bool | When true, the first word in a sentence is not automatically capitalized. This option does not affect words that are capitalized by definition, such as proper names, place names, etc. See example at right. |
| allow_zero_base_lm_weight | bool | When true, custom resources (DLMs, wordsets, etc.) can use the entire weight space, disabling the base LM contribution. By default, the base LM uses at least 10% of the weight space. See Resource weights. Even when true, words from the base LM are still recognized, but with lower probability. |
| filter_wakeup_word | bool | Whether to remove the wakeup word from the final result. This field is ignored in some situations. See Wakeup words. |
Formatting
Formatting scheme (date) and options
RecognitionInitMessage(
parameters = RecognitionParameters(
language = 'en-US',
topic = 'GEN',
audio_format = AudioFormat(pcm=PCM(sample_rate_hz=wf.getframerate())),
result_type = 'IMMUTABLE_PARTIAL',
utterance_detection_mode = 'MULTIPLE',
formatting = Formatting(
scheme = 'date',
options = {
'abbreviate_titles': True,
'abbreviate_units': False,
'censor_profanities': True,
'censor_full_words': True
}
)
)
)
Input message specifying how the results are presented, using keywords for formatting types and options supported by the data pack. Included in RecognitionParameters. See Formatted text.
| Field | Type | Description |
|---|---|---|
| scheme | string | Keyword for a formatting type defined in the data pack. |
| options | map<string, bool> | Map of key, value pairs of formatting options and values defined in the data pack. |
ControlMessage
See Timers for an example
Input message that starts the recognition no-input timer. Included in RecognitionRequest. This setting is only effective if timers were disabled in the recognition request. See Timers.
| Field | Type | Description |
|---|---|---|
| start_timers_message | StartTimers ControlMessage | Starts the recognition no-input timer. |
StartTimersControlMessage
Input message the client sends when starting the no-input timer. Included in ControlMessage.
RecognitionResource
RecognitionResource example
# Define a DLM (names-places is my context tag from Mix)
travel_dlm = RecognitionResource(
external_reference = ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA'),
weight_value=0.7)
# Define an inline wordset for an entity in that DLM
places_wordset = RecognitionResource(
inline_wordset = '{"PLACES":[{"literal":"La Jolla","spoken":["la hoya"]},{"literal":"Llanfairpwllgwyngyll","spoken":["lan vire pool guin gill"]},{"literal":"Abington Pigotts"},{"literal":"Steeple Morden"},{"literal":"Hoyland Common"},{"literal":"Cogenhoe","spoken":["cook no"]},{"literal":"Fordoun","spoken":["forden"]},{"literal":"Llangollen","spoken":["lan-goth-lin","lhan-goth-luhn"]},{"literal":"Auchenblae"}]}'
)
# Define a compiled wordset that exists in Mix
places_compiled_ws = RecognitionResource(
external_reference = ResourceReference(
type = 'COMPILED_WORDSET',
uri = 'urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr',
mask_load_failures = True
)
)
# Define wakeup words
wakeups = RecognitionResource(
wakeup_word = WakeupWord(
words = ["Hello Nuance", "Hey Nuance"]
)
)
# Include resources in RecognitionInitMessage
def client_stream(wf):
try:
init = RecognitionInitMessage(
parameters = RecognitionParameters(. . .),
resources = [travel_dlm, places_wordset, places_compiled_ws, wakeups]
)
Input message defining one or more recognition resources (domain LMs, wordsets, etc.) to improve recognition. Included in RecognitionInitMessage.
| Field | Type | Description |
|---|---|---|
| One of: | ||
| external_reference | Resource Reference | The resource is an external file. Mandatory for DLMs, compiled wordsets, and settings files. |
| inline_wordset | string | Inline wordset JSON resource. See Wordsets for the format. Default empty, meaning no inline wordset. |
| builtin | string | Name of a builtin resource in the data pack. Default empty, meaning no builtins. |
| inline_grammar | string | Inline grammar, SRGS XML format. Default empty, meaning no inline grammar. For Nuance internal use only. |
| wakeup_word | WakeupWord | List of wakeup words. See Wakeup words. |
| One of: | Optionally use weight_enum or weight_value to set a weight for the DLM or builtin. Wordsets do not take a weight. See Resource weights. | |
| weight_enum | EnumWeight | Keyword for weight of DLM or builtin. If DEFAULT_WEIGHT or not supplied, defaults to MEDIUM (0.25). |
| weight_value | float | Weight of DLM or builtin as a numeric value from 0 to 1. If 0.0 or not supplied, defaults to 0.25 (MEDIUM). |
| reuse | EnumResource Reuse | Whether the resource will be used multiple times. Default LOW_REUSE. |
This message includes:
RecognitionRequest
recognition_init_message (RecognitionInitMessage)
parameters (RecognitionParameters)
resources (RecognitionResource)
external_reference (ResourceReference)
type - DOMAIN_LM|COMPILED_WORDSET|SPEAKER_PROFILE|SETTINGS
uri
etc.
inline_wordset
builtin
inline_grammar
wakeup_word
weight_enum - LOWEST to HIGHEST | weight_value
reuse - LOW_REUSE|HIGH_REUSE
ResourceReference
External reference examples
# Define a DLM (names-places is my context tag from Mix)
travel_dlm = RecognitionResource(
external_reference = ResourceReference(
type = 'DOMAIN_LM',
uri = 'urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA'),
weight_value = 0.7
)
# Define a compiled wordset
places_compiled_ws = RecognitionResource(
external_reference = ResourceReference(
type = 'COMPILED_WORDSET',
uri = 'urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr',
mask_load_failures = True
)
)
# Define a setttings file
settings = RecognitionResource(
external_reference = ResourceReference(
type = 'SETTINGS',
uri = 'urn:nuance-mix:tag:settings/names-places/asr'
)
)
# Define a speaker profile (no URI)
speaker_profile = RecognitionResource(
external_reference = ResourceReference(
type = 'SPEAKER_PROFILE'
)
)
# Include selected resources in recognition
def client_stream(wf):
try:
init = RecognitionInitMessage(
parameters = RecognitionParameters(. . .),
resources = [travel_dlm, places_compiled_ws, settings, speaker_profile]
)
Input message for fetching an external DLM or settings file that exists in your Mix project, or for creating or updating a speaker profile. Included in RecognitionResource. See Domain LMs and Speaker profiles.
| Field | Type | Description |
|---|---|---|
| type | Enum ResourceType | Resource type. Default UNDEFINED_RESOURCE_TYPE. |
| uri | string | Location of the resource as a URN reference. See below for the different resources. |
| mask_load_failures | bool | Applies to compiled wordsets only. When true, errors loading the wordset are not reflected in the Status message and do not terminate recognition. They are still reflected in logs. To apply this flag to all resources, use mask_load_failures in RecognitionFlags. |
| request_timeout_ ms | uint32 | Time to wait when downloading resources. Default (0) means server default, usually 10000ms or 10 seconds. |
| headers | map<string, string> | Map of HTTP cache-control directives, including max-age, max-stale, min-fresh, etc. For example, in Python: headers = {'cache-control': 'max-age=604800, max-stale=3600'} |
URN format
The format of the URN reference depends on the resource. In these examples, the context tag is names-places and the language code is eng-USA.
Domain LM
DLM URN example (names-places is my context tag from Mix)
urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA
urn:nuance-mix:tag:model/context_tag/mix.asr?=language=language
| Item | Description |
|---|---|
| model | Keyword that identifies a DLM. |
| context_tag | An application context tag from Mix. |
| language | The language code of the underlying data pack, as xxx-XXX. Note: You must use the 6-letter code, for example eng-USA. |
Compiled wordset
Compiled wordset URN example
urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr
urn:nuance-mix:tag:wordset:lang/context_tag/wordset_name/language/mix.asr
or
urn:nuance-mix:tag:wordset:lang/context_tag/wordset_name/language/mix.asr?=user_id=user_id
| Item | Description |
|---|---|
| wordset:lang | Keywords that identify a compiled wordset. |
| context_tag | An application context tag from Mix. |
| wordset_name | A new name for the wordset being compiled. |
| language | The language code of the underlying data pack, as xxx-XXX. Note: You must use the 6-letter code, for example eng-USA. |
| user_id | For wordsets only, a optional unique identifier for the user. |
See also Wordset URNs.
Settings file
Settings file URN example
urn:nuance-mix:tag:settings/names-places/asr
urn:nuance-mix:tag:settings/context_tag/asr
| Item | Description |
|---|---|
| settings | Keyword that identifies a data pack settings file. |
| context_tag | An application context tag from Mix. |
Speaker profiles
Speaker profiles do not use URNs. The speaker is identified with user_id in RecognitionInitMessage.
WakeupWord
Define wakeup words for application and remove them from final results
# Define wakeup words
wakeups = RecognitionResource(
wakeup_word = WakeupWord(
words = ["Hi Dragon", "Hey Dragon", "Yo Dragon"] )
)
# Add wakeups to resource list, filter in final results
def client_stream(wf):
try:
init = RecognitionInitMessage(
parameters = RecognitionParameters(
...
recognition_flags = RecognitionFlags(
filter_wakeup_word = True)
),
resources = [travel_dlm, places_wordset, wakeups]
)
One or more words or phrases that activate the application. Included in RecognitionResource. See related parameter, RecognitionFlags - filter_wakeup_word and Wakeup words.
| Field | Type | Description |
|---|---|---|
| words | string | Repeated. Wakeup word or words. |
EnumResourceType
Input field defining the content type of an external recognition resource. Included in ResourceReference. See Resources.
| Name | Number | Description |
|---|---|---|
| UNDEFINED_RESOURCE_TYPE | 0 | Resource type is not specified. Client must always specify a type. |
| WORDSET | 1 | Resource is a plain-text JSON wordset. Not currently supported, although inline_wordset is supported. |
| COMPILED_WORDSET | 2 | Resource is a compiled wordset. See Compiled wordsets for limits. |
| DOMAIN_LM | 3 | Resource is a domain LM. See Domain LMs for limits. |
| SPEAKER_PROFILE | 4 | Resource is a speaker profile in a Krypton datastore. |
| GRAMMAR | 5 | Resource is an SRGS XML file. Not currently supported. |
| SETTINGS | 6 | Resource is ASR settings metadata, including the desired data pack version. |
EnumWeight
Input field setting the weight of the domain LM or builtin relative to the data pack, as a keyword. Included in RecognitionResource. Wordsets and speaker profiles do not have a weight. See weight_value to specify a numeric value. See Resource weights.
| Name | Number | Description |
|---|---|---|
| DEFAULT_WEIGHT | 0 | Same effect as MEDIUM. |
| LOWEST | 1 | The resource has minimal influence on the recognition process, equivalent to weight_value 0.05. |
| LOW | 2 | The resource has noticeable influence, equivalent to weight_value 0.1. |
| MEDIUM | 3 | The resource has roughly an equal effect compared to the data pack, equivalent to weight_value s0.25. |
| HIGH | 4 | Words from the resource may be favored over words from the data pack, equivalent to weight_value 0.5. |
| HIGHEST | 5 | The resource has the greatest influence on the recognition, equivalent to weight_value 0.9. |
EnumResourceReuse
Input field specifying whether the domain LM or wordset will be used for one or many recognition turns. Included in RecognitionResource.
| Name | Number | Description |
|---|---|---|
| UNDEFINED_REUSE | 0 | Not specified: currently defaults to LOW_REUSE. |
| LOW_REUSE | 1 | The resource will be used for only one recognition turn. |
| HIGH_REUSE | 5 | The resource will be used for a sequence of recognition turns. |
RecognitionResponse
RecognitionResponse example prints selected fields from the results returned from Krypton
try:
# Iterate through messages returned from server
for message in stream_in:
if message.HasField('status'):
if message.status.details:
print(f'{message.status.code} {message.status.message} - {message.status.details}')
else:
print(f'{message.status.code} {message.status.message}')
elif message.HasField('result'):
restype = 'partial' if message.result.result_type else 'final'
print(f'{restype}: {message.result.hypotheses[0].formatted_text}')
This prints all available fields from the message returned from Krypton
try:
# Iterate through messages returned from server, returning all information
for message in stream_in:
print(message)
For examples of the response, see Results.
Output stream of messages in response to a recognize request. Included in Recognize method.
| Field | Type | Description |
|---|---|---|
| status | Status | Always the first message returned, indicating whether recognition was initiated successfully. |
| start_of_speech | StartOfSpeech | When speech was detected. |
| result | Result | The partial or final recognition result. A series of partial results may preceed the final result. |
The response contains all possible fields of information about the recognized audio, and your application may choose to print all or some fields. The sample application prints only the status and the best hypothesis sentence, and other examples also include the data pack version and some DSP information.
Your application may instead print all fields to the user with (in Python) a simple print(message). In this scenario, the results contain the status, start-of-speech information, followed by the result itself, consisting overall information then several hypotheses of the sentence and its words, including confidence scores.
The response depends on two recognition parameters: result_type, which specifies how much of Krypton’s internal processing is reflected in the results, and utterance_detection_mode, which determines whether to process all sentences in the audio or just the first one.
For examples, see Results.
This message includes:
RecognitionResponse
status (Status)
code
message
details
start_of_speech (StartOfSpeech)
first_audio_to_start_of_speech_ms
result (Result)
result_type - FINAL|PARTIAL|IMMUTABLE_PARTIAL
abs_start_ms
abs_end_ms
utterance_info (UtteranceInfo)
duration_ms
clipping_duration_ms
dropped_speech_packets
dropped_nonspeech_packets
dsp (Dsp)
digital signal processing results
hypotheses (Hypothesis)
confidence
average_confidence
rejected
formatted_text
minimally_formatted_text
words (Words)
text
confidence
start_ms
end_ms
silence_after_word_ms
grammar_rule
encrypted_tokenization
grammar_id
detected_wakeup_word
data_pack (DataPack)
language
topic
version
id
cookies
Status
Status example
try:
# Iterate through messages returned from server
for message in stream_in:
if message.HasField('status'):
if message.status.details:
print(f'{message.status.code} {message.status.message} - {message.status.details}')
else:
print(f'{message.status.code} {message.status.message}')
Output message indicating the status of the job. Included in RecognitionResponse.
See Status codes for details about the codes. The message and details are developer-facing error messages in English. User-facing messages should be localized by the client based on the status code.
| Field | Type | Description |
|---|---|---|
| code | uint32 | HTTP-style return code: 100, 200, 4xx, or 5xx as appropriate. |
| message | string | Brief description of the status. |
| details | string | Longer description if available. |
StartOfSpeech
Output message containing the start-of-speech message. Included in RecognitionResponse.
| Field | Type | Description |
|---|---|---|
| first_audio_to_start_of_speech_ms | uint32 | Offset, in milliseconds, from start of audio stream to start of speech detected. |
Result
Print a few fields from result: the status and the formatted text of the best hypothesis
try:
# Iterate through messages returned from server
for message in stream_in:
if message.HasField('status'):
...
elif message.HasField('result'):
restype = 'partial' if message.result.result_type else 'final'
print(f'{restype}: {message.result.hypotheses[0].formatted_text}')
Print all fields
try:
# Iterate through messages returned from server
for message in stream_in:
print(message)
Output message containing the result, including the result type, the start and end times, metadata about the job, and one or more recognition hypotheses. Included in RecognitionResponse.
See Results and Formatted text for examples of results in different formats. For other examples, see Dsp, Hypothesis, and DataPack.
| Field | Type | Description |
|---|---|---|
| result_type | EnumResultType | Whether final, partial, or immutable results are returned. |
| abs_start_ms | uint32 | Start time of the audio segment that generated this result. Offset, in milliseconds, from the beginning of the audio stream. |
| abs_end_ms | uint32 | End time of the audio segment that generated this result. Offset, in milliseconds, from the beginning of the audio stream. |
| utterance_info | UtteranceInfo | Information about each sentence. |
| hypotheses | Hypothesis | Repeated. One or more recognition variations. |
| data_pack | DataPack | Data pack information. |
| notifications | Notification | List of notifications, if any. |
UtteranceInfo
Output message containing information about the recognized sentence in the result. Included in Result.
| Field | Type | Description |
|---|---|---|
| duration_ms | uint32 | Sentence duration in milliseconds. |
| clipping_duration_ms | uint32 | Milliseconds of clipping detected. |
| dropped_speech_packets | uint32 | Number of speech audio buffers discarded during processing. |
| dropped_nonspeech_packets | uint32 | Number of non-speech audio buffers discarded during processing. |
| dsp | Dsp | Digital signal processing results. |
Dsp
Dsp example including level
try:
# Iterate through messages returned from server
for message in stream_in:
if message.HasField('status'):
if message.status.details:
print(f'{message.status.code} {message.status.message} - {message.status.details}')
else:
print(f'{message.status.code} {message.status.message}')
elif message.HasField('result'):
restype = 'partial' if message.result.result_type else 'final'
print(f'{restype}: {message.result.hypotheses[0].formatted_text}')
print(f'Speech signal level: {message.result.utterance_info.dsp.level} SNR: {message.result.utterance_info.dsp.snr_estimate_db}')
Results shows speech signal level and speech-to-noise ratio for each sentence
$ ./run-python-client.sh ../audio/weather16.wav
stream ../audio/weather16.wav
100 Continue - recognition started on audio/l16;rate=16000 stream
final: There is more snow coming to the Montreal area in the next few days
Speech signal level: 20993.0 SNR: 15.0
final: We're expecting 10 cm overnight and the winds are blowing hard
Speech signal level: 18433.0 SNR: 15.0
final: Radar and satellite pictures show that we're on the western edge of the storm system as it continues to traffic further to the east
Speech signal level: 21505.0 SNR: 14.0
stream complete
200 Success
Output message containing digital signal processing results. Included in UtteranceInfo.
| Field | Type | Description |
|---|---|---|
| snr_estimate_db | float | The estimated speech-to-noise ratio. |
| level | float | Estimated speech signal level. |
| num_channels | uint32 | Number of channels. Default is 1, meaning mono audio. |
| initial_silence_ms | uint32 | Milliseconds of silence observed before start of utterance. |
| initial_energy | float | Energy feature value of first speech frame. |
| final_energy | float | Energy feature value of last speech frame. |
| mean_energy | float | Average energy feature value of utterance. |
Hypothesis
Hypothesis example including formatted_text, confidence, and whether the sentence was rejected (False means it was accepted).
try:
# Iterate through messages returned from server
for message in stream_in:
if message.HasField('status'):
if message.status.details:
print(f'{message.status.code} {message.status.message} - {message.status.details}')
else:
print(f'{message.status.code} {message.status.message}')
elif message.HasField('result'):
restype = 'partial' if message.result.result_type else 'final'
print(f'{restype}: {message.result.hypotheses[0].formatted_text}')
print(f'Average confidence: {message.result.hypotheses[0].average_confidence} Rejected? {message.result.hypotheses[0].rejected}')
Result showing formatted text lines, including abbreviations such as “10 cm”
$ ./run-python-client.sh ../audio/weather16.wav
stream ../audio/weather16.wav
100 Continue - recognition started on audio/l16;rate=16000 stream
final: There is more snow coming to the Montreal area in the next few days
Average confidence: 0.4129999876022339 Rejected? False
final: We're expecting 10 cm overnight and the winds are blowing hard
Average confidence: 0.7960000038146973 Rejected? False
final: Radar and satellite pictures show that we're on the western edge of the storm system as it continues to traffic further to the east
Average confidence: 0.6150000095367432 Rejected? False
stream complete
200 Success
Output message containing one or more proposed transcripts of the audio stream. Included in Result. Each variation has its own confidence level along with the text in two levels of formatting. See Formatted text.
| Field | Type | Description |
|---|---|---|
| confidence | float | The confidence score for the entire result, 0 to 1. |
| average_confidence | float | The confidence score for the hypothesis, 0 to 1: the average of all word confidence scores based on their duration. |
| rejected | bool | Whether the hypothesis was rejected or accepted.
The recognizer determines rejection based on an internal algorithm. If the audio input cannot be assigned to a sequence of tokens with sufficiently high probability, it is rejected. Recognition can be improved with domain LMs, wordsets, and builtins. The rejected field is returned for final results only, not for partial results. |
| formatted_text | string | Formatted text of the result, e.g. $500. Formatting is controlled by formatting schemes and options. See Formatted text. |
| minimally_formatted_text | string | Slightly formatted text of the result, e.g. Five hundred dollars. Words are spelled out, but basic capitalization and punctuation are included. See the formatting scheme, all_as_words. |
| words | Word | Repeated. One or more recognized words in the result. These are individual words in formatted_text with timestamps and confidence (if available). |
| encrypted_tokenization | string | Nuance-internal representation of the recognition result. Not returned when result originates from a grammar. |
| grammar_id | string | Identifier of the matching grammar, as grammar_0, grammar_1, etc. representing the order the grammars were provided as resources. Returned when result originates from an SRGS grammar rather than generic dictation. |
| detected_wakeup_word | string | The detected wakeup word when using a wakeup word resource in RecognitionResource. See also Wakeup words. |
Word
Output message containing one or more recognized words in the hypothesis, including the text, confidence score, and timing information. Included in Hypothesis.
| Field | Type | Description |
|---|---|---|
| text | string | The recognized word. |
| confidence | float | The confidence score of the recognized word, 0 to 1. |
| start_ms | uint32 | Start time of the word. Offset, in milliseconds, from the beginning of the current audio segment (abs_start_ms). |
| end_ms | uint32 | End time of the word. Offset, in milliseconds, from the beginning of the current audio segment (abs_start_ms). |
| silence_after_word_ms | uint32 | The amount of silence, in milliseconds, detected after the word. |
| grammar_rule | string | The grammar rule that recognized the word text. Returned when result originates from an SRGS grammar rather than generic dictation. |
DataPack
DataPack example using dp_displayed flag and an extra print line
try:
# Iterate through messages returned from server
dp_displayed = False
for message in stream_in:
if message.HasField('status'):
if message.status.details:
print(f'{message.status.code} {message.status.message} - {message.status.details}')
else:
print(f'{message.status.code} {message.status.message}')
elif message.HasField('result'):
restype = 'partial' if message.result.result_type else 'final'
if restype == 'final' and not dp_displayed:
print(f'Data pack: {message.result.data_pack.language} {message.result.data_pack.version}')
dp_displayed = True
print(f'{restype}: {message.result.hypotheses[0].formatted_text}')
Results include the language and version of the data pack
$ ./run-python-client.sh ../audio/monday_morning_16.wav
stream ../audio/monday_morning_16.wav
100 Continue - recognition started on audio/l16;rate=16000 stream
Data pack: eng-USA 4.2.0
final: It's Monday morning and the sun is shining
final: I'm getting ready to walk to the train and commute into work
final: I'll catch the 758 train from Cedar Park station
final: It will take me an hour to get into town
stream complete
200 Success
Output message containing information about the current data pack. Included in Result.
| Field | Type | Description |
|---|---|---|
| language | string | Language of the data pack loaded by Krypton. |
| topic | string | Topic of the data pack loaded by Krypton. |
| version | string | Version of the data pack loaded by Krypton. |
| id | string | Identifier string of the data pack, including nightly update information if a nightly build was loaded. |
Notification
Output message containing a notification structure. Included in Result.
| Field | Type | Description |
|---|---|---|
| code | uint32 | Notification unique code. |
| severity | EnumSeverityType | Severity of the notification. |
| message | nuance.rpc. LocalizedMessage | The notification message. |
| data | map<string, string> | Map of additional key, value pairs related to the notification. |
EnumSeverityType
Output field specifying a notification’s severity. Included in Notification.
| Name | Number | Description |
|---|---|---|
| SEVERITY_UNKNOWN | 0 | The notification has an unknown severity. Default. |
| SEVERITY_ERROR | 10 | The notification is an error message. |
| SEVERITY_WARNING | 20 | The notification is a warning message. |
| SEVERITY_INFO | 30 | The notification is an information message. |
Training API
Proto files and client stubs for Training service
└── nuance
├── asr
│ └── v1beta1
│ ├── training_pb2_grpc.py
│ ├── training_pb2.py
│ └── training.proto
└── rpc
├── error_details_pb2.py
├── error_details.proto
├── status_code_pb2.py
├── status_code.proto
├── status_pb2.py
└── status.proto
Krypton provides a set of protocol buffer (.proto) files to define a gRPC wordset training service. These files allow you to compile and manage large wordsets for use with your Krypton applications:
training.proto defines the methods and messages for working with large wordsets.
The RPC files contain status and error messages used by other Nuance APIs. See RPC status messages.
Once you have transformed the proto files into functions and classes in your programming language using gRPC tools (see gRPC setup), you can call these functions from your application to request compile and manage wordsets.
See Sample Python app: Training for scenarios in Python. For other languages, consult the gRPC and Protocol Buffers documentation.
You may use these proto files in conjunction with the other Krypton proto files described in Recognizer API.
Wordset proto file structure
The proto file defines a Training service with several RPC methods for creating and managing compiled wordsets. This shows the structure of the messages and fields for each method.

For the nuance.rpc.Status messages, see RPC status messages.
Job status vs. request status
This report on an ongoing job combines job status and request status
2021-04-05 16:41:28,369 INFO : Received response: job_status_update {
job_id: "c21b0be0-964e-11eb-9e4a-5fb8e278d1ad"
status: JOB_STATUS_PROCESSING
}
request_status {
status_code: OK
http_trans_code: 200
}
2021-04-05 16:41:28,896 INFO : new server stream count 2
2021-04-05 16:41:28,896 INFO : Received response: job_status_update {
job_id: "c21b0be0-964e-11eb-9e4a-5fb8e278d1ad"
status: JOB_STATUS_COMPLETE
}
request_status {
status_code: OK
http_trans_code: 200
}
This API includes two types of status:
Job status refers to the condition of the job that is compiling the wordset. Its values are set in JobStatus and can be JOB_STATUS_QUEUED, JOB_STATUS_PROCESSING, JOB_STATUS_COMPLETE, or JOB_STATUS_FAILED.
Request status refers to the condition of the gRPC request. Its values are set in nuance.rpc.Status and can be OK, INVALID_REQUEST, NOT_FOUND, ALREADY_EXISTS, and so on.
Training service
The Training service offers five RPC methods to compile and manage wordsets. Each method consists of a request and a response message.
| Method | Request and response | Description |
|---|---|---|
| CompileWordset AndWatch | CompileWordsetRequest WatchJobStatusResponse stream |
Submit and watch for job completion (server streaming). |
| GetWordset Metadata | GetWordsetMetadataRequest GetWordsetMetadataResponse |
Get a compiled wordset's metadata (unary). |
| DeleteWordset | DeleteWordsetRequest DeleteWordsetResponse |
Delete the compiled wordset (unary). |
For examples of using all these methods, see Sample Python app: Training.
CompileWordsetAndWatch
CompileWordsetAndWatch method consists of CompileWordsetRequest and WatchJobStatusResponse
Process flow of CompileWordsetAndWatch method
CompileWordsetAndWatch input file, flow_compilewordsetandwatch.py

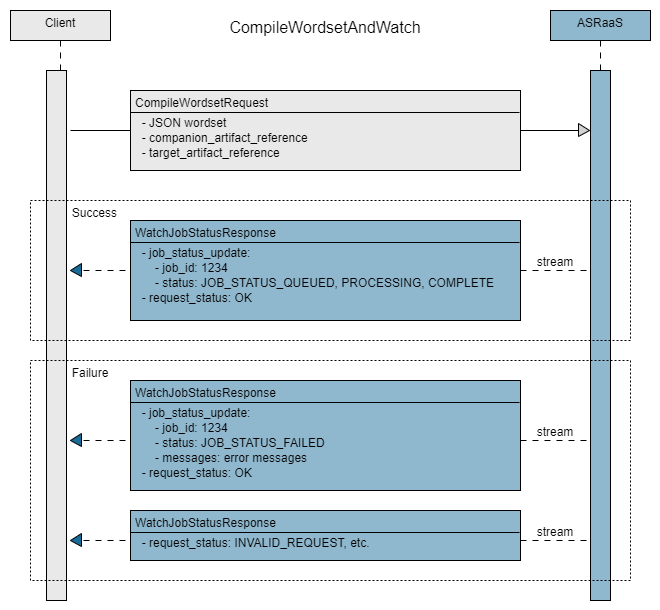
from nuance.asr.v1beta1.training_pb2 import *
list_of_requests = []
watchrequest = True
request = CompileWordsetRequest()
request.companion_artifact_reference.uri = "urn:nuance-mix:tag:model/names-places/mix.asr?=language=eng-USA"
request.target_artifact_reference.uri = "urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
request.wordset = '{"cityqa":[{"literal":"La Jolla","spoken":["la hoya","la jolla"]},{"literal":"Llanfairpwllgwyngyll","spoken":["lan vire pool guin gill"]},{"literal":"Abington Pigotts"},{"literal":"Steeple Morden"},{"literal":"Hoyland Common"},{"literal":"Cogenhoe","spoken":["cook no"]},{"literal":"Fordoun","spoken":["forden","fordoun"]},{"literal":"Llangollen","spoken":["lan goth lin","lan gollen"]},{"literal":"Auchenblae"}]}'
request.metadata['app_os'] = 'CentOS'
#Add request to list
list_of_requests.append(request)
# ---
CompileWordsetAndWatch
def send_compilewordsetandwatch_request(grpc_client, request, metadata=None):
log.info("Sending CompileWordsetAndWatch request")
metadata = []
client_span = None
train_span = None
count_stream = 0
global total_train_request
total_train_request = total_train_request + 1
global args
thread_context.num_train_request = thread_context.num_train_request + 1
if args.wsFile:
log.info("Override the inline wordset with input file [%s]" % args.wsFile)
request.wordset = open(args.wsFile, 'rb').read()
if args.meta:
with open(args.meta if type(args.meta)is str else '.metadata', 'r') as meta_file:
for n, line in enumerate(meta_file):
header, value = line.split(':', 1)
metadata.append((header.strip(), value.strip()))
if args.nmaid:
metadata.append(('x-nuance-client-id', args.nmaid))
if args.jaeger:
log.debug("Injecting Jaeger span context into request")
client_span = tracer.start_span("Client.gRPC")
train_span = tracer.start_span(
"Client.Training", child_of=client_span)
carrier = dict()
tracer.inject(train_span.context,
opentracing.propagation.Format.TEXT_MAP, carrier)
metadata.append(('uber-trace-id', carrier['uber-trace-id']))
start = time.monotonic()
log.info("Sending request: {}".format(request))
log.info("Sending metadata: {}".format(metadata))
responses = grpc_client.CompileWordsetAndWatch(request=request, metadata=metadata)
for response in responses:
count_stream = count_stream + 1
log.info("new server stream count {}".format(count_stream))
log.info("Received response: {}".format(response))
latency = time.monotonic() - start
global total_first_chunk_latency
total_first_chunk_latency = total_first_chunk_latency + latency
log.info("First chunk latency: {} seconds".format(latency))
if train_span:
train_span.finish()
if client_span:
client_span.finish()
This RPC method submits a request to compile a wordset and returns streaming messages from the server until the job completes. It consists of CompileWordsetRequest and WatchJobStatusResponse. The response is a server stream of job progress notifications, which stays alive until the end of the compilation job, followed by a final job status.
This method consists of:
CompileWordsetRequest
wordset
companion_artifact_reference (ResourceReference)
target_artifact_reference (ResourceReference)
metadata
client_data
WatchJobStatusResponse
job_status_update (JobStatusUpdate)
request_status (nuance.rpc.Status)
CompileWordsetRequest
Request to compile a wordset.
| Field | Type | Description |
|---|---|---|
| wordset | string | Mandatory. Inline wordset JSON resource, or programming-language code to read the wordset from a file. See Sample Python app: Training. The complete request message has a maximum size of 4 MB. |
| companion_artifact_reference | ResourceReference | Mandatory. URN reference to the domain LM that the wordset extends, to use during compilation. |
| target_artifact_reference | ResourceReference | Mandatory. URN reference for the compiled wordset being generated. |
| metadata | map<string,string> | Client-supplied key,value pairs to associate with the wordset being compiled. |
| client_data | map<string,string> | Client-supplied key,value pairs to inject into the logs. |
ResourceReference
Definition of an external resource: either a domain LM containing an entity that the wordset extends, or a compiled wordset. See also Wordsets.
| Field | Type | Description |
|---|---|---|
| uri | string | Mandatory. Location of the resource as a URN reference. See below and Compiled wordsets. |
| headers | map<string,string> | Optional field for internal use. |
The format of the URN reference depends on the message and resource. In these examples, the language is eng-USA.
DLM in companion_artifact_reference. The DLM must exist in the Mix environment under the specified context tag.
urn:nuance-mix:tag:model/context_tag/mix.asr?=language=eng-USAWordset in target_artifact_reference, with an application-level wordset. The context tag is either an existing tag used for DLMs or wordsets, or a new tag that will be created. The wordset name is a new name for the compiled wordset being created:
urn:nuance-mix:tag:wordset:lang/context_tag/wordset_name/eng-USA/mix.asrOr a user wordset:
urn:nuance-mix:tag:wordset:lang/context_tag/wordset_name/eng-USA/mix.asr?=user_id=
WatchJobStatusResponse
Server stream information about a compilation job in progress.
Response to CompileWordsetRequest. This response is streamed from the server, giving information about the compilation job as it progresses.
| Field | Type | Description |
|---|---|---|
| job_status_update | JobStatusUpdate | Immediate job status. |
| request_status | nuance.rpc.Status | Nuance RPC status of the request. |
WatchJobStatusResponse returns these notifications:
Job ID.
Multiple responses with JOB_STATUS_QUEUED or ~PROCESSING. The same status may be returned multiple times. Repeated notifications also keep the process alive.
Final job status (JOB_STATUS_COMPLETE or ~FAILED) with error messages when appropriate.
Final request status, either OK for successful requests, or INVALID_REQUEST, etc. for others. This status refers to the request itself, not the wordset compile job that was created. See Job status vs. request status.
Invalid requests do not create a job, so the notification stream consists only of the request status.
JobStatusUpdate
Job status update to a request.
| Field | Type | Description |
|---|---|---|
| job_id | string | The job ID, a unique identifier. |
| status | JobStatus | Job status. |
| messages | JobMessage | Repeated. Error details on job. |
JobStatus
Job status as a keyword. See Job status vs. request status.
| Name | Number | Description |
|---|---|---|
| JOB_STATUS_UNKNOWN | 0 | Job status not specified or unknown. |
| JOB_STATUS_QUEUED | 1 | Job is queued. |
| JOB_STATUS_PROCESSING | 2 | Job is processing. |
| JOB_STATUS_COMPLETE | 3 | Job is complete. |
| JOB_STATUS_FAILED | 4 | Job has failed. |
JobMessage
Message about the job in progress.
| Field | Type | Description |
|---|---|---|
| code | int32 | Message code. |
| message | string | Job message. |
| data | map<string, string> | Additional key,value pairs. |
GetWordsetMetadata
GetWordsetMetadata method consists of GetWordsetMetadataRequest and ~Response
Process flow for GetWordsetMetadata
GetWordsetMetadata input file, flow_getwordsetmetadata.py


from nuance.asr.v1beta1.training_pb2 import *
list_of_requests = []
request = GetWordsetMetadataRequest()
request.artifact_reference.uri = "urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
#Add request to list
list_of_requests.append(request)
# ---
GetWordsetMetadata
def send_getwordsetmetadata_request(grpc_client, request, metadata=None):
log.info("Sending GetWordsetMetadata request")
metadata = []
if args.meta:
with open(args.meta if type(args.meta)is str else '.metadata', 'r') as meta_file:
for n, line in enumerate(meta_file):
header, value = line.split(':', 1)
metadata.append((header.strip(), value.strip()))
if args.nmaid:
metadata.append(('x-nuance-client-id', args.nmaid))
log.info("Sending request: {}".format(request))
log.info("Sending metadata: {}".format(metadata))
response = grpc_client.GetWordsetMetadata(request=request, metadata=metadata)
log.info("Received response: {}".format(response))
This RPC method requests and returns information about a compiled wordset. This method consists of GetWordsetMetadataRequest and ~Response.
GetWordsetMetadataRequest
artifact_reference (ResourceReference)
GetWordsetMetadataResponse
metadata
request_status (nuance.rpc.Status)
GetWordsetMetadataRequest
Request for information about a compiled wordset.
| Type | Description | |
|---|---|---|
| artifact_reference | ResourceReference | Mandatory. Reference to the compiled wordset artifact. |
GetWordsetMetadataResponse
Response information about a compiled wordset.
| Field | Type | Description |
|---|---|---|
| metadata | map<string,string> | Default and client-supplied key,value pairs. |
| request_status | nuance.rpc.Status | Nuance RPC status of fetching the metadata. |
GetWordsetMetadataResponse does not return the JSON content of the wordset. It provides two types of metadata:
Custom metadata, optionally supplied by the client as metadata in CompileWordsetRequest.
Default metadata (reserved keys):
x_nuance_companion_checksum_sha256: The companion DLM, SHA256 hash in hex format.
x_nuance_wordset_content_checksum_sha256: The source wordset content, SHA256 hash in hex format.
x_nuance_compiled_wordset_checksum_sha256: The compiled wordset, SHA256 hash in hex format.
x_nuance_compiled_wordset_last_update: Date and time of last update as ISO 8601 UTC date.
DeleteWordset
DeleteWordset method consists of DeleteWordsetRequest and ~Response
Process flow for DeleteWordset
DeleteWordset input file, flow_deletewordset.py

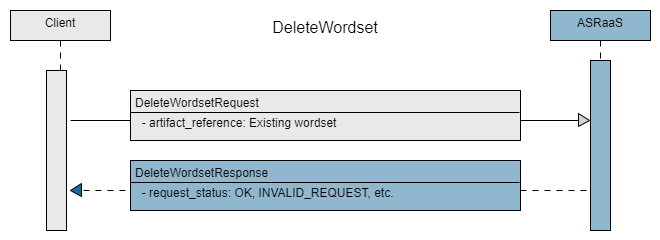
from nuance.asr.v1beta1.training_pb2 import *
list_of_requests = []
request = DeleteWordsetRequest()
request.artifact_reference.uri = "urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
#Add request to list
list_of_requests.append(request)
# ---
DeleteWordset
def send_deletewordset_request(grpc_client, request, metadata=None):
log.info("Sending DeleteWordset request")
metadata = []
if args.meta:
with open(args.meta if type(args.meta)is str else '.metadata', 'r') as meta_file:
for n, line in enumerate(meta_file):
header, value = line.split(':', 1)
metadata.append((header.strip(), value.strip()))
if args.nmaid:
metadata.append(('x-nuance-client-id', args.nmaid))
log.info("Sending request: {}".format(request))
log.info("Sending metadata: {}".format(metadata))
response = grpc_client.DeleteWordset(request=request, metadata=metadata)
log.info("Received response: {}".format(response))
This RPC method deletes a wordset. It consists of DeleteWordsetRequest and ~Response.
DeleteWordsetRequest
artifact_reference (ResourceReference)
DeleteWordsetResponse
job_status_update
job_status
DeleteWordsetRequest
Request to delete a compiled wordset.
| Field | Type | Description |
|---|---|---|
| artifact_reference | ResourceReference | Mandatory. Reference to the compiled wordset artifact. |
DeleteWordsetResponse
Response to the delete request.
| Field | Type | Description |
|---|---|---|
| request_status | nuance.rpc.Status | Nuance RPC status of deleting the wordset. |
RPC status messages
These messages are part of the nuance.rpc package referenced by other Nuance methods. They provide additional information about the requests.

nuance.rpc.Status
This reports an ongoing job, combining job status with request status
2021-04-05 16:41:28,369 INFO : Received response: job_status_update {
job_id: "c21b0be0-964e-11eb-9e4a-5fb8e278d1ad"
status: JOB_STATUS_PROCESSING
}
request_status {
status_code: OK
http_trans_code: 200
}
2021-04-05 16:41:28,896 INFO : new server stream count 2
2021-04-05 16:41:28,896 INFO : Received response: job_status_update {
job_id: "c21b0be0-964e-11eb-9e4a-5fb8e278d1ad"
status: JOB_STATUS_COMPLETE
}
request_status {
status_code: OK
http_trans_code: 200
}
This reports an error in a JSON file
2021-04-05 16:34:55,874 INFO : Received response: request_status {
status_code: BAD_REQUEST
status_sub_code: 7
http_trans_code: 400
status_message {
locale: "en-US"
message: "Invalid wordset content Unexpected token c in JSON at position 5"
message_resource_id: "7"
}
}
This reports an existing object
2021-04-05 17:37:41,977 INFO : Received response: request_status {
status_code: ALREADY_EXISTS
status_sub_code: 10
http_trans_code: 200
status_message {
locale: "en-US"
message: "Compiled wordset already available for artifact reference urn:nuance-mix:tag:wordset:lang/names-places/places-compiled-ws/eng-USA/mix.asr"
message_resource_id: "10"
}
}
Status messages for requests used by Nuance APIs. The status_code field is mandatory, all others are optional.
| Field | Type | Description |
|---|---|---|
| status_code | StatusCode | Mandatory. Status code, an enum value. |
| status_sub_code | int32 | Application-specific status sub-code. |
| http_trans_code | int32 | HTTP status code for the transcoder, if applicable. |
| request_info | RequestInfo | Information about the original request. |
| status_message | LocalizedMessage | Message providing the details of this status in a language other than English. |
| help_info | HelpInfo | Help message providing possible user actions. |
| field_violations | FieldViolation | Repeated. Set of request field violations. |
| retry_info | RetryInfo | Retry information. |
| status_details | StatusDetail | Repeated. Detailed status messages. |
nuance.rpc.StatusCode
Status codes related to requests used by Nuance APIs.
| Name | Number | Description |
|---|---|---|
| UNSPECIFIED | 0 | Unspecified status. |
| OK | 1 | Success. |
| BAD_REQUEST | 2 | Invalid message type: the server cannot understand the request. |
| INVALID_REQUEST | 3 | The request has an invalid value, is missing a mandatory field, etc. |
| CANCELLED_CLIENT | 4 | Operation terminated by client. The remote system may have changed. |
| CANCELLED_SERVER | 5 | Operation terminated by server. The remote system may have changed. |
| DEADLINE_EXCEEDED | 6 | The deadline set for the operation has expired. |
| NOT_AUTHORIZED | 7 | The client does not have authorization to perform the operation. |
| PERMISSION_DENIED | 8 | The client does not have authorization to perform the operation on the requested entities. |
| NOT_FOUND | 9 | The requested entity was not found. |
| ALREADY_EXISTS | 10 | Cannot create entity as it already exists. |
| NOT_IMPLEMENTED | 11 | Unsupported operation or parameter, e.g. an unsupported media type. |
| UNKNOWN | 15 | Result does not map to any defined status. Other response values may provide request-specific additional information. |
| The following status codes are less frequently used. | ||
| TOO_LARGE | 51 | A field is too large to be processed due to technical limitations e.g. a large audio or other binary block. For arbitrary limitations (e.g. name must be n characters or less), use INVALID_REQUEST. |
| BUSY | 52 | The server understood the request but could not process it due to lack of resources. Retry the request as is later. |
| OBSOLETE | 53 | A message type in the request is no longer supported. |
| RATE_EXCEEDED | 54 | Similar to BUSY. The client has exceeded the limit of operations per time unit. Retry request as is later. |
| QUOTA_EXCEEDED | 55 | The client has exceeded quotas related to licensing or payment. See your client representative for additional quotas. |
| INTERNAL_ERROR | 56 | An internal system error occurred while processing the request. |
nuance.rpc.RequestInfo
Information about the request that resulted in an error. This message is particularly useful in streaming scenarios where the correlation between the request and response is not so obvious.
| Field | Type | Description |
|---|---|---|
| request_id | string | Identifier of the original request, for example, its OpenTracing id. |
| request_data | string | Relevant free format data from the original request, for troubleshooting. |
| additional_ request_data | map<string, string> | Map of key,value pairs of free format data from the request. |
nuance.rpc.LocalizedMessage
A help message in a language other than American English. The default locale is provided by the server, for example the browser's preferred language or a user-specific locale.
All Nuance gRPC APIs that want the server to provide localized errors must accept the HTTP "Accept-Language" header or application-specific language settings, if supported.
| Field | Type | Description |
|---|---|---|
| locale | string | The locale as xx-XX, e.g. en-US, fr-CH, es-MX, per the specification bcp47.txt. Default is provided by the server. |
| message | string | The message text in the local specified. |
| message_resource_id | string | A message identifier, allowing related messages to be provided if needed. |
nuance.rpc.HelpInfo
A reference to a help document that may be shown to end users to allow them to take action based on the error or status response. For example, if the request contained a numerical value that is out of range, this message may point to the documentation that states the valid range.
| Field | Type | Description |
|---|---|---|
| links | Hyperlink | Repeated. Set of hypertext links related to the context of the enclosing message. |
nuance.rpc.Hyperlink
Details about the hypertext link containing information related to the message.
| Field | Type | Description |
|---|---|---|
| description | Localized Message | A description of the link in a specific language (locale). By default, the server handling the URL manages language selection and detection. |
| url | string | The URL to offer to the client, containing help information. If a description is present, this URL should use (or offer) the same locale. |
nuance.rpc.FieldViolation
Information about a request field or fields containing errors.
| Field | Type | Description |
|---|---|---|
| field | string | The name of the request field in violation as package.type[.type].field. |
| rel_field | string | Repeated. Repeated. The names of related fields in violation as package.type[.type].field. |
| user_message | Localized Message | An error message in a language other than English. |
| message | string | An error message in American English. |
| invalid_value | string | The invalid value of the field in violation. (Convert non-string data types to string.) |
| violation | Violation Type | The reason (enum) a field is invalid. Can be used for automated error handling by the client. |
nuance.rpc.ViolationType
The error type of the request field, as a keyword.
| Name | Number | Description |
|---|---|---|
| MANDATORY_FIELD_MISSING | 0 | A required field was not provided. |
| FIELD_CONFLICT | 1 | A field is invalid due to the value of another field. |
| OUT_OF_RANGE | 2 | A field value is outside the specified range. |
| INVALID_FORMAT | 3 | A field value is not in the correct format. |
| TOO_SHORT | 4 | A text field value is too short. |
| TOO_LONG | 5 | A text field value is too long. |
| OTHER | 64 | Violation type is not otherwise listed. |
| UNSPECIFIED | 99 | Violation type was not set. |
nuance.rpc.RetryInfo
How quickly clients may retry the request for requests that allow retries. Failure to respect this delay may indicate a misbehaving client.
| Field | Type | Description |
|---|---|---|
| retry_delay_ms | int32 | Clients must wait at least this long between retrying the same request. |
nuance.rpc.StatusDetail
A status message may have additional details, usually a list of underlying causes of an error. In contrast to field violations, which point to the fields in the original request, status details are not usually directly connected with the request parameters.
| Field | Type | Description |
|---|---|---|
| message | string | The message text in American English. |
| user_message | LocalizedMessage | The message text in a language other than English. |
| extras | map<string,string> | Map of key,value pairs of additional application-specific information. |
Scalar value types
The data types in the proto files are mapped to equivalent types in the generated client stub files.
Change log
2022-09-06
The following items were clarified in this release:
In RecognitionResource, the weight_value field has an effective default of 0.25. It takes its default from weight_enum, which is MEDIUM or 0.25.
When you reference a DLM in a recognition request, the language and topic in the request must match the DLM’s. See Domain LMs - Topics in request and DLM.
2022-03-30
These features were added:
The wakeup word feature has been modified as follows. See Wakeup words for details.
Always return detected_wakeup_word parameter:
When Krypton recognizes a wakeup word, detected_wakeup_word is always included in the results, reporting the wakeup word spoken by the user. Previously, this result field was omitted when the recognition flag, filter_wakeup_word, was True.Include WuW in ASR hypotheses when WuW only is spoken:
When the input consists of a wakeup word only, it is always included in the partial and final results, even when filter_wakeup_word is True.Additional guidance was added regarding the format of URNs. See URN format.
Please note that the Training API is available only in specific geographies. See Training API.
2022-01-12
A new formatting option was added for Japanese: names_as_katakana. See Reference topics - Formatting options.
2021-10-21
The following features were added:
When wakeup words are enabled, a new result field, detected_wakeup_word, reports the wakeup word spoken by the user. See Wakeup words.
The result.proto file is updated with this new field. If you wish to use the feature, download the proto zip file and extract the updated file. See gRPC setup.
2021-07-21
The recognition parameter, topic, is mandatory, case-sensitive, and uppercase. See RecognitionParameters.
2021-07-07
The description of the recognition flag, suppress_call_recording, was updated. See RecognitionFlags.
2021-04-09
Several features were added to the software:
Support for wakeup words, and the ability to filter them from final results. See Wakeup words.
A new protocol for compiling wordsets and storing them on the Mix platform. See Training API and Sample Python app: Training.
New RPC status messages in a proto package, which are used by both the existing Recognizer API and the new Training API. See RPC status messages.
The new protocol and status messages require new proto files and different structure for the proto and stub files. See gRPC setup.
2021-03-31
The Reference topics - Results section was expanded to include more result scenarios, including an example of requesting all possible result fields.
2021-02-17
The RecognitionResponse section was updated to include more examples of responses, especially Dsp, Hypothesis, and DataPack.
2021-01-20
The earlier protocols, v1beta1 and v1beta2, were removed from the software and documentation and are no longer supported.
2021-01-13
The Reference - Formatted text section was updated to include:
A new formatting scheme, all_as_katakana, available in Japanese data packs.
Japanese options, which describes how to combine two formatting options for displaying numbers in Japanese.
2020-12-21
- The CLIENT_ID example was updated to show new Mix syntax.
2020-12-14
Three new fields were added to the proto files:
mask_load_failures is available for individual resources, in RecognitionResource - ResourceReference.
allow_zero_base_lm_weight is a new recognition flag that lets you give a DLM 100% of the resource weight.
suppress_initial_capitalization is a recognition flag that allows sentences to start with a lower-case character.
The sample Python app was updated to check for stereo audio files, which are not supported.
2020-10-27
These documentation changes were made:
Go and Java examples were removed, keeping updated Python examples.
Additional information was added about wordset spoken forms. See Reference topics - Wordsets.
2020-06-29
A new section was added to the result.proto file: see DataPack.
2020-04-30
The proto files were renamed from nuance_asr*.proto to:
- recognizer.proto
- resource.proto
- result.proto
These proto files are available in the zip file, nuance_asr_proto_files_v1.zip. The content of the files remains the same with the exception of new Java options referenced in recognizer.proto:
option java_multiple_files = true;
option java_package = "com.nuance.rpc.asr.v1";
option java_outer_classname = "RecognizerProto";
2020-03-31
The fields names and data types in the v1 protocol are aligned with other Nuance as a service engines. See Upgrading to v1 for instructions on adjusting your applications to the latest protocol. The changes made since v1beta2 are:
URN format changed:
urn:nuance:mix/<language>/<context_tag>/mix.asr →
urn:nuance-mix:tag:model/<context_tag>/mix.asr?=language=<language>See ResourceReference. The old format is supported but deprecated.
Fields renamed: output_rate_hz → decode_rate_hz, snr_estimate → snr_estimate_db
Field types changed: speech_detection_sensitivity, confidence, and average_confidence: uint32 → float, values from 0 to 1
Field renamed and type changed: stereo (bool) → num_channels (uint32)
Fields replaced: max_age, max_stale, min_fresh, and cookies → header (map
Field removed: RecognitionResponse - cookies
New information was added about timer settings and interaction: see Timers.
The status codes were updated to clarify the notion of rejection: see Status messages and codes.
A new resource type, SETTINGS, was added, allowing you to set the data pack version. See ResourceReference.
2020-02-19
These changes were made to the ASRaaS software and documentation:
- Speaker profiles are supported as URN references as part of speaker dependent acoustic model adaptation.
- Examples were added to the documentation for Java.
2020-01-22
These changes were made to the ASRaaS gRPC software and documentation since the last Beta release:
- Smart routing: The Krypton ASR service, available from a separate URL, can handle requests in all languages supported by Mix.
- Examples were added to the documentation for the Go programming language.
2019-12-18
The protocol was updated to v1beta2, with these changes:
- RecognizeXxx → RecognitionXxx: The proto file methods RecognizeRequest, RecognizeResponse, and RecognizeInitMessage were renamed RecognitionRequest, RecognitionResponse, and RecognitionInitMessage.
- The Dsp - initial_silence field was renamed initial_silence_ms.
- Locale codes for the RecognitionParameters - language field were changed from xxx-XXX (for example, eng-USA) to xx-XX (en-US).
- The RecognitionResource - reuse field (LOW_REUSE, HIGH_REUSE) applies to wordsets as well as DLMs, meaning both types of resources can be used for multiple recognition turns.
- The AudioFormat - opus field (representing Ogg Opus) was replaced with opus (for raw Opus) and ogg_opus for Ogg-encapsulated Opus audio.
2019-11-15
Below are changes made to the ASRaaS gRPC API documentation since the initial Beta release:
- Changed the documentation structure to include the API version in the URL.
- Added Prerequisites from Mix section.
- Added a sequence flow diagram.
- Added more information on how to set up a token.
- Added a sample Go app along with the existing sample python app.
- Added an alternative way for declaring inline wordsets. See Wordsets: inline or read from file.